No More Default Rebalancing of Object Storage!

Please note that this blog post was replaced by https://blog.min.io/minio-adds-manual-rebalancing/. Please consult that post for our current thinking around rebalancing object storage.
MinIO doesn’t employ traditional rebalancing techniques to manage data or add capacity. Like everything we have done - we took a hard look at this “conventional wisdom” and determined that rebalancing as a default operation wouldn’t be effective in the context of an object storage specific implementation that needed to deliver performance, scale and, most importantly, performance at scale. As a result, we approach the problem differently through the addition of server pools and erasure sets. This post talks about the tradeoff of rebalancing by default versus weighted writes and rebalancing on demand, and describes our approach to building scalable systems that grow quickly and efficiently without downtime.
The Double Edged Sword of Rebalancing
Traditional distributed object storage systems balance data by spreading it across nodes in a cluster. They accomplish this through policies written to optimize capacity and/or performance based on characteristics of objects, usage and resources. The cluster balances objects across nodes as they are written in order to conform to policy. One way to think about balancing is that it is like striping, except that striping is across an array of disks and balancing is across nodes in a cluster.
At times, rebalancing is needed. Whereas balancing takes place as objects are written to the cluster, rebalancing operates on as many objects as fast as it can and is therefore a much more resource-intensive and painful process. Rebalancing becomes necessary when nodes or media are added or taken out of service and when policy changes. New resources aren’t available to the system until objects can be rebalanced onto them. Rebalancing is a resource-intensive series of tasks that push cluster CPU, memory, network and physical storage to their limits as data gets pushed from node to node and disk to disk.
Rebalancing a massive distributed storage system can be a nightmare. There’s nothing worse than adding a storage node and watching helplessly as user response time increases while the system taxes its own resources rebalancing to include the new node. Some systems are even smart enough to rebalance really slowly or during off hours to minimize the overall performance impact of the task, but who has weeks to bring a new node into service?
One frequently used alternative is to implement a storage system with excess capacity. This wastes budget and the even more precious commodity of data center space as nodes sit unused in racks for months or years. Sadly, when the additional storage is needed, the servers and physical storage devices may no longer be the fastest or the densest available.
Automatic rebalancing introduces complexities to deployment, operations and management that increase with data volume. Rebalancing a petabyte is far more demanding than a terabyte, and given the inevitability of data growth, object storage systems that can’t handle tens of petabytes or more are destined to fail. Rebalancing doesn’t just affect performance - moving many objects between many nodes across a network can be risky. Devices and components fail and that often leads to data loss or corruption. Object storage that lacks the ability to rebalance on a schedule could quite possibly cripple itself.
Freedom to Scale
MinIO considered these tradeoffs when we designed our object storage and determined we needed a better way to scale.
Let’s take a look at MinIO’s architecture, especially at the foundational erasure coding. Erasure coding is similar to RAID (remember I mentioned striping earlier) in that it splits objects into data and parity blocks and distributes them across drives and servers (hardware and in the case of Kubernetes software nodes) in a MinIO server pool. Erasure coding provides object-level healing with less overhead than technologies like RAID or replication, and enables MinIO to automatically reconstruct objects on-the-fly despite the loss of multiple drives or nodes/server processes in the cluster.
A group of drives is an erasure set and MinIO uses a Reed-Solomon algorithm to split objects into data and parity blocks based on the size of the erasure set and then uniformly distributes them across all of the drives in the erasure such that each drive in the set contains no more than one block per object.
To enable rapid growth, MinIO scales by adding Server Pools and erasure sets. If we had built MinIO to allow you to add a drive or even a single hardware node to an existing server pool, then you would have to suffer through rebalancing. The erasure code algorithm would read all of the objects in the erasure set back in, recalculate everything and restripe/rebalance the data and parity blocks onto the entire set including the new drive or node. It’s not worth it to disrupt production with this I/O blocking and resource intensive task just to add a drive.
Instead, MinIO brings the new Server Pool up, adds it to the existing Server Pools and then performs new write operations (weighted writes) to the pool with the least storage fills. MinIO uses weighted writes as the default mechanism because rebalancing is expensive and consumes a lot of resources. Rebalancing, which must be performed at a time when user traffic is low so as not the compromise application performance, can be launched manually.
We designed MinIO to be cloud-native object storage and this means it must be able to scale quickly, operationally efficiently and transparently. You don’t achieve rapid growth to cloud scale by adding a drive or a node. We’ve all seen data centers where they roll in storage by the rack or even the row in order to expand. There’s no operational efficiency trying to grow a cloud drive by drive or node by node.
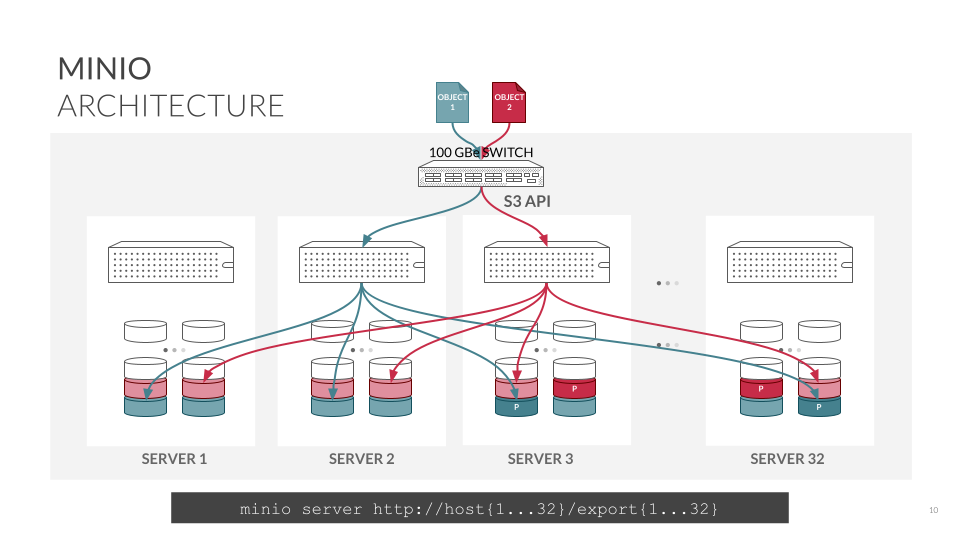
MinIO scales up quickly by adding server pools, each an independent set of compute, network and storage resources. MinIO is frequently deployed in a multi-tenant environment because of this ability to grow rapidly. Each tenant is a group of server pools that grow independently. Add hardware, run MinIO server to create and name server processes, then update MinIO with the name of the new server pool. MinIO leaves existing data in their original server pools while exposing the new server pools to incoming data. Unless you want to, there’s no need to rebalance - and that means no downtime and no risk of data corruption.
Each server pool is made up of its own hardware, enabling you to build out object storage with flexibility and agility to meet business and technology demands. Underlying storage hardware is typically optimized for performance or capacity. MinIO recommends that clusters have a minimum of 4 and allows for a maximum of 32 servers in a server pool, providing for significant growth at once.
Stop Automatic Rebalancing and Start Scaling
There’s no point in building object storage that is limited by the size or speed with which it can grow. Automatic rebalancing of object storage clusters is no longer a necessary evil - it is a thing of the past. Bring new object storage into service quickly and satisfy even the most storage-hungry users and applications.
Download MinIO and start building your object storage cloud. It’s straightforward, software defined for greatest flexibility, and S3 API compatible so it’s ready for your workloads. Join our Slack Channel or drop us a note at hello@min.io. We are here to help you banish rebalancing forever.






