Data Storage Optimization Myths: Deduplication vs Compression

A lot of vendors offer compression and deduplication as a feature of their storage solutions. We critically evaluate these claims by looking at the two methods used to reduce the raw disk usage.
Data Compression
Compression in overall terms, gets its benefit from reducing redundancy in the data you upload. This means that repeated or otherwise predictable data can be reduced in size. As data comes in as a stream, the previous data serves as a context that can be used as a reference. If the incoming data doesn’t use all byte values (0->255) in an equal amount, this can also be used for typically minor compression gains.
Data Compression Challenges
The speed of a compression is crucial for all operations. This means both compression and decompression speed. If either is limited, that is a big enough issue to not want compression, even if it saves some space. So all compression algorithms are a tradeoff between speed and efficiency.
Compression efficiency will typically approach a “maximum”, at which point gains are very expensive in terms of computation. There is no “middle-out” compression that magically increases the compression. In most cases compression can be increased with domain-specific algorithms that have some sort of prior knowledge about the data. But in most cases applications are already taking advantage of this and apply it when outputting the data.
A second thing to keep in mind is seeking. S3 compatible object stores must support seeking to satisfy HTTP Range requests that start inside the object. For almost all compression algorithms seeking must be handled separately. A stream of compressed data is mostly not seekable, and some must read and fully decompress from the very first byte to the first requested byte. This means that in order to have efficient seeking, the input must be split into separate blocks.

Doing independent blocks means that context will have to reset between each block and an index of each block will need to be kept. Each of these will reduce the maximum possible compression.
Data Deduplication
Deduplication may sound very much like compression, but it operates on a higher level and deduplicates larger blocks of data, typically across a complete namespace.
Deduplication divides an input into blocks, creates a hash for each of them. If it re-encounters a block with the same hash, it simply inserts a reference to the previous block. If you consider an input, it will look like this:
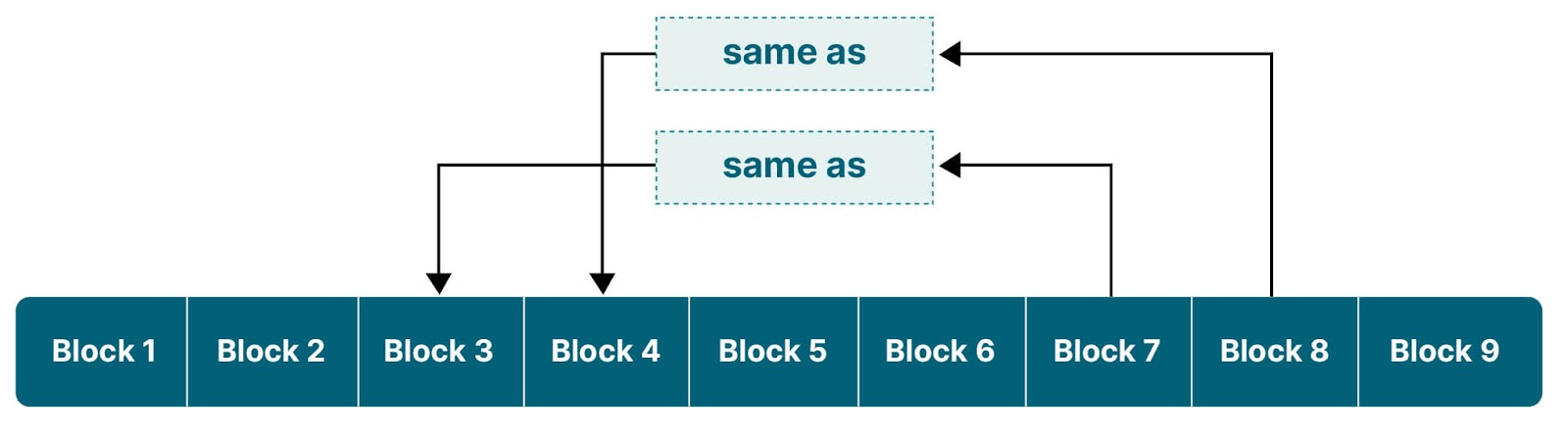
While this may sound like ordinary compression, it has some key differences. First of all, only complete blocks are checked. In compression like deflate, snappy, etc, you are looking for matches for each individual byte, in a limited window, for example 32KB-1MB. Deduplication will work across gigabytes and even terabytes of data.
In practical terms each block is run through a hash function, which provides a strong enough hash that you do not expect to be prone to collisions. Each block is then written to disk, so it can be located by its hash value.
An object stream is therefore a string of hashes:
[xxxx][yyyy][zzzz][vvvv][wwww]...
To read back the data each block is then retrieved and returned in order. Since blocks are unique they can be shared between different objects. This means that if the same data is uploaded multiple times it will only need to store the hash for the second upload, since the data is already contained in the block on disk.
Data Deduplication Challenges
Deduplication has some challenges. A primary challenge is that reads and writes will always be split into smaller blocks. This means that spinning disks go from sequential read/write speed to random IO speed. Typically the difference between random and sequential reads are about an order of magnitude, plus any time to open each file if a filesystem is underneath.
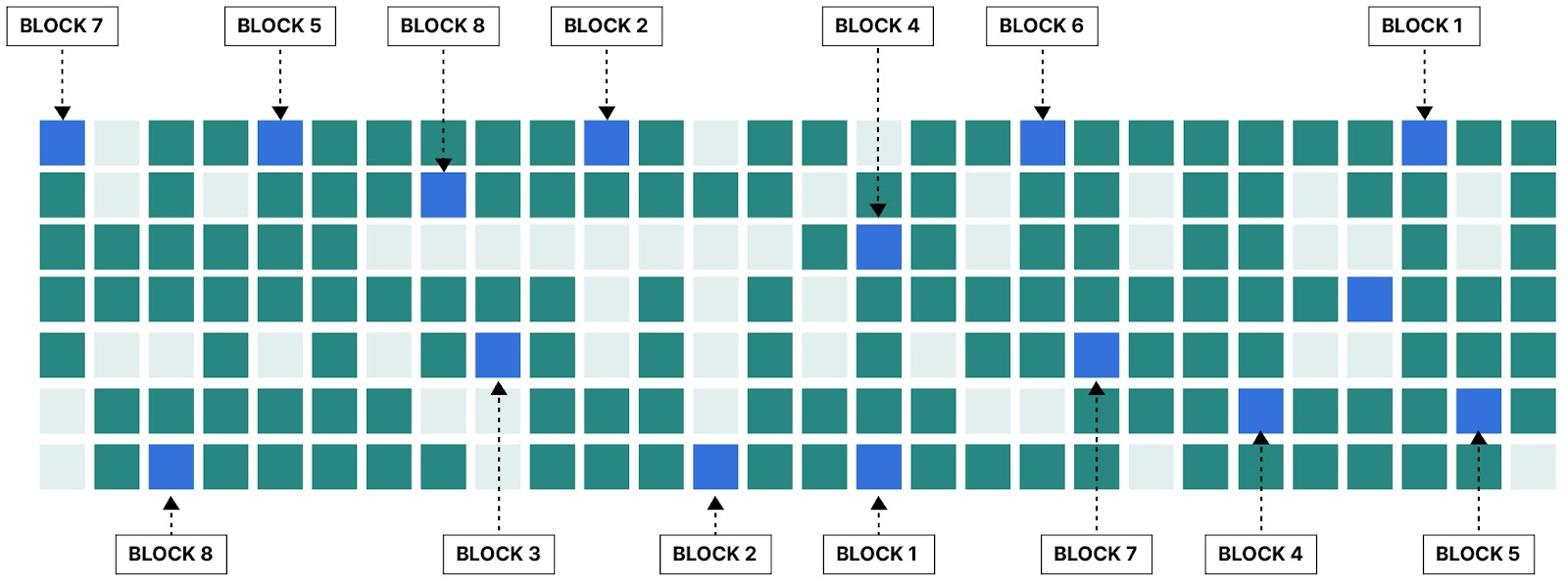
There is a tradeoff between the efficiency and the block size. Smaller blocks allow for more matches to be made for data with only a few differences - but will result in smaller IO operations and streaming will be much below what the hardware can supply. Surprisingly even for NVME drives have overhead for each unique write. Each block will also incur a fixed hash size overhead - typically at least 32 bytes.
A second major hurdle is that deduplication requires keeping track of references to each block. This can be done in a variety of ways, but all methods require a database that keeps references and maintains locks so new objects cannot reference them while deletes are going on.
Either way expensive housekeeping is required - and a delete operation explodes into many, many individual operations for the data to actually be purged. Typically this cleanup is ignored by benchmarks, so it is only something that is found out long after the system has been deployed.
Finally deduplication can lead to subtle data leaks. Deduplication will by its nature allow you to compare already uploaded data to arbitrary data. It requires very careful engineering to not leak whether a block of data was deduplicated or not. Verifying that this is not the case requires a very careful audit.
Data Compression + Data Deduplication
Combining compression and deduplication leads to interesting challenges.
First of all the deduplication forces a fixed compression block size. Compression of deduplicated blocks cannot reference prior data, since that will be different for each block. This means that compression will be limited to compression within the deduplicated block. This is however similar to the indexes needed for seeking.
Since deduplicated blocks are also stored independently, this also means that in almost all cases the variable output size of the compressed blocks will lead to inefficiencies in storage for each block, typically rounding output size up to the nearest 4KB size, effectively wasting storage for every block. If the blocks are tightly packed this will lead to very fragmented cleanup operations where performance will degrade significantly over time.
This means that for effective compression the deduplicated blocks must be reasonably large to not incur too much overhead when stored. This means that, in reality, deduplication will only deduplicate data that is completely a duplicate or where large chunks are duplicated at the exact same block offset as in other files. In reality this means that only exact duplicates will be deduplicated.
Data Deduplication + Data Encryption
Encrypting data with deduplication opens up new challenges. First of all we will need to compare if incoming data matches the encrypted data we have on disk. This will always compromise security.
First of all, having hashes of un-encrypted data is a big no-no, since you leak information about your stored data. While we cannot be sure, we don’t assume anyone actually does this, but you should always check with your storage vendor.
Then you can either encrypt the hash or store a hash of the encrypted data. In both cases this means that you will have to encrypt your entire namespace with the same key. While key rotation would be possible with encrypted hashes, it would be unfeasibly slow since billions of hashes would need to be rotated at once and stored back in a searchable structure.
A more fundamental problem is that deduplicating data inevitably will lead to side-channel attacks. For deduplication to be effective, you want the namespace to be as big as possible. But if you share a namespace with an attacker a block that is deduplicated will almost certainly have a different response time than a non-deduplicated block. This means that it is very likely an attacker can confirm if an object with given content exists in the namespace.
As a result, object storage vendors who claim they are combining deduplication and compression are likely playing fast and loose with the truth. They could not offer a performant or secure system if they did these things. We are open to education here, but we are fairly confident in our assessment.
Related: Enterprise Object Storage Encryption
The MinIO Approach to Data Storage Optimization
Deduplication in an architecture is a fundamental decision. It is not feasible to have deduplication as an ”opt-in”, unless you want two fully independent code paths at the base of your system. MinIO has decided not to implement deduplication for all of the reasons given above. It would simply be too big of a negative tradeoff for pure speed of storage.
We keep object parts as a single continuous stream on disk, meaning that readback of objects are sequential reads.
We have however implemented Transparent Data Compression. This is designed to be extremely fast and safe to use in all scenarios. We implement a seek index that allows starting decompression at any 1MB boundary. This means that seeking typically has less than a millisecond of decompression with only a small amount of extra data read.
We optimize speed so it is feasible to saturate even the fastest NICs out there with a single stream, both on upload and download.
Stronger compression can of course be applied on the client side when feasible. This will also make both the upload and download take less bandwidth, so whenever feasible we recommend that approach.
Still want data deduplication?
Deduplication can be valuable, but it is our opinion that it only belongs on the application level, and only when you can expect gains to be had. Workloads like full image backups typically only sees a small percentage of blocks change between each backup
This also has the added benefit that you don’t need to transfer duplicated blocks to the server in the first place. Applications also have the option to keep an index of blocks, so deduplication can be done without having to check if blocks exist remotely.
Even more advanced applications could utilize zip archives for bulk upload of blocks, which would also simplify cleanup of outdated data by ignoring old archives and re-adding referenced blocks after a n-day cycle has passed.
Conclusion
MinIO is dedicated to prove the best performance we can squeeze from your hardware. Therefore we offer high throughput compression that can outperform your NIC speed and do not employ any deduplication on the server side. We strongly believe that this is the correct approach for getting the most of your hardware investment. We believe that inflating raw storage numbers with theoretical deduplication and compression numbers is disingenuous, and you should call out any vendor that does this.
Install MinIO, read more about Transparent Data Compression. If you have questions on dubious vendor claims, reach out to our people on sales@min.io - If you have questions on compression and how to configure it be sure to reach out to us on Slack!






