AIStor Adds Support for the S3 Express API

When Amazon introduced S3 Express One Zone in late 2023, they redefined expectations for high-performance object storage in the public cloud. Nearly every major AI builder and data lakehouse practitioner is adopting this much faster API. As AWS often does, they moved the industry forward, and now more than ever, it is clear: object storage is the foundation of modern AI architectures and data lakehouses.
MinIO AIStor now offers support for Amazon’s S3 Express API, a streamlined version of the general-purpose S3 API. MinIO AIStor is the first and only AI data storage platform to adopt AWS’s S3 Express API and enable organizations to put all of their analytical and AI data, not just a subset, in “express mode” at no extra cost.
AIStor has consistently delivered the best throughput with the least amount of hardware, saturating the network for high-volume reads such as LLM model checkpointing and full data lake refreshes. With the addition of the S3 Express API to AIStor, the most latency-sensitive use cases run on-prem, in private clouds, on colos, and hybrid environments, backed by the world’s leading object storage software.
In the sections that follow, we’ll dive into what makes the S3 Express API different from the standard API, why those differences matter for AI and data lakehouse workloads, and how AIStor brings those benefits to your own infrastructure, with benchmarking to prove it.
Why S3 Express: Tradeoffs Worth Considering
AWS S3 Express One Zone represented a significant step forward in addressing the performance limitations of standard AWS S3 object storage across multiple zones. By eliminating overhead, such as global metadata aggregation and server-side checksum computations, it redefined what object storage can do for latency-sensitive workloads. Express also makes important API-level tradeoffs for this increased performance: namely versioning, object locking, and MD5-based ETag validation are removed to reduce latency. In addition, in the S3 Express API, LIST operations are no longer lexicographically sorted, which breaks assumptions for some legacy applications.
In AWS, the benefits of these performance enhancements come with tradeoffs. First, there is a 5x cost premium relative to standard S3 storage, making it prohibitively expensive to use Express in many cases. Second, there are no built-in replication or data protection capabilities. This exposes workloads to a significant risk of data loss. These two factors make S3 Express One Zone intentionally ephemeral: applications are expected to copy source data into Express buckets, process it, extract results, and then delete the data, creating a complex and failure-prone workflow.
These drawbacks are simply not present in AIStor’s on-prem implementation of S3 Express.
Strategic Fit: First-Mover Advantage in Object Storage for AI
AIStor uniquely supports both the breadth of the general-purpose S3 API and the streamlined, performance-first model of the S3 Express API; all with the flexibility of being able to deploy anywhere. This flexibility allows organizations to build data infrastructures that match workload characteristics precisely: standard S3 for immutable source data, and S3 Express for low-latency, high-ingestion-rate operations like model training, data lakehouse analytics, and stream processing.
In practice, what this dual strategy could look like for data lakehouse architecture is that the bronze tier with raw source data would continue to use the general purpose S3 API, as this workload requires versioning and immutability. Silver, gold, and platinum tiers, where the majority of data is transformed and queried, on the other hand can leverage the streamlined S3 Express API.
Where AWS offers S3 Express only as a single-zone, ephemeral storage class with no built-in protection, AIStor goes further. Enterprises gain access to the S3 Express performance model along with synchronous active/passive replication, enabling RPO=0 guarantees even for Express workloads. This allows organizations to safely use S3 Express semantics for operational production data, not just for short-lived scratch processing.
With AIStor, enterprises can now get the best of both worlds: they can leverage the S3 Express API and its performance benefits on their own infrastructure, without sacrificing data protection or economic viability.

Pushing the Low Latency Performance to Next Level
In the general purpose S3 API, several sources of latency are baked into the protocol, including MD5 digest calculations on PUTs, global sorting of LIST results across all nodes, consistency guarantees on versioned buckets, and complex multipart commit behavior. Each of these adds CPU load, memory pressure, and coordination delays that, while acceptable for traditional object storage use cases, are significant impediments to AI/analytics pipelines operating at petabyte scale.
With the S3 Express API, both AWS and AIStor have eliminated these bottlenecks by rethinking the storage protocol and the backend implementation. ETags are lightweight and unique without requiring digest computations. LISTs stream directly from storage nodes without aggregation. Appends are natively supported with atomic consistency, removing the need for intermediate temp files or complex object stitching. Multipart uploads require consecutive part commits, simplifying application logic and validation.
What Changed: Streamlined APIs, Real Gains
For MinIO, GET performance at scale is already a solved problem. AIStor has long delivered near-wire-speed read throughput performance for large file GETs, easily saturating 100Gbps 400Gbps, and even emerging 800Gbps networks. Similarly, AIStor has long saturated the small-file GET IOPS capabilities of storage server hardware, supporting applications like real-time analytics with small range reads over large tables.
Today, the bottleneck shifts to LIST and PUT performance. As data volumes grow, the impact of small inefficiencies in metadata operations and object ingestion become overwhelming. Applications like personalized AI and streaming log ingestion are particularly sensitive to the latency introduced by general purpose S3 API semantics.
AIStor’s S3 Express API support introduces key architectural improvements aimed at eliminating traditional S3 overhead:
LISTObjectsV2
- Results are unsorted
- Path separator is / only
- Prefix matching is hierarchical; directories must be explicitly specified
Benefit: Faster time to first byte in production environments. Simpler code with more predictable behavior. Eliminates compatibility issues when exporting to non-S3 systems like backups or archives.
PutObject
- Eliminates server-side MD5 checksum computation and lowers AIStor CPU utilization, and Etag is now simply a unique identifier.
- Directories and objects cannot share the same name (e.g., foo/bar.txt means foo must be a directory, not an object)
- Directories are real directories, separate from objects. Meaning, the “directory hack” in the standard S3 API that catered to legacy POSIX applications, essentially a hack emulating mkdir, has been closed.
Benefit: Faster uploads across all object sizes. Lower CPU usage and higher concurrent throughput.
PutObject / Multi-Part
- Parts must be in consecutive sequence for commit to complete.
- Eliminates all server-side MD5 checksum computations and lowers AIStor CPU utilization, and Etag is now simply a unique identifier. Use the newer S3 object checksum feature to validate the object was transferred properly.
Benefit: Simpler, more reliable application behavior. Faster uploads and higher throughput at scale.
PutObject / Append
- Max of 10k parts to an object. If an object is created via multi-part upload of “x” parts, the number of possible appends is 10,000-x.
- Appends are atomic commits (strictly consistent) to the end of the object, immediately visible to all applications. Every append is committed.
- Unlike legacy POSIX where the first to commit wins and there is no order guarantee,, appends are now both atomic *and* exclusive. There is an order guarantee in that all incoming writes are ordered by applications providing an explicit offset. The first to request a write at that offset will succeed, and subsequent request attempts will fail.
Benefit: Ensures consistency and correctness in distributed environments. Reduces application complexity. Guarantees predictable, ordered behavior for event-driven and log-style workloads.
Other changes:
Versioning and immutability are disabled in the S3 Express API to allow room for atomic, exclusive appends. Open table formats like Apache Iceberg already manage data versioning efficiently. Versioning is often managed by the application layer as it has better context of the data. This eliminates a redundant feature at the storage layer and further boosts small object throughput.
Multipart upload behavior is simplified. Parts must now be committed in consecutive sequence, eliminating the possibility of part misordering. This reduces complexity, thereby minimizing data consistency-related bugs and issues in the application code.
The S3 Express API removes server-side encryption with customer-supplied keys (SSE-C) due to security risks in letting applications manage encryption keys. Only SSE-S3 and SSE-KMS are supported, ensuring strong encryption and secure, centralized key management.
Directory behavior has also been corrected. The general purpose S3 API emulates directories through zero-byte objects and also allows duplicate directory and object names, which results in confusion and incompatibilities when exporting data. The S3 Express API implements real directories, fixing this limitation and enabling seamless data interoperability with non-S3 compatible systems.
Collectively, these changes eliminate common sources of latency, reduce system complexity, and enhance application predictability. These performance improvements are not just on paper: we’ve benchmarked and proven our results.
Performance Benchmark Results
For AIStor, the performance benefits over the S3 API by the S3 Express API accelerate dramatically for the LIST operation, but PUTs also get ~20% faster:

We’ve also compared the behavior of the S3 Express API on AIStor versus AWS S3 Express One Zone for PUT, GET and LIST performance, which show speed gains across the board and dramatic gains for large object GETS and LIST API calls.
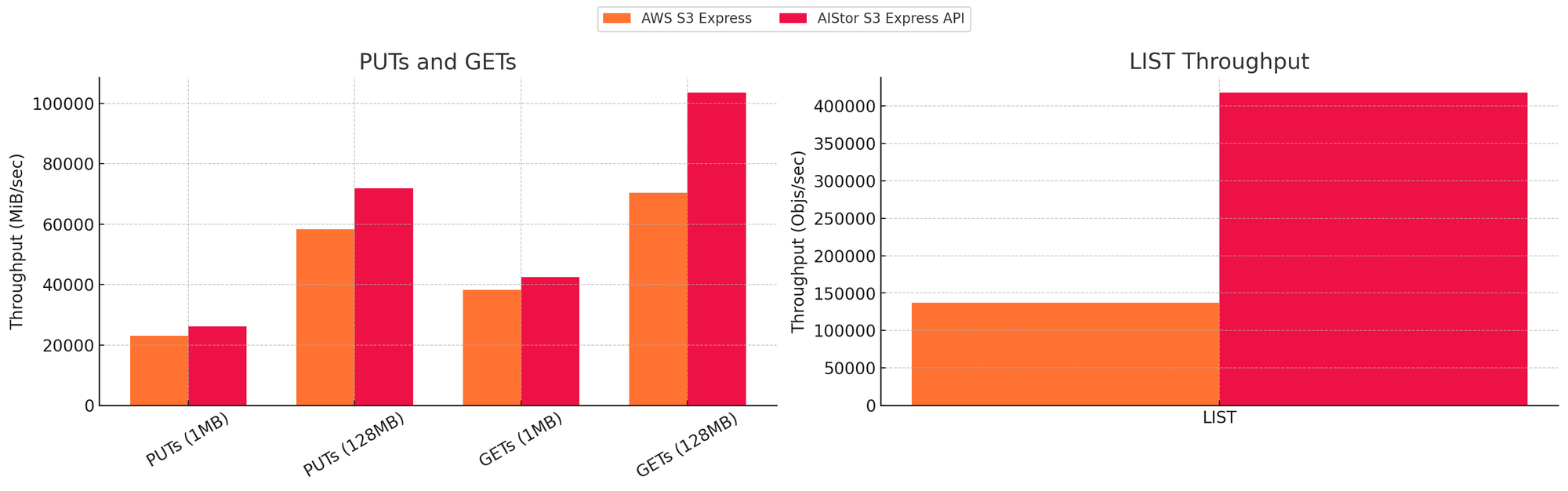
* AWS S3 Express One Zone performance requires the deployment of higher-end EC2 instances with 200GbE links such as `c6in.32xlarge` . AWS S3 Express One Zone returned errors at higher concurrency for LIST operation via throttling and SlowDown requests. The number shown is from a stable run with no errors.
The results speak for themselves and prove irrefutably that AIStor is capable of delivering both throughput and low-latency performance for the full lifecycle of modern AI and analytics workloads, from ingest to training to inference.
Benchmarking Configuration
For AIStor, the benchmarking setup used QLC drives, specifically the Sandisk WUS5EC1C1ESP7Y1 model with a 61.44 TiB capacity and PCIe 4.0 interface. These drives are classified as read-intensive/optimized and use Sandisk BiCS5 3D TLC NAND. Performance figures for the drives include up to 890,000 IOPS for random 4KB reads and up to 29,000 IOPS for random 4KB writes. It’s worth noting that performance is highest at 15 TiB and degrades gradually: halving at 30 TiB and dropping by 4x to 6x at 60 TiB.
The storage nodes used AMD EPYC 9754 128-core processors and were equipped with 512 GiB of memory. Each node had a 400 GiB/sec interface for both internode and client traffic, powered by the MT4129 ConnectX-7 NIC. There were a total of 8 nodes in the test.
For testing on AWS, the configuration consisted of 8 c6in.32xlarge instances each costing approximately $7 per hour.
Getting Started
Applications should be reviewed for compatibility. The S3 Express API has broad ecosystem support in the modern data stack, but always check to make sure your individual components are compatible before moving to production.
Workloads that rely on S3 features like object locking, MD5 ETag verification, or strongly ordered LIST results must be modified or isolated from AIStor deployments configured to use the S3 Express API.

To take advantage of the S3 Express API, use the latest version of AIStor client and SDKs. AWS SDKs are also supported. The S3 Express API focuses on performance-critical operations: PUT, GET, LIST, and Append. Advanced object lifecycle management features, notification events, and object versioning are not supported at the API level.
The replication setup remains simple. AIStor supports synchronous active/passive replication for S3 Express buckets, ensuring zero RPO where desired. Asynchronous replication is also available for globally distributed disaster recovery scenarios.
AIStor documentation will provide detailed configuration examples, recommended architectures, and migration guides at launch.
Right Fit Your API
This post outlined how the S3 Express API differs from the standard S3 API, the impact on performance of the S3 Express API and how AIStor delivers those benefits on your own infrastructure with full data protection and replication faster and more affordably.
Use the standard general purpose S3 API for workloads that need versioning, locking, or compatibility across tools. Use the S3 Express API for fast-ingest, low-latency operations like training, analytics, and streaming.
AIStor gives you both. Learn more here or contact our team at hello@min.io to get started.






