Lessons from the HyperScalers: How Object Storage Powers the Next Wave of Managed Services Success

In the past few months, we have seen a rise in managed services for super-fast analytical databases based on object storage. Rising in popularity, these managed services are capturing both interest and workloads as enterprises are realizing the strategic benefits of combining lightning-fast data preparation with object storage, particularly for AI and ML applications.
This trend is exemplified by the success of MotherDuck and ClickHouse's managed service, ClickHouse Cloud. Both leverage object storage for strategic benefits in performance and cost savings. MotherDuck, a finalist for Deal of the Year at the 2023 GeekWire Awards, has raised $52.5 million in Series B funding, bringing its total funding to $100 million. Similarly, ClickHouse raised $250 million in Series B funding in 2021 and recently announced a significant partnership with Alibaba Cloud in mainland China.
At the core of these managed services' success is the decoupling of storage and compute, made possible by building data products on top of object storage. We will see more and more managed services being built using this exact architecture, because this model allows both the storage and compute to scale independently – effectively unlocking both infinite and workload specific scale for each.
This architecture is being leveraged by hyperscalers in these managed services, but the benefits of decoupled storage and compute is not exclusive to them. Both scale and performance are possible outside of the hyperscalers once the cloud is recognized as an operating model rather than a physical location. As the insatiable demand for clean, fast and accurate data by AI and ML models continues to grow, we must learn the lessons from these hyperscalers and understand how object storage unpins their success.
To do that, let’s begin by breaking down exactly what these managed services are.
Breaking Down Success: Lessons from ClickHouse Cloud
ClickHouse has long acknowledged the superior throughput experienced by their users on privately hosted high-performance object storage such as MinIO for their open-source product. Their product ClickHouse Cloud offers a managed service version of this offering.
ClickHouse Cloud is fast due to the implementation of the SharedMergeTree engine. The SharedMergeTree table engine disaggregates the data and metadata from the servers by utilizing multiple I/O threads for accessing object storage data and asynchronously prefetching the data.
Furthermore, ClickHouse's inherent design of both products contributes to its speed. ClickHouse processes data in columns, leading to better CPU cache utilization and allowing for SIMD CPU instructions usage. ClickHouse can leverage all available CPU cores and disks to execute queries, not only on a single server but across an entire cluster. These architectural choices, combined with vectorized query execution, contribute to ClickHouse's exceptional performance.
Unlocking MotherDuck's Potential: A DuckDB-Based Cloud Analytics Service
MotherDuck is a managed cloud service built on the open-source DuckDB. DuckDB is fast due to several key factors, some of which we have already described. It is particularly notable that DuckDB leverages columnar storage and vectorized query execution. This approach allows DuckDB to process data more efficiently compared to traditional row-based databases, especially for analytical workloads like data exploration before selecting features for an ML model.
DuckDB's performance is not just a claim; it has demonstrated its speed in tests, outperforming systems like Postgres, especially for moderate-sized datasets. What sets DuckDB apart is its commitment to simplicity. It doesn't boast complex features but instead focuses on providing a fast and straightforward way to access and analyze data.
Case Study in Disaggregation
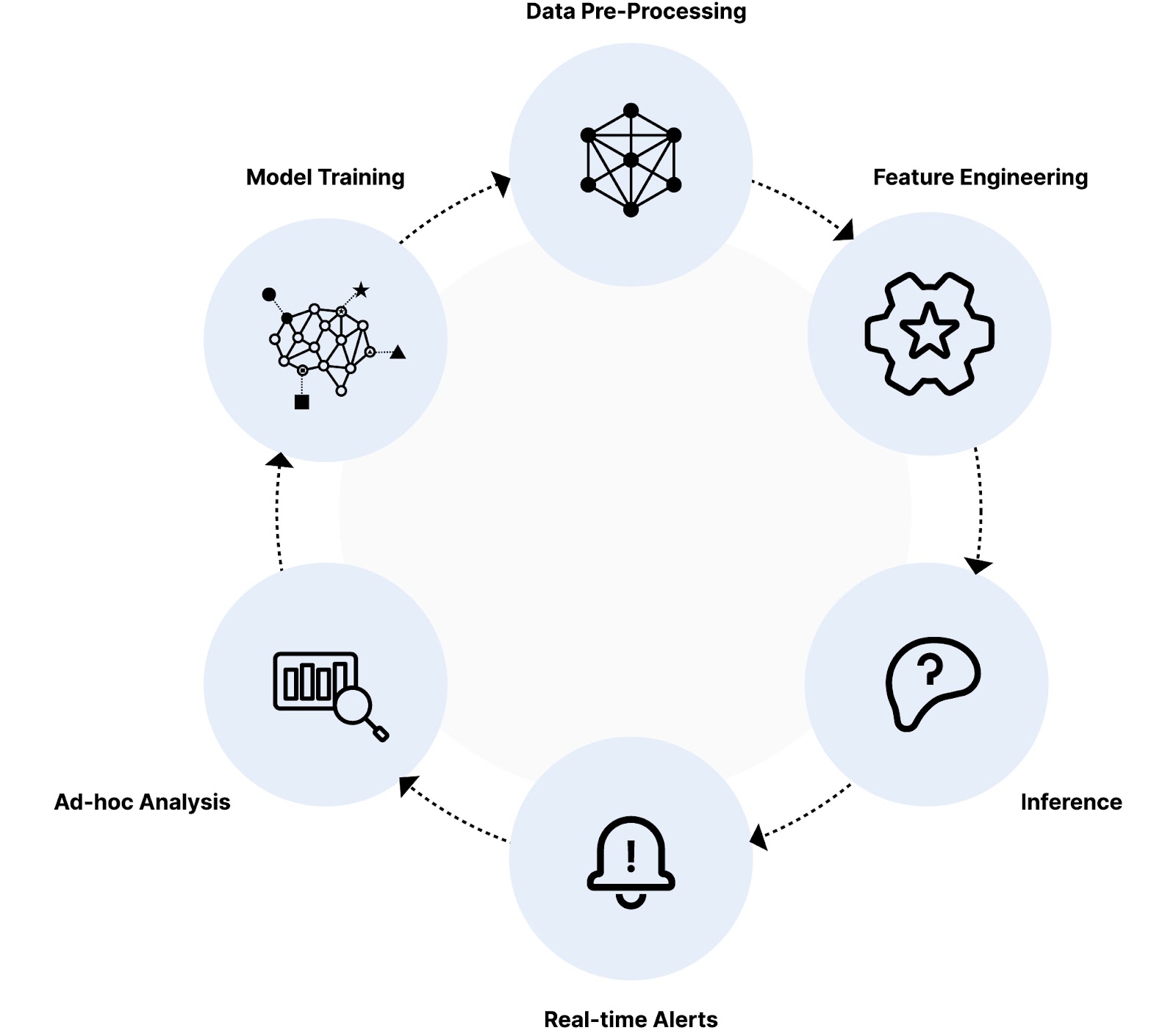
Let's apply this architecture to a case case. A large online bank experiences millions of daily transactions. Every second, data objects are created and flood their systems, and among them might lurk fraudulent activity. To catch these threats, the large bank needs a powerful AI system that can analyze this data and flag suspicious records. This is where a very fast, scalable database becomes crucial.
Here's how it works:
- Data Pre-Processing: The analytical database can query the data directly in object storage without ingestion and pre-process it in real time. This pre-processing could involve data cleansing, transformation, and feature extraction.
- Feature Engineering: The database stores and allows for the rapid calculation of various features from each transaction. These features could include things like transaction amount, location, time of day, user behavior patterns, and device used. The goal is to make a feature usable by a model during training and inference by turning everything into a small number.
- Inference: The AI model, trained on historical data and fraudulent patterns, analyzes the features of each transaction in real time. The database needs to support efficient querying and retrieval of relevant data for the model to score each transaction quickly and accurately.
- Real-time Alerts: Based on the anomaly score, the AI system flags suspicious transactions. The database needs to efficiently store and update this information, enabling immediate alerts to fraud teams for investigation.
- Ad-hoc Analysis: The analytical database allows for the exploration and investigation of suspicious transactions using various tools like dashboards, visualizations, and anomaly detection algorithms. A human should be on the lookout to make sure transactions marked as fraudulent are fraudulent and for any transactions the AI model missed. A very fast analytical database is necessary in both cases to make sure this is done quickly and new and better models can be produced quickly from this data.
- Model Training: This AI model will be continuously retained. Many artifacts, including the model itself and each training epoch will need to be saved into object storage.
Implementing an AI-powered fraud detection system brings several benefits to the bank. It helps them catch and stop fraudulent transactions early, reducing financial losses. This not only protects the bank but also makes sure customers have a better experience, knowing their accounts are secure. The AI system keeps learning and adapting to new fraud patterns, making the bank's security stronger over time. Plus, the system can handle more transactions without slowing down, supporting the bank's growth in the future.
This is just one use case of how fast, scalable databases based on object storage can empower AI and ML projects. Similar principles can apply to other scenarios like real-time anomaly detection in industrial processes, personalized recommendations in e-commerce, or dynamic pricing in transportation.
Reap the Benefits of this Architecture for Your Own Workloads
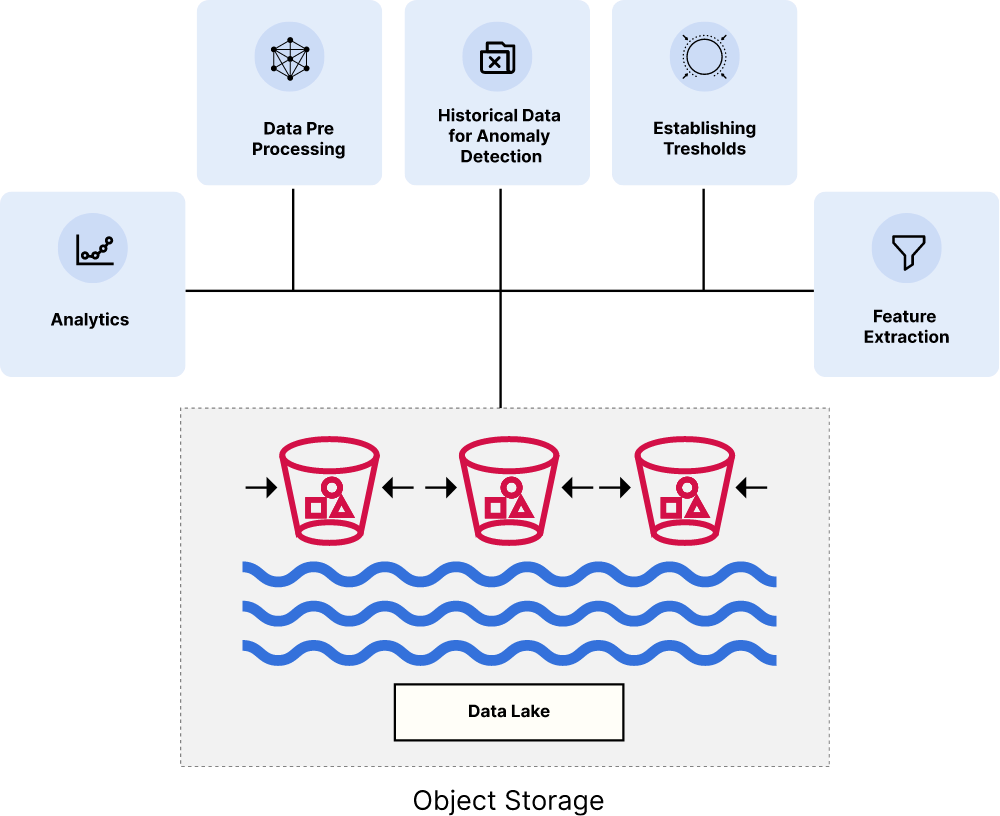
Let’s get down to brass tacks on how you can implement disaggregated storage and compute data lake architecture for scale and performance for your workloads. Your primary goal must be to choose an object store designed to be scalable and cloud-native. Here are the requirements to meet that criteria:
- Scalability and Elasticity: Cloud-native design and support for Kubernetes orchestration to enable seamless scalability and elasticity is an absolute must.
- Storage Efficiency and Resiliency: Per-object, inline erasure coding and bitrot detection ensure data protection the modern way to protect the integrity of your data.
- Cloud-Native and REST API compatible: You must be able to access data anywhere, anytime, and with the same, widely adopted API. This provides flexibility and accessibility for your data lake architecture and supports interoperability between systems.
- Security and Compliance: Sophisticated server-side encryption schemes are needed to protect data in flight and at rest, ensuring data security and compliance with data protection regulations.
- Plug and play: Must work well with all the other elements of the modern data stack. There is only one object storage that is shipped with Kubeflow and MLFlow.
Why You Should Build Privately
We’ve already established that the cloud is an operating model, not just a physical location. It is everywhere data is, on public and private clouds, on the edge, in colos, in data centers and on bare metal all over the world. This approach to the cloud provides freedom and avoids vendor lock-in, enabling organizations to maintain control and leverage over their workloads.
Perhaps more importantly, when cloud cost consciousness is having a moment, repatriating from the cloud can have tremendous cost savings. For example, in this Total Cost of Ownership (TCO) assessment, MinIO showcased an impressive 61% reduction in costs, amounting to $23.10 per terabyte per month, compared to AWS S3, which incurred $58.92 per terabyte per month. This analysis was conducted for a substantial 100 petabytes of object storage hosted on a private cloud.
You can have scale, cost savings and performance at the same time when you build your lakehouse privately.
Built for Success
The rise of super-fast analytical databases grounded in object storage has not only captured widespread attention but has also become a strategic imperative for enterprises delving into AI and ML applications. The success stories of MotherDuck and ClickHouse Cloud underscore the pivotal role of object storage in achieving performance and cost efficiencies. These lessons will drive more and more managed services into this space, but also open opportunities for enterprises to execute their own success by building data lake houses using performant object storage anywhere. Join the discussion at hello@min.io or our Slack channel. We’d love to help you build.






