Optimizing AI Model Serving with MinIO and PyTorch Serve

Making the serving of your AI models more lightweight by leveraging the simplicity of MinIO’s object store.
tl;dr
MinIO object storage can be used as a ‘single source of truth’ for your machine learning models and, in turn, make serving with PyTorch Serve more efficient when managing changes to Large Language Models (LLMs). As always, sample code is in our GitHub Repo.
PyTorch Serve and the problems with Model Archives
PyTorch Serve has emerged as a relatively easy-to-use inference server to manage and scale the serving of ML models. To use PyTorch Serve, a given model’s files, dependencies, and “handling” instructions (more on these “handlers” later) need to be packaged into a portable archive format called Model Archive. In other words, everything your PyTorch Serve server instance needs to handle inference API calls for your model is contained within its Model Archive or .MAR file.
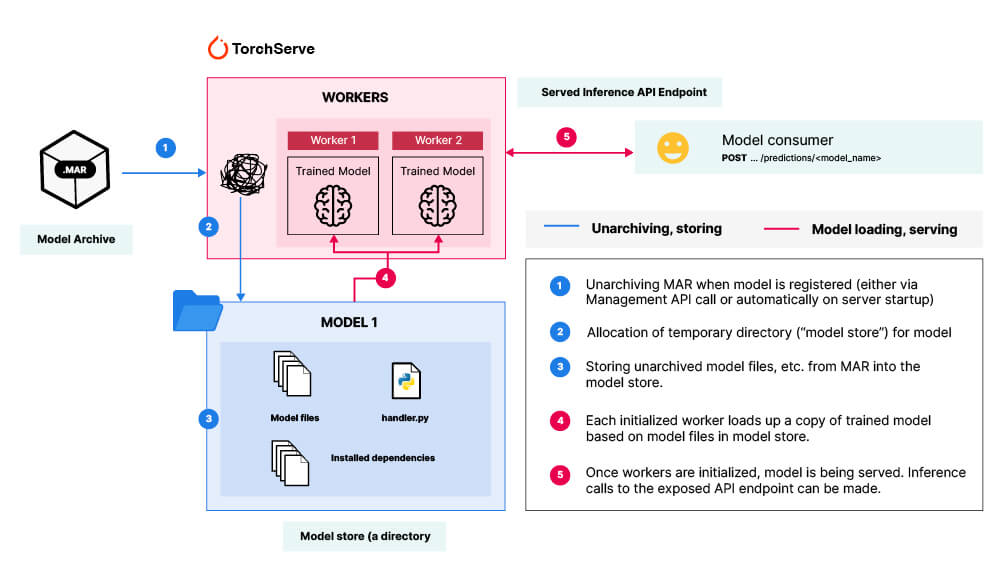
So what’s wrong with this picture?
Model Archive files (MAR files) are large and take a long time to generate, especially if you’re dealing with large language models (LLMs) or embedding models— where model file sizes can be in gigabytes. This has a couple of downstream consequences.
First, it increases the turnaround time for updating models that are being served, whether it is for production or experimentation: after you’ve made a small tweak to your model architecture, you need to generate a new MAR file and then you need to reconfigure and restart your server to load up this new MAR file. In addition, this adds an organizational burden— keeping track of your model files as well as multiple model archives.
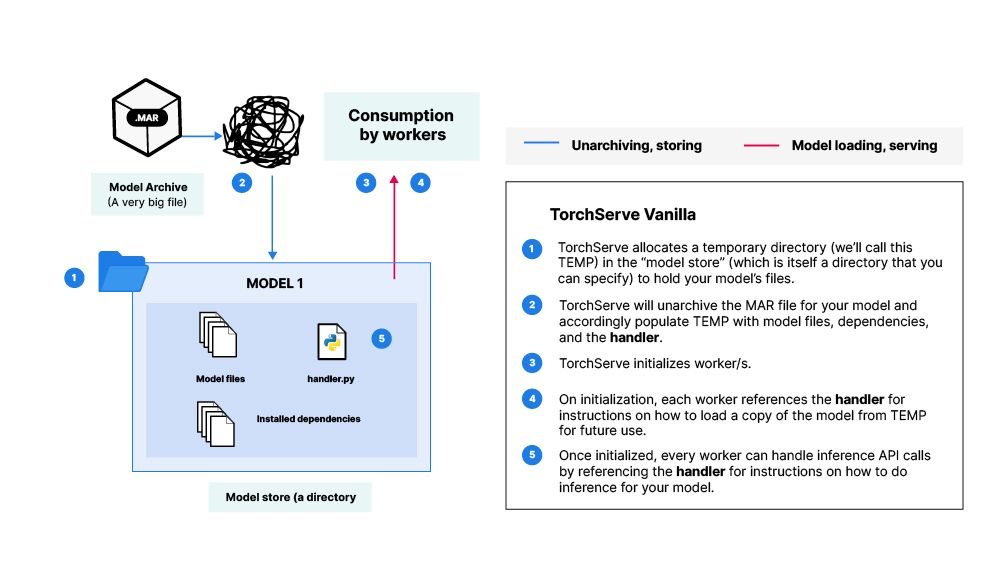
Second, the unarchiving process for large MAR files is taxing on memory and results in long wait times during initialization of the server’s first worker (Note: At the center of PyTorch Serve are “workers”— which are basically identical processes that each have a copy of the trained model in memory). See step 2 in the first diagram.
Ideally, we want MAR files to be somewhat decoupled from model architecture and thus, more resilient to change. In addition, we would like MAR files to also be lightweight, which would make serving more efficient.
In this post, we will learn to create a MAR file that is not tied to the files of a model. Instead, we are going to use MinIO to store and retrieve model files during PyTorch Serve’s initialization. We will see how this leads to lightweight MAR files and shortened turnaround times after model changes. We’ll also go through the specific code changes needed to leverage this capability and an end-to-end example as well.
Storing model files on MinIO
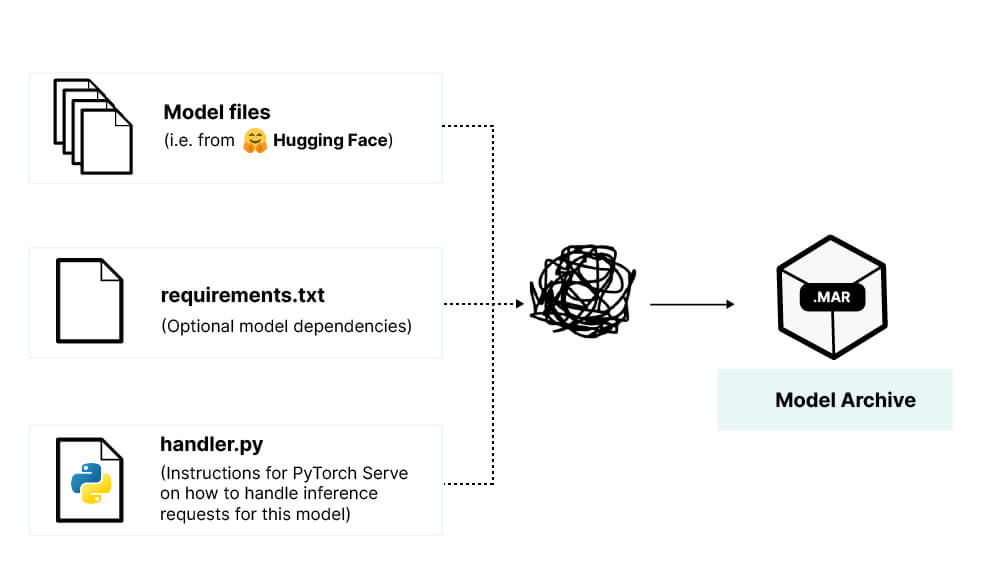
The files for a given model will generally look something like the following:
(this specific model is a popular large language model available on HuggingFace)
Traditionally, one would download these files to some local directory on their machine and then point the PyTorch Model Archiver tool to them in order to generate the MAR file.
The optimization of PyTorch Serve usage starts with doing this step a little differently. Instead of storing model files locally and generating a MAR based on those files, you can store all your model files as objects within a MinIO bucket. For example, in our own projects at MinIO, we use a bucket titled “models” and store each model’s files within it:
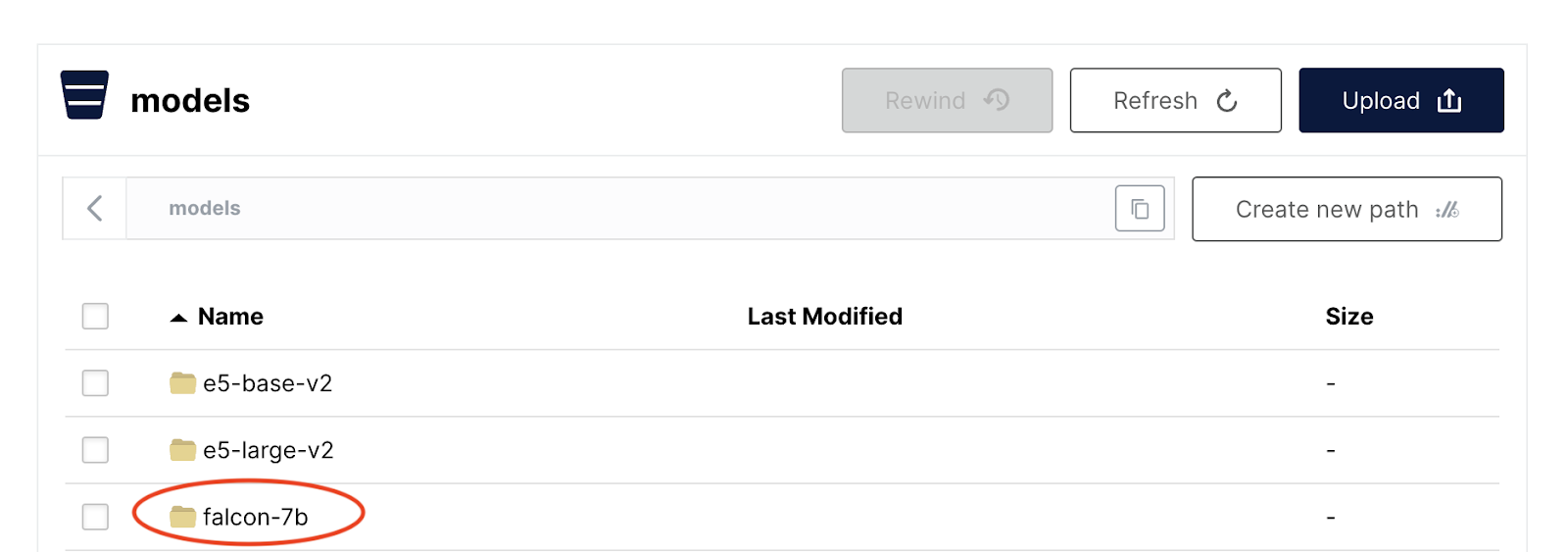
Each folder in the bucket contains all the model files, as-is from HuggingFace. At this point, a natural question that comes up is: why can’t we download model files directly from HuggingFace? While it is true that the HuggingFace Transformers API has simple constructors that can be used to load model files directly from HuggingFace repositories, there are some weaknesses with this approach to consider. Network lag or HuggingFace outages would make models unavailable or incredibly slow to download. In a production environment, the best practice is to avoid third-party dependency where you can. Using MinIO on-premise means avoiding these problems entirely.
MinIO is a purpose-built, on-premise storage solution. As a result, using MinIO as an object store for your model files yields a couple of immediate benefits by itself:
- Unified store for all your models and their files— a “single source of truth.”
- Versioning capability out-of-the-box for every file— and, thereby, every model.
- You can fetch these files quickly, reliably, and easily with the MinIO client.
For a more detailed description of MinIO’s object management benefits, check out Object Management for AI ML.
Putting it all together with a new handler
So, how does this actually make life simpler with TorchServe? And how do we use these model files in our MinIO bucket? What about the MAR file? To answer these, we first need to take a closer look at how PyTorch Serve actually starts up and serves a model.
Normally, PyTorch Serve will allocate a temporary directory (we’ll call this TEMP) to hold all the files related to your model. Once allocated, TEMP will be populated with the unarchived contents of the MAR file: the model files, dependencies, and the handler file. When a worker is initialized, it will load up a copy of the model based on the files in TEMP into memory, thus becoming ready to handle any inference requests. This ‘vanilla’ process has issues (See above: PyTorch Serve and the problems with Model Archives).
Instead, what if our MAR file was only composed of the handler file and the model dependencies? Generating and unarchiving the MAR file would take much less time. And more importantly, updates to model architecture will not require new MAR generation.
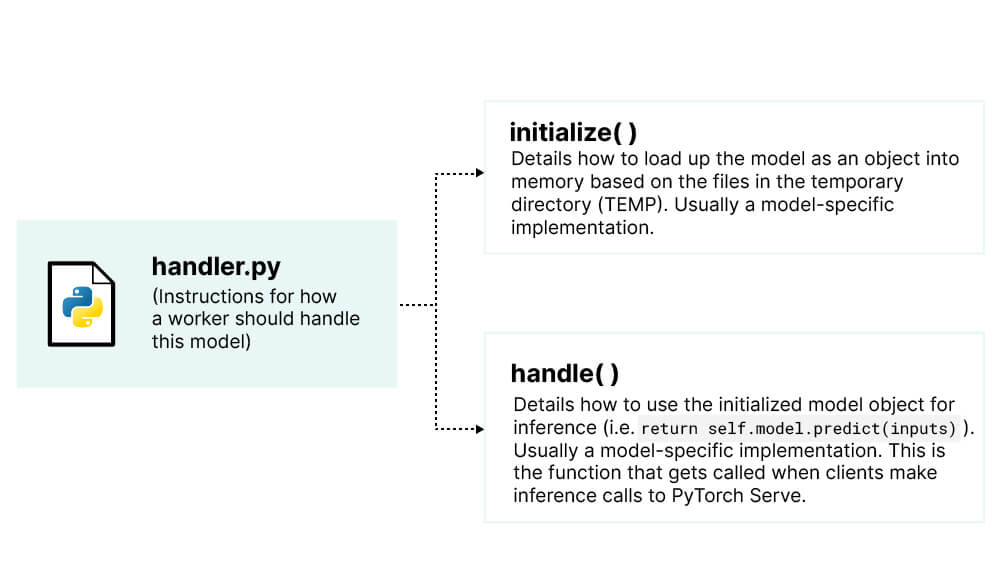
To facilitate this, we need to add a few lines of code to our model handler file. The handler file serves as an instruction guide for PyTorch Serve workers. The handler is responsible for two things: (1) initializing a model object and (2) handling an inference call:
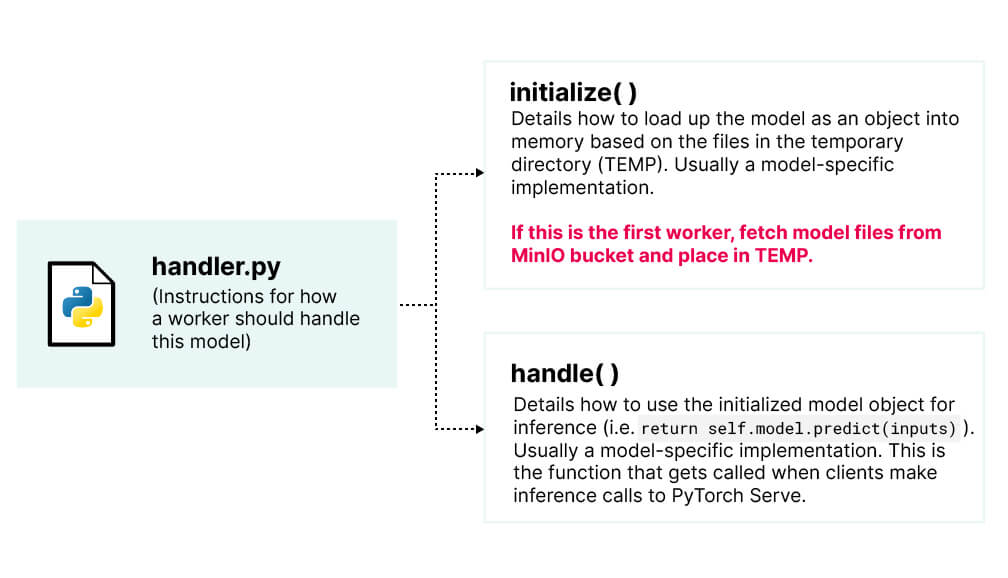
When a worker is initialized, the expectation is that TEMP has all the model files. This is what enables PyTorch Serve to increase the number of workers fairly seamlessly. By slightly modifying the handler’s initialize() function to fetch model files from MinIO upon startup, we can solve the problems with vanilla PyTorch Serve usage and continue maintaining the handler’s expectations:
Here’s how this modification looks in the handler code:
This simple change facilitates the benefits we’ve been talking about throughout the post. For a more thorough example implementation, check out the example at the end of this post. Let’s take an end-to-end look at the modified flow:
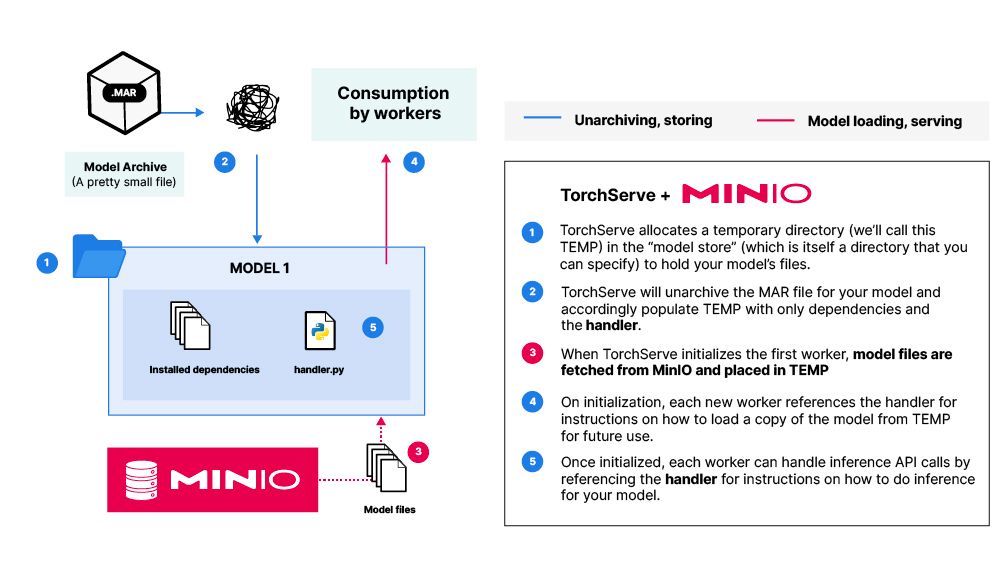
With this flow, you can now: (1) make use of a lightweight MAR file that also doesn’t have to be generated every time you edit the model you’re serving, (2) stop waiting for the laborious unarchiving process when PyTorch Serve initializes your model, and (3) rely on a single source of truth for your model files and their respective versions.
So what?
Now that you are able to use lightweight MAR files and leverage MinIO’s versioning capabilities and storage performance for your model files, what can you do?
In our own projects at MinIO, we leverage this paradigm to rapidly experiment with and deploy different models without having to worry about long turnaround times between them. All these benefits become especially apparent when working with the, frankly, giant class of Large Language Models and Embedding Models.
An end-to-end example
Let’s run through an example from model selection to serving. For this example, we’ll try to serve Falcon-7B, a popular Large Language Model. As always, the code for this example is available on our GitHub.
First, follow PyTorch Serve’s README to make sure you have installed the dependencies for PyTorch Serve.
Here’s what the model files look like on Hugging Face:
I’ll first clone the files to my machine with the help of Git LFS (caution: files are large)
I’m then going to upload the downloaded folder (with all the model files in it) to my “models” bucket in my MinIO server:
I’m now going to write a handler to deal with fetching the model files from MinIO, as well as the traditional responsibilities like loading a copy of the model and handling inference calls to the Falcon LLM. Here’s the handler (titled miniofied_handler.py) with some explanations of each key component.
Now that we have a custom handler, we are ready to create our MAR file. It’s possible to install model specific dependencies (i.e. transformers) direct to the host environment, but it’s a good practice to keep these dependency installations restricted to an environment that PyTorch Serve creates for your model. To leverage this, create a requirements.txt file for the handler-specific dependencies:
- minio
- torch
- transformers
Assuming you are in the same directory as the handler (and optional requirements.txt) you just created, you are now ready to create an MAR file (I chose the name “falcon-llm”) using the torch-model-archiver tool:
Note: the --requirement-file flag is needed only if you are using requirements.txt for handler/model-specific dependencies rather than installing them directly to the host environment. In order for PyTorch Serve to make use of this requirements file, you have to declare install_py_dep_per_model=true in config.properties, a file that PyTorch Serve references for configurations.
Now, assuming you are still in the same directory as the handler and, now, your MAR file, you are ready to start serving:
Note: The server can be configured and run in many different ways (i.e., port to run on, etc.). See the official PyTorch docs for more details.
Congratulations! You can now start making inference calls at: http://127.0.0.1:8080/predictions/falcon-llm :
Concluding Thoughts
Armed with MinIO Object Storage, your serving infrastructure is now more lightweight and resilient to changes in model architecture. As a result, the usual long archiving and unarchiving times for MAR files are cut down. In addition, your models and their corresponding MAR files travel less now, enabling you to save time and worry less about the organizational overhead commonplace with model serving.






