The Paradox of the Edge as the Core

The edge is big in technology architectures. Big technology things have a lot of narratives. Most of the narratives are self-serving from a vendor’s perspective. This makes sense, different companies have different perspectives and different agendas on the products they are looking to put forward.
Because of where we sit in the technology stack, we have a lot of conversations on the subject of edge and one of the core findings from those discussions is remarkably simple. Build your edge architecture using the cloud operating model but optimize for bandwidth. Put another way - the edge should look like a compute/storage/network optimized version of your cloud architecture. It may sound radical at first, but it makes complete sense - operationally, technically and economically.
It’s estimated that the global data volume of edge IoT connections will rise from 13.6 ZB in 2019 to 79.4 ZB by 2025 as energy-efficient, dense form factor edge hardware is deployed to locations such as cell towers, retail stores, automobiles or factories.
There are many drivers of this edge data explosion:
- Low-latency data processing: Processing data closer to the edge of the network reduces the time it takes for a roundtrip where data travels from the device to the cloud and back. This results in decreased latency and more responsive applications.
- IoT and edge device management: With everything connected, edge cloud can be used to manage and control large numbers of IoT devices, such as sensors, cameras, and other equipment, which may be geographically distributed across the world.
- Content delivery: Edge cloud can be used to distribute large file content, such as video, audio or software updates. Intelligent caching improves the user experience by improving the speed and efficiency of transfers to users who are physically closer to the edge cloud location.
- Offline data processing: Edge cloud can be used to process data even when the connection to the central cloud is lost, which is useful for applications such as autonomous vehicles, drones, and robots that need to operate in remote or offline environments. For this reason, edge services must be designed to run both when connected and not.
We are going to focus on the storage component in this post. These are some of the lessons we have learned alongside our telco, defense, manufacturing, media, gaming, retail and automotive customers.
As noted, the first principle is that edge storage must follow the same operating constructs and architectural frameworks as the rest of the cloud-native ecosystem. To unlock the value of edge is to consider edge architecture as merely an extension of your current data management framework using cloud-native principles, Kubernetes, automations and software defined object storage - but optimized for bandwidth.
This often means that some amount of compute needs to take place at the edge such that the data payload that is processed and shipped to a central location is reduced. The goal here is to minimize data downtime associated with transit or ETL tasks associated with traversing systems.
Related: Storage at the Edge
Containers, Physical and Otherwise
There is more than a bit of irony that many edge deployments are actually shipping container sized datacenters, complete with power and cooling. These containers house compute, storage and networking that are in turn orchestrated using Kubernetes.
Kubernetes can play a key role at the edge. With Kubernetes, developers know they can write code locally and deploy to the datacenter, public/private cloud and the edge without a snag. Through Kubernetes, data can be exposed consistently across the multi-cloud as an API service with granular access controls. Kubernetes and the S3 API also ensure business continuity through automated failover mechanisms.
MinIO was designed and built as a multi-tenant and multi-user system that scales seamlessly from GBs to EBs. Naturally, Kubernetes plays a key role in MinIO’s multi-cloud and edge functionality. As favored by DevOps teams, Kubernetes-native design requires an operator service to provision and manage a multi-tenant object-storage-as-a-service infrastructure. Each of these tenants run in their own isolated namespace while sharing the underlying hardware resources.
With software-defined MinIO, DevOps teams benefit from the ability to declare configurations and use automations to apply them across locations. The result is that edge is no longer a special edge case (pun intended), it is simply another cloud-native deployment.
Batch It Up
Batch data integration operations are frequently used to build ETL/ELT processes. They can play an important role at the edge where connectivity and/or bandwidth are at a premium.
The goal is to conduct processing and analytics at the edge where data is created, filter out the extraneous and repetitive bits and transfer the insights and associated data to a centralized data lake. The compute and storage resources at the edge should be small and efficient, just enough to process and store data on its way to the data lake. ETL/ELT, processing and early analytics take place at the edge, and move data through a classic hub-and-spoke model in order to feed the data lake.
MinIO’s batch capabilities are relatively new, but are particularly relevant in the edge topology we see in the field. Using a batch framework for data replication or movement provides application developers and infrastructure operators with fine grained control over their entire data footprint.
Furthermore, batch replication allows movement of data at any desired time from any source to any destination. In edge use cases where bulk replication or other all-in-one data movement approaches are prohibitively costly, this approach is preferred.
The Greek Freak
Lambda event notifications are a significant part of a loosely coupled architecture in which microservices interact and collectively process data. Instead of communicating directly, microservices communicate using event notifications.
For example, a microservice may verify data and, once it is finished with one object, the next microservice is notified to begin pre-processing. In this way, microservices are isolated from one another and changing one service does not require changing other services as they communicate through notifications, not by making direct calls back and forth. This approach can be highly effective in compute or storage constrained environments where capacity utilization can be relied on to overcome burstiness.
MinIO produces event notifications for all HTTP requests (GET , PUT, etc.) and these notifications are commonly used to trigger applications, scripts and Lambda functions. The most common use is to trigger data processing on an object after it is written to a bucket.
A 1-2 Punch
MinIO customers use a combination of Batch Replication and Lambda Notifications to power edge data pipelines. This architecture processes data rapidly and eliminates the requirement for user intervention. The combination of batch processing and Lambda Notifications can be put to work manipulating data files, converting files between formats, combining data from multiple sources and more.
These technologies are often combined to form a data pipeline between the edge and the data lake at the core. Once data is in the data lake, more compute (and elastic compute) can be leveraged for analytics, AI/ML and reporting frameworks. The faster the data lake can be fed, the quicker insights can be harvested to allow for more rapid decision making.
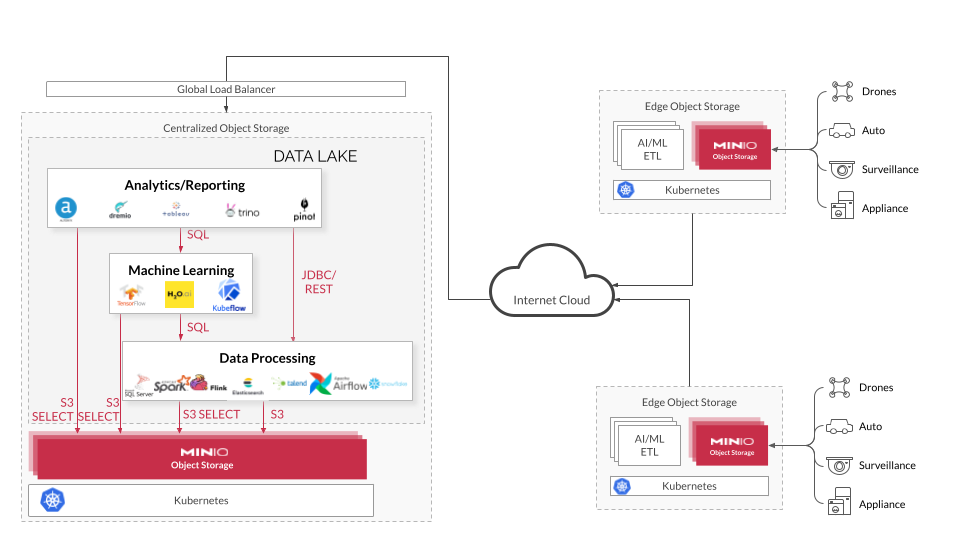
A Real World Example
Chick-fil-A is a well-known fast food restaurant chain that relies on open-source Kubernetes and GitOps to manage edge deployments using a cloud-native DevOps approach. The company has 2,000 restaurants and hundreds of thousands of network-connected “things” such as fryers, grills, refrigerators and food trays. As these devices send information back and forth, there is a need to analyze their data and control them locally.
Each Chick-fil-A restaurant runs a small Kubernetes cluster, enabling a full cloud-native edge environment. Data needed for immediate operations stays local, while higher level business and operational information is sent to the central data lake. Chick-fil-A maintains a Git version control repository in the cloud. Edge clusters pull down specification files and apply them without manual intervention.
While Chick-fil-A doesn’t run MinIO, their architecture is exactly what we would have suggested. Create a cloud-native instance (2,000 of them actually) that looks and feels like what you run in the datacenter. It is simple to manage, simple to operate and simple to troubleshoot (ship a new mini-cluster, plug it in and off you go).
The Edge is Dead, Long Live the Edge
The time has come to evolve our thinking around edge and edge architecture – and shift focus from “edge compute and storage” to “edge is part of my cloud-native footprint”. After all, we live in a cloud-native world where edge architecture must be consistent with cloud architecture, and where data can be retrieved with the same API call regardless of where it lives. More importantly, as edge use cases start to mature, the focus is shifting away from specialized storage that runs on edge hardware towards building a multi-cloud platform that allows your organization to field the same storage across cloud, edge and on-premise – and that is Kubernetes-native, software-defined object storage.
You can find more of our thinking on the edge in this piece. Conversely, you can download our <100MB binary here and see how it fits on something like a Raspberry Pi. Questions? Hit us up on the Ask an Expert channel if they are commercial in nature or General Slack if they are technical in nature.






