Running Apache Presto on MinIO: Benchmarking vs. AWS S3

The growth of Presto in the enterprise is a function of its speed, SQL compatibility, extensibility and enterprise feature set. While initially designed to speed up Hadoop, the success of the project has led to much broader adoption - on S3, Cassandra, MySQL, and more. Presto allows for data queries that traverse data stores and locations - a big plus in the multi-everything world of big data analytics.
This post is focused on the performance of Presto, more specifically on the performance comparison between Amazon’s S3 object storage service and MinIO’s object storage software. This installment is part of a series of blog-posts on benchmarking the performance of object storage, our previous posts on HDD/S3 Benchmark and NVMe/S3 Benchmark can be found in the respective links.
MinIO returned to AWS to conduct its benchmark work and utilized bare-metal, storage-optimized instances with NVMe drives and 100GbE networking.

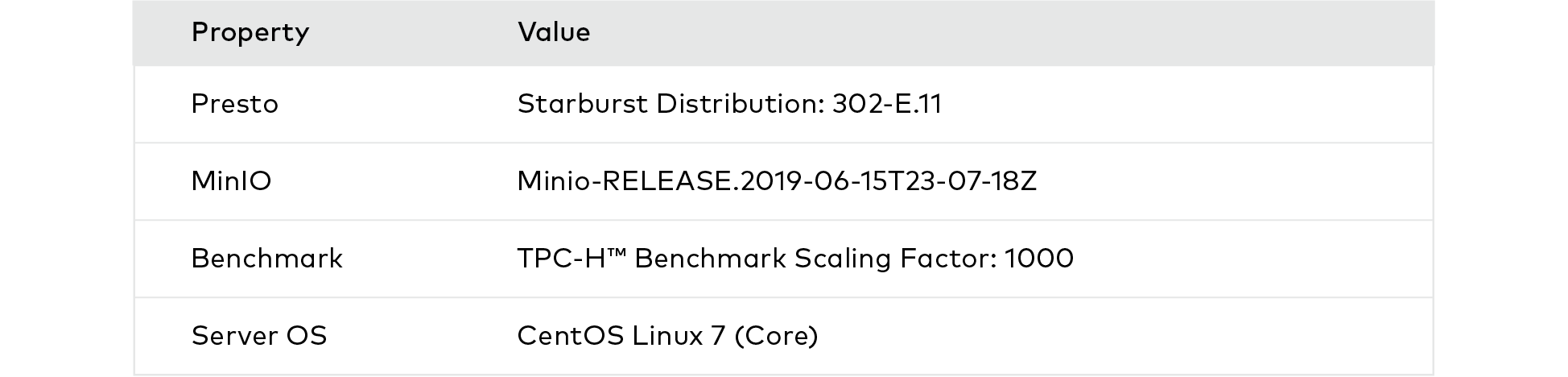
MinIO used the Starburst 302-E.11 distribution of Presto. MinIO is a big fan of the team over at Starburst and of the work that they are doing to constantly improve their enterprise product - notably large joins, security and manageability improvements.
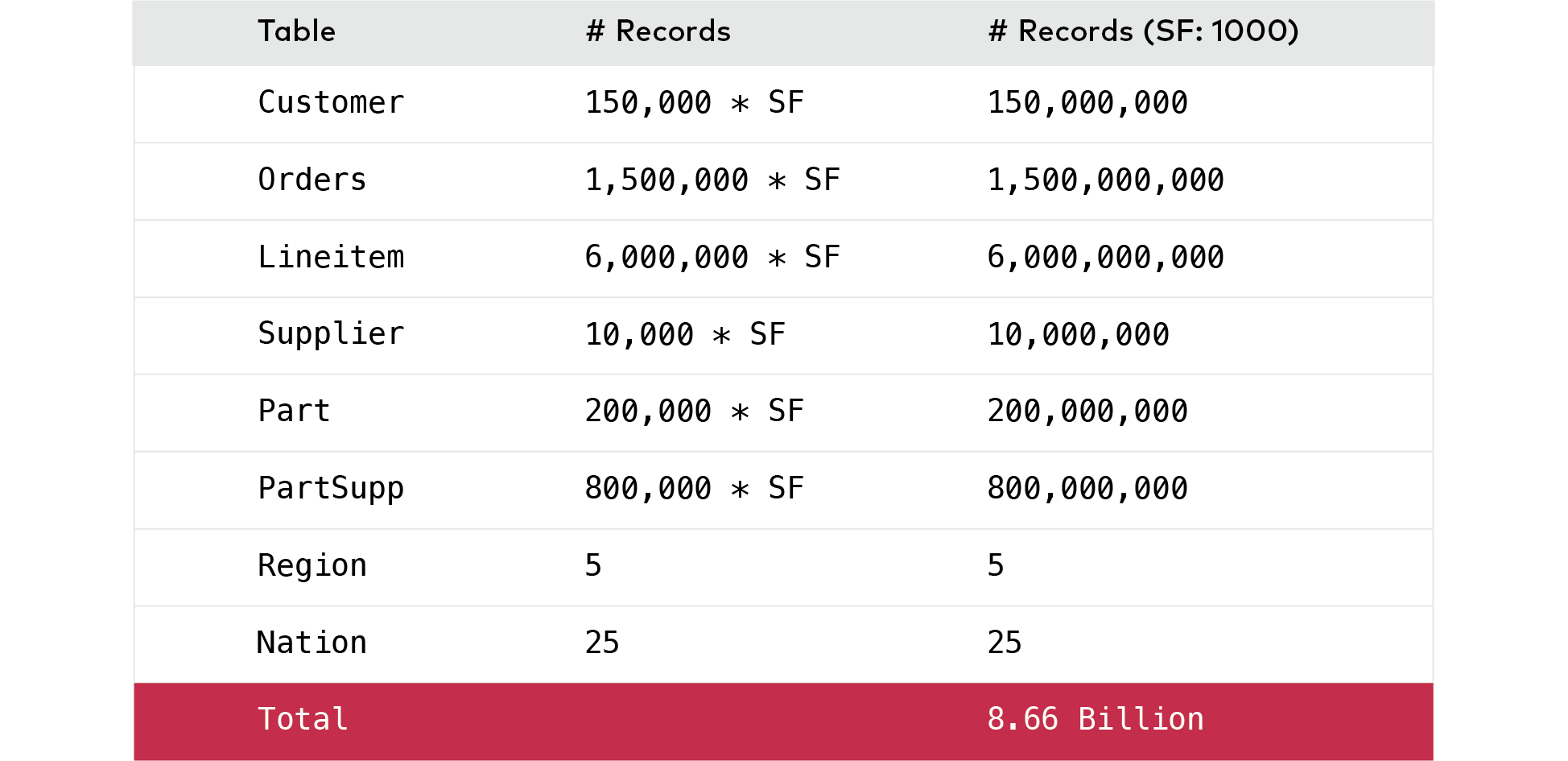
For this work we selected the TPC-H Benchmark with Scaling Factor 1000. TPC-H is broadly accepted for its query diversity, business orientation and real-world complexity. A summary of the data record sizes is shown below:
The benchmark tests were conducted in two phases. In the first phase, data was provided to Presto from AWS S3. The second phase had data residing in MinIO. The servers running Presto remained unchanged between the two phases.
It is difficult to compare the hardware running the storage backends, as AWS S3 is a globally available service. However, it is a reasonable assumption to make that S3 had a larger number of machines processing requests and flushing out data. Unlike MinIO, AWS S3 does not make any consistency guarantees, which reduces the computational burden on the underlying hardware, further tipping the performance in S3’s favor.
Despite these limitations, the performance of MinIO was comparable to S3, only narrowly favoring S3. As is often the case, some query specific performance was to be expected. A graph summarizing the query times comparing MinIO and S3 for Starburst Presto workloads is presented below:
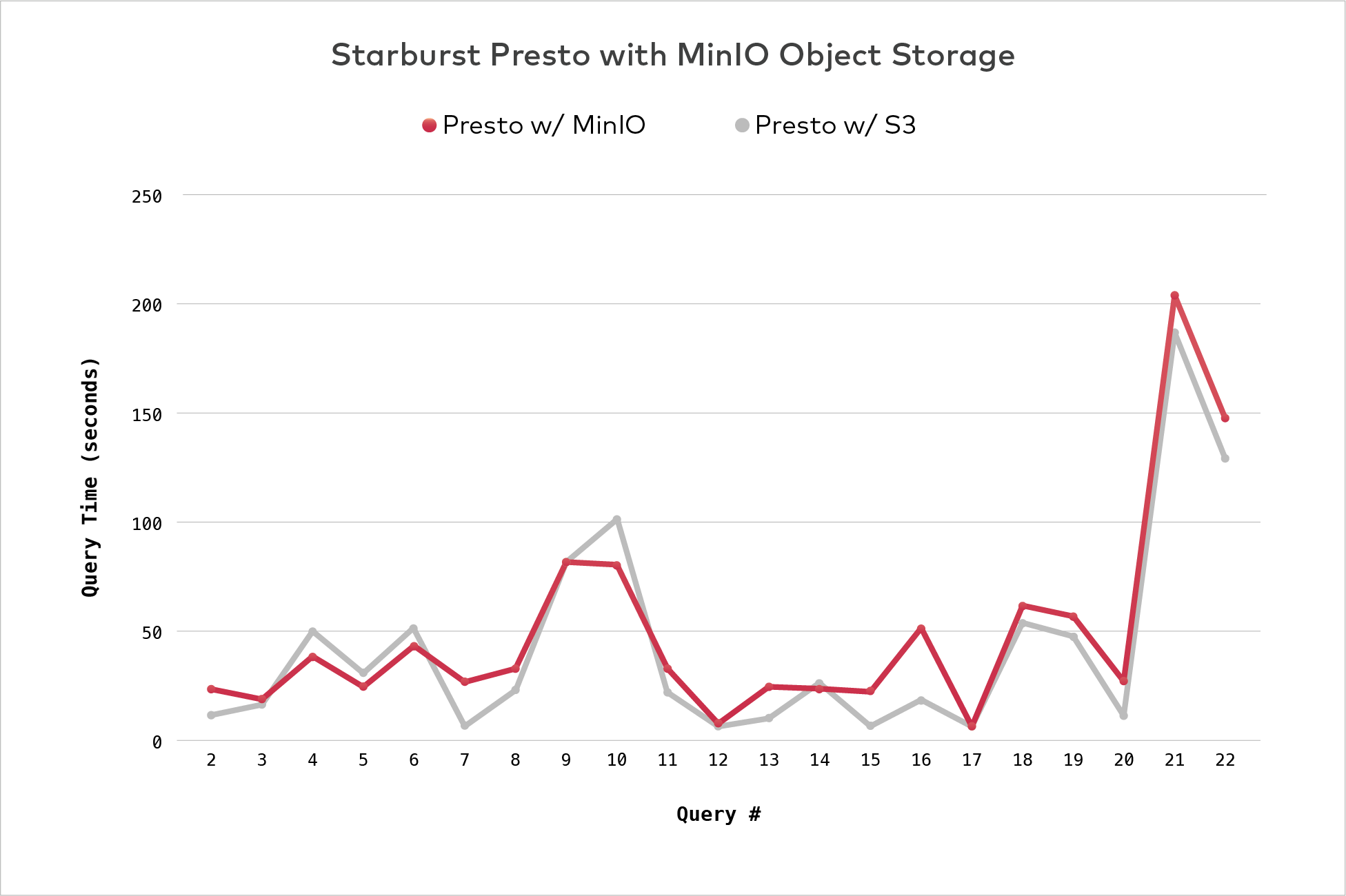
The overall takeaway for enterprises is that Presto’s capabilities translate remarkably well to object storage. The result is that object storage can and should be a foundational component of the enterprise data stack. Its superior economics, infinite scalability and rich enterprise feature set means that it wins the price/performance battle vs. Hadoop and other technologies in the vast majority of cases (note we didn’t say every case).
As always, we have the full details available for those who are interested. Check back for our upcoming post on Spark vs. AWS. If you have any questions, don’t hesitate to drop us a line at hello@min.io or hit up the technical request form at the bottom of the page.






