
It seems like more and more companies are touting themselves as one-stop shops for object, file and block storage these days - adopting the mantle of “unified” storage and offering to support a variety of storage protocols. The idea of supporting S3, NFS, SMB, HDFS, iSCSI, FCoE, NVMeoF and FCP all at once, is touted as the epitome of flexibility
Read more

Introduction
In a previous post, I provided an introduction to Apache Iceberg and showed how it uses MinIO for storage. I also showed how to set up a development machine. To do this, I used Docker Compose to install an Apache Spark container as the processing engine, a REST catalog, and MinIO for storage. I concluded with a very simple
Read more

Make MongoDB backups faster - upload in parallel with MinIO Jumbo.
Read more
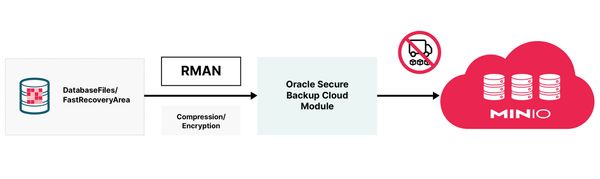
The Oracle Secure Backup (OSB) cloud module allows you to back up your Oracle Database to a MinIO bucket. It leverages RMAN’s encryption to ensure the security of the database backup.
Read more

When we started MinIO, we set out to set a new standard for object storage. We built a software-defined, S3 API compatible object storage that is the fastest and most scalable solution available that isn’t S3. But we didn’t stop there. We are also crafting an entirely different experience through our SUBNET experience. SUBNET combines a commercial license
Read more

Introduction
Open Table Formats (OTFs) are a phenomenon in the data analytics world that has been gaining momentum recently. The promise of OTFs is as a solution that leverages distributed computing and distributed object stores to provide capabilities that exceed what is possible with a Data Warehouse. The open aspect of these formats gives organizations options when it comes to
Read more

We were recently asked by a journalist to help frame the challenges and complexity of the hybrid cloud for technology leaders. While we suspect many technologists have given this a fair amount of thought, we also know from first-hand discussions with customers and community members that this is still an area of significant inquiry. We wanted to summarize that thinking
Read more

Driving competitive advantage by employing the best technologies separates great operators from good operators. Discovering the hidden gems in your corporate data and then presenting key actionable insights to your clients will help create an indispensable service for your clients, and isn’t this what every executive wishes to create?
Cloud-based data storage (led by the likes of Amazon S3,
Read more

Introduction
It’s challenging to keep track of machine learning experiments. Let’s say you have a collection of raw files in a MinIO bucket to be used to train and test a model. There will always be multiple ways to preprocess the data, engineer features, and design the model. Given all these options, you will want to run many
Read more

Introduction
The California Gold Rush started in 1848 and lasted until 1855. It is estimated that approximately 300,000 people migrated to California from other parts of the United States and abroad. Economic estimates suggest that, on average, only half made a modest profit. The other half either lost money or broke even. Very few gold seekers made a significant
Read more

Between the public cloud and your data center exists a middle ground where you can have full control over infrastructure hardware, without the high initial cost of investment.
Read more

If S3 costs are burning a hole in your pocket, then it's time to start thinking about running MinIO on-premise for your private cloud.
Read more

MinIO has partners across the ecosystem - from our cloud partnerships with AWS, GCP, Azure and IBM to more solution-focused partnerships like Snowflake and Dremio. We are pleased to add UCE Systems to our roster of solutions-based partnerships.
UCE is a leading consulting firm focused on modern data platforms (like the aforementioned Dremio). UCE has brought dozens of enterprises out
Read more

Introduction
This post was written in collaboration with Iddo Avneri from lakeFS.
Managing the growing complexity of ML models and the ever-increasing volume of data has become a daunting challenge for ML practitioners. Efficient data management and data version control are now critical aspects of successful ML workflows.
In this blog post, we delve into the power of parallel ML
Read more
When we announced the availability of MinIO on Red Hat OpenShift, we didn’t anticipate that demand would be so great that we would someday write a series of blog posts about this powerful combination. This combination is being rapidly adopted due to the ubiquitous nature of on-prem cloud and the need of large organizations wanting to bring their data
Read more

About MLflow
MLflow is an open-source platform designed to manage the complete machine learning lifecycle. Databricks created it as an internal project to address challenges faced in their own machine learning development and deployment processes. MLflow was later released as an open-source project in June 2018.
As a tool for managing the complete lifecycle, MLflow contains the following components.
* MLflow
Read more

MinIO has developed into a core building block for the media and entertainment industry. With a customer roster that includes the leading cable company, the biggest streaming company and dozens of companies up and down the stack we have added a number of different features in recent quarters. One of those is called the fan out feature and it is
Read more









