Modern Data Lake with MinIO : Part 1

Modern data lakes are now built on cloud storage, helping organizations leverage the scale and economics of object storage, while simplifying overall data storage and analysis flow.
In the first part of this two post series, we’ll take a look at how object storage is different from other storage approaches and why it makes sense to leverage object storage like Minio for data lakes.
What is object storage?
Object storage generally refers to the way in which the platforms organises units of storage, called objects. Every object generally consists of three things:
- The data itself. The data can be anything you want to store, from a family photo to a 400,000-page manual for building a rocket.
- An expandable amount of metadata. The metadata is defined by whoever creates the object storage; it contains contextual information about what the data is, what it should be used for, its confidentiality, or anything else that is relevant to the way in which the data should be used.
- A globally unique identifier. The identifier is an address given to the object, so it can be found over a distributed system. This way, it’s possible to find the data without having to know its physical location (which could exist within different parts of a data centre or different parts of the world).
Block storage vs object storage
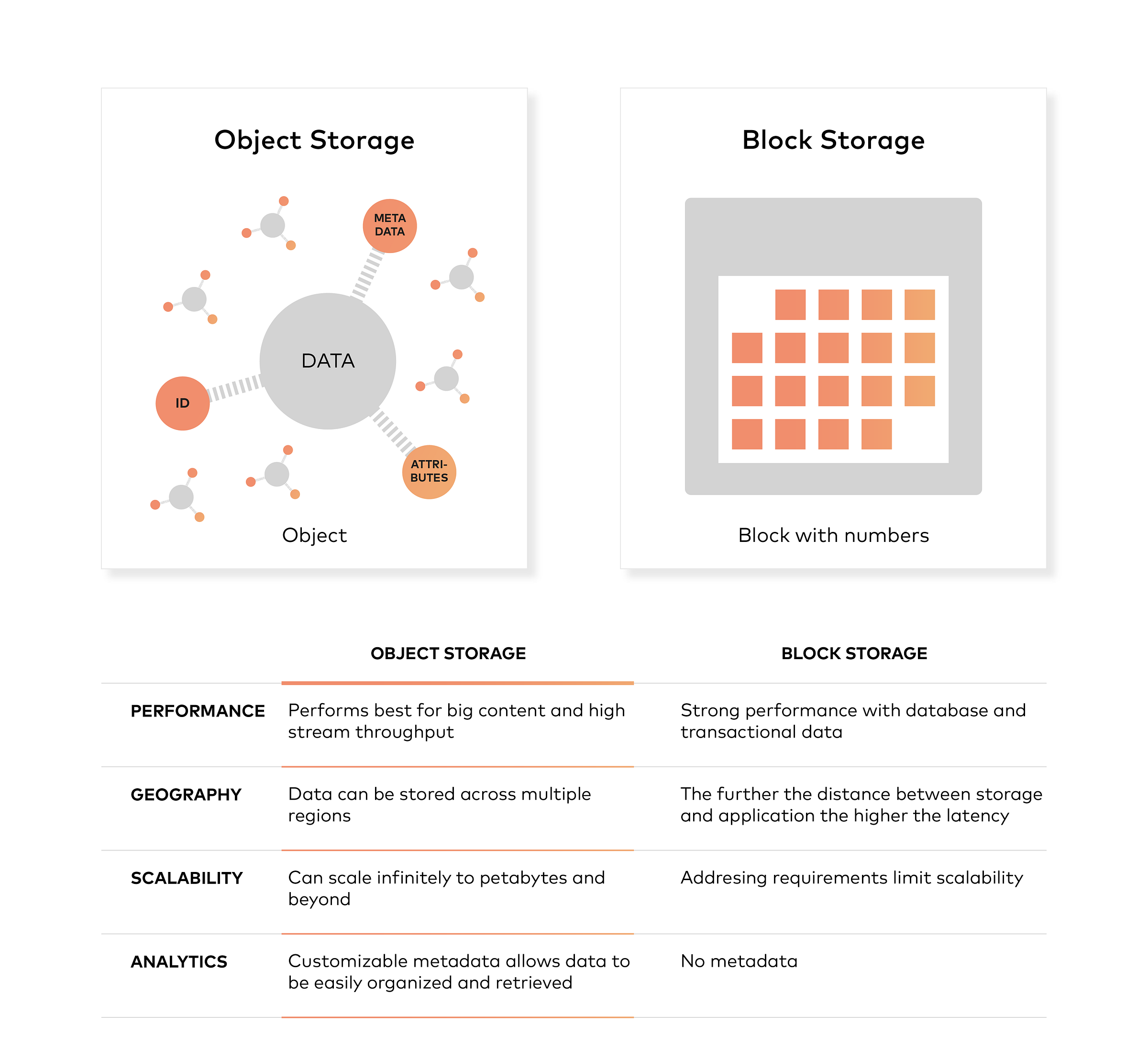
Object storage, unlike block storage, doesn’t split files up into raw blocks of data. Instead, data is stored as an object that contains the actual file data, metadata, identified by a unique identifier. Note that metadata can include any text information about the object.
Modern enterprise data centre is increasingly looking like private cloud, with object storage as the de facto storage. Object storage provides better economy at scale, ensures data is available across the world, in a highly available and highly durable manner.
Why is object storage is relevant?
Hadoop was once the dominant choice for data lakes. But in today’s fast-moving world of technology, there’s already a modern approach in town. Modern data lakes are based on object storage, with tools like Apache Spark, Presto, Tensorflow being used for advanced analytics and machine learning.
Let’s try to look back and understand how things have changed. Hadoop arose in the early 2000s and became massively popular in the last five years or so. In fact, because many companies committed to open source, most of the first big data projects five or six years ago were based on Hadoop.
Simply put, you can think of Hadoop as having two main capabilities:
- Distributed file system (HDFS) to persist data.
- Processing framework (MapReduce) that enables you to process all that data in parallel.
Increasingly, organisations started wanting to work with all of their data and not just some of it. And as a result of that, Hadoop became popular because of its ability to store and process new data sources, including system logs, click streams, and sensor- and machine-generated data.
Around 2008 or 2009, this was a game changer. At that time, Hadoop made perfect sense for the primary design goal of enabling you to build an on-premises cluster with commodity hardware to store and process this new data cheaply.
It was the right choice for the time — but it isn’t the right choice today.
Spark emerges
The good thing about open source is that it’s always evolving. The bad thing about open source is that it’s always evolving too.
What I mean is that there’s a bit of a game of catch-up you have to play, as the newest, biggest, best new projects come rolling out. So let’s take a look at what’s happening now.
Over the last few years, a newer framework than MapReduce emerged: Apache Spark. Conceptually, it’s similar to MapReduce. But the key difference is that it’s optimized to work with data in memory rather than disk. And this, of course, means that algorithms run on Spark will be faster, often dramatically so.
In fact, if you’re starting a new big data project today and don’t have a compelling requirement to interoperate with legacy Hadoop or MapReduce applications, then you should be using Spark. You’ll still need to persist the data and since Spark has been bundled with many Hadoop distributions, most on-premises clusters have used HDFS. That works, but with the rise of the cloud, there’s a better approach to persisting your data: object storage.
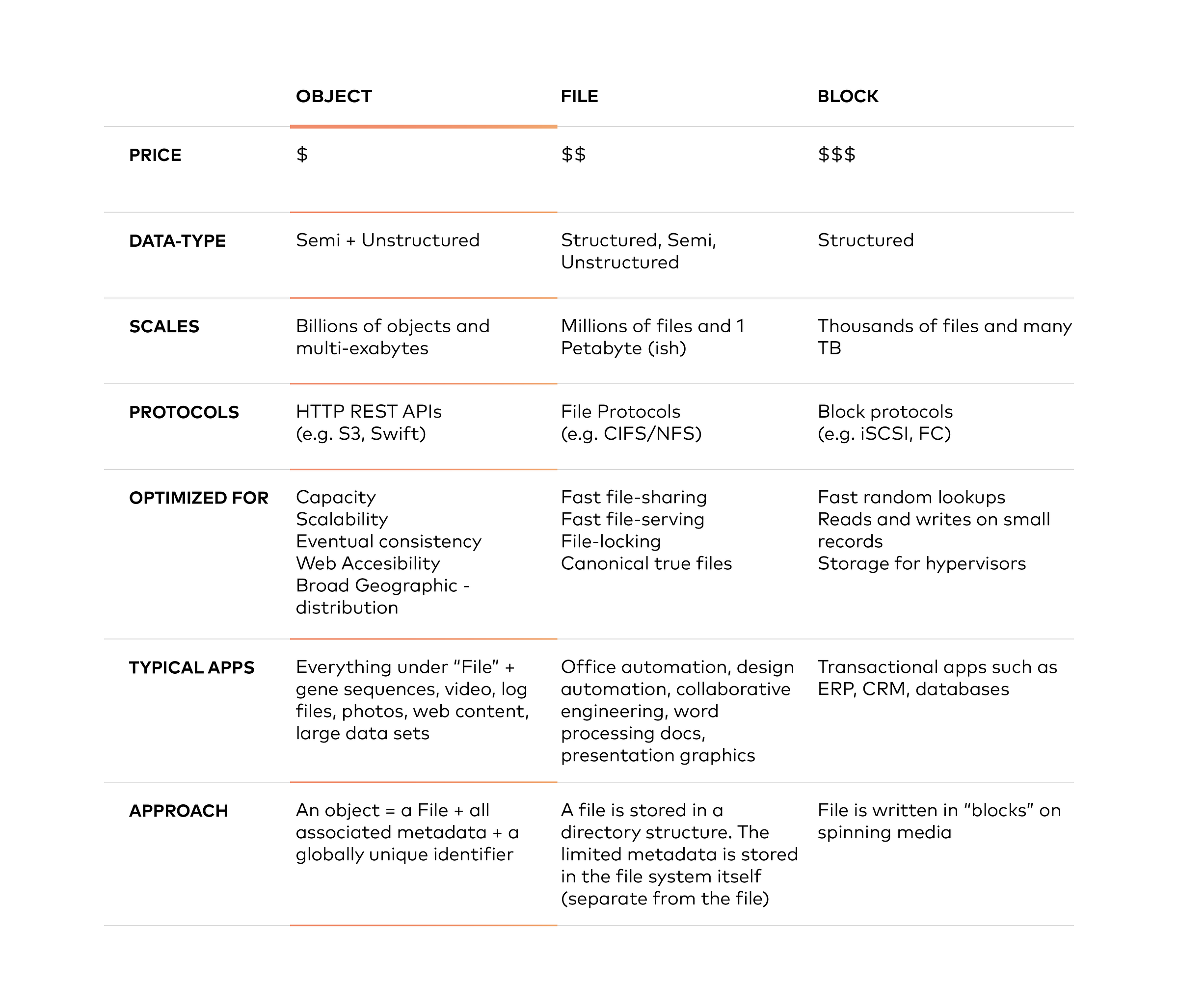
Object storage differs from file storage and block storage in that it keeps data in an “object” versus a block to make up a file. Metadata is associated to that file which eliminates the need for the hierarchical structure used in file storage — there is no limit to the amount of metadata that can be used. Everything is placed into a flat address space, which is easily scalable.
Object storage offers multiple advantages
Essentially, object storage performs very well for big content and high stream throughput. It allows data to be stored across multiple regions, it scales infinitely to petabytes and beyond, and it offers customizable metadata to aid with retrieving files.
Many companies, especially those running a private cloud environment, look at object stores as a long-term repository for massive, unstructured data that needs to be kept for compliance reasons.
But it’s not just data for compliance reasons. Companies use object storage to store photos on Facebook, songs on Spotify, and files in Dropbox.
The factor that likely makes most people’s eyes light up is the cost. The cost of bulk storage for object store is much less than the block storage you would need for HDFS. Depending upon where you shop around, you can find that object storage costs about 1/3 to 1/5 as much as block storage (remember, HDFS requires block storage). This means that storing the same amount of data in HDFS could be three to five times as expensive as putting it in object storage.
So, Spark is a faster framework than MapReduce, and object storage is cheaper than HDFS with its block storage requirement. But let’s stop looking at those two components in isolation and look at the new architecture as a whole.
The Benefits of combining object storage and Spark
What we recommend especially, is building a data lake in the cloud based on object storage and Spark. This combination is faster, more flexible and lower cost than a Hadoop-based data lake. Let’s explain this more.
Combining object storage in the cloud with Spark is more elastic than your typical Hadoop/MapReduce configuration. If you’ve ever tried to add and subtract nodes to a Hadoop cluster, you’ll know what I mean. It can be done but it’s not easy, while that same task is trivial in the cloud.
But there’s another aspect of elasticity. With Hadoop if you want to add more storage, you do so by adding more nodes (with compute). If you need more storage, you’re going to get more compute whether you need it or not.
With the object storage architecture, it’s different. If you need more compute, you can spin up a new Spark cluster and leave your storage alone. If you’ve just acquired many terabytes of new data, then just expand your object storage. In the cloud, compute and storage aren’t just elastic. They’re independently elastic. And that’s good, because your needs for compute and storage are also independently elastic.
What can you gain with object storage and Spark?
Business Agility: All of this means that your performance can improve. You can spin up many different compute clusters according to your needs. A cluster with lots of RAM, heavy-duty general-purpose compute, or GPUs for machine learning — you can do all of this as needed and all at the same time.
By tailoring your cluster to your compute needs, you can get results more quickly. When you’re not using the cluster, you can turn it off so you’re not paying for it.
Use object storage to become the persistent storage repository for the data in your data lake. On the cloud, you’ll only pay for the amount of data you have stored, and you can add or remove data whenever you want.
The practical effect of this newfound flexibility in allocating and using resources is greater agility for the business. When a new requirement arises, you can spin up independent clusters to meet that need. If another department wants to make use of your data that’s also possible because all of those clusters are independent.
Stability and Reliability: Operating a stable and reliable Hadoop cluster over an extended period of time delivers more than its share of complexity.
If you have an on-premise solution, upgrading your cluster typically means taking the whole cluster down and upgrading everything before bringing it up again. But doing so means you’re without access to that cluster while that’s happening, which could be a very long time if you run into difficulties. And when you bring it back up again, you might find new issues.
Rolling upgrades (node by node) are possible, but they’re still a very difficult process. So, it’s not widely recommended. Not just upgrades and patches, running and tuning a Hadoop cluster potentially involves adjusting as many as 500 different parameters.
One way to address this kind of problem is through automation.
But the cloud gives you another option. Fully managed Spark and object storage services can do all that work for you. Backup, replication, patching, upgrades, tuning, all outsourced.
In the cloud, the responsibility for stability and reliability is shifted from your IT department to the cloud vendor, whether it is private cloud or public.
Lowered TCO: Shifting the work of managing your object storage/Spark configuration to the cloud has another advantage too. You’re essentially outsourcing the storage management part of the work to a vendor. It’s a way to keep your employees engaged and working on exciting projects while saving on costs and contributing to a lowered TCO.
The lower TCO for this new architecture is about more than reducing labor costs, important though that is. Remember that object storage is cheaper than the block storage required by HDFS. Independent elastic scaling really does mean paying for what you use.
In essence
We boil down the advantages of this new data lake architecture built on object storage and Spark to three:
- Increased business agility
- More stability and reliability
- Lowered total cost of ownership
In the next and final post of this series, we’ll learn about object storage architecture in general and then see how to integrate Minio object store with tools like Apache Spark and Presto to simplify data flows across the organization.






