How to Secure MinIO - Part 1

MinIO, as an object storage system, can act as persistence layer for any S3 application. All these applications rely on MinIO to store and protect their data from outages as well as data corruption or loss.
Since all the data is going to MinIO, it becomes a critical part of your infrastructure, and therefore, an attractive target from an information security perspective.
Threat Model
To secure a MinIO deployment, we have to cover the following sections:
- How is data coming in? How are incoming connections secured?
- How does MinIO store data? How is the stored data secured?
- How is access controlled? How do we grant users and applications access?
Apart from these three major topics we also have to take care about additional aspects, like audit logging, insider attack prevention and compliance. However, first we will focus on getting the basics right and, only after we have secured the incoming and outgoing connections and put access controls in place, will we tackle the more nuanced aspects.
Securing Ingress
First, let’s focus on securing the incoming data streams. Therefore, we have to configure MinIO to accept and serve requests over TLS.
Conceptually, this is very easy to do. All MinIO needs is a TLS private key and certificate that should be mounted under certs/ in MinIO's config directory. For example:
ls -l ~/.minio/certs
drwx------ - minio 1 Jan 2021 CAs
.rw------- 119 minio 1 Jan 2022 private.key ⟵ The TLS private key .rw------- 461 minio 1 Jan 2022 public.crt ⟵ The TLS certificate
When running a distributed MinIO cluster, simply copy the same public.crt and private.key to all MinIO nodes such that all nodes have identical certs/ directories. Once you have restarted your MinIO cluster, all data transferred to MinIO will be sent over encrypted connections.
While configuring MinIO to accept TLS connections is straight forward, getting a TLS certificate may cause some headache.
You could generate a "self-signed" certificate using OpenSSL or other TLS CLI tools. We do have some documentation for this. However, your client applications will not be able to verify the authenticity of your certificate, and therefore, refuse to connect to MinIO. To resolve this issue, you could establish the trust link manually by copying your certificate to all of your clients - but that will quickly evolve into a maintenance nightmare - especially when you renew your certificate due to expiration.
Hence, most people use a TLS certificate that has been issued by a certificate authority (CA). The CA may be a web PKI CA, like Let's Encrypt. A certificate issued by a web PKI CA will be trusted by most client applications on the internet. However, if you're using MinIO internally - e.g. just within your organization - you can simply request a TLS certificate from your organization's internal CA.
In addition to encrypting data ingress, MinIO may need to talk to other services, like an audit log service, securely. Hence, MinIO has to be able to verify the TLS certificates of these services, and therefore, needs the certificate(s) of the issuing CAs. Such CA certificates should be placed into the certs/CAs/ directory. For example:
ls -l ~/.minio/certs/CAs
.rw------- 765 minio 1 Jan 2022 company-ca1.crt
.rw------- 1356 minio 1 Jan 2022 company-ca2.crt
By default, this certs/CAs/ directory will be empty and MinIO will only trust the system CAs.
Encryption at Rest
Once we have secured data ingress, we can take a look at securing data at rest. MinIO supports server-side encryption. In particular, MinIO can encrypt objects as continuous data streams while they're getting uploaded, and before they're written to the underlying disks. MinIO can also be connected to various KMS, like Hashicorp Vault, to fetch unique data encryption keys for each S3 object.
However, a MinIO cluster itself is decoupled from its KMS. Instead, the MinIO cluster talks to one or multiple KES instances. KES is a stateless and distributed key management system for high-performance applications. KES acts as KMS API abstraction for MinIO and takes care of operational aspects, like scalability and high availability.
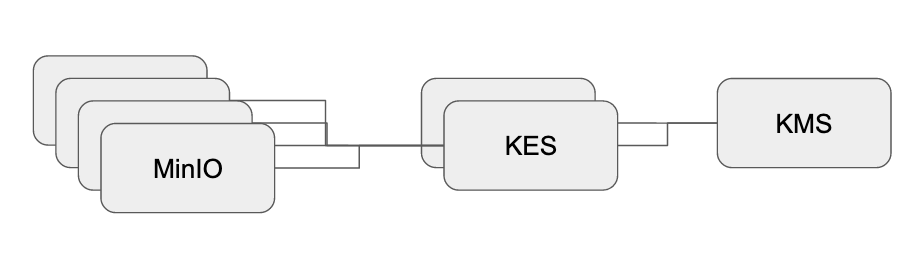
We provide guides for each KMS vendor that we support. However, we also run a public KES instance at play.min.io:7373 that everyone can use for their first steps.
We can connect our MinIO cluster to KES by setting the KES-related environment variables on each MinIO node. For example:
export MINIO_KMS_KES_ENDPOINT=https://play.min.io:7373
export MINIO_KMS_KES_CERT_FILE=/tmp/root.cert
export MINIO_KMS_KES_KEY_FILE=/tmp/root.key
export MINIO_KMS_KES_KEY_NAME=my-first-key
You can download the admin credentials (
root.key&root.cert) for
play.min.io:7373using the following curl command:curl -sSL --tlsv1.2 \ -O 'https://raw.githubusercontent.com/minio/kes/master/root.key' \ -O 'https://raw.githubusercontent.com/minio/kes/master/root.cert'
Once we have configured and restarted MinIO, we can check whether it can reach the KMS using the mc CLI:
mc admin kms key status <minio-alias>
Now, we can upload objects that get encrypted at rest. Therefore, we configure a bucket to encrypt newly ingressed data with keys fetched from the KMS:
mc encrypt set sse-kms my-first-key <minio-alias>/<my-bucket>
Any data that gets placed into this bucket will be encrypted with the key my-first-key at the KMS. This can be verified by fetching the object metadata. For example, via mc:
mc stat <minio-alias>/<my-bucket>/<my-object>
Name : <my-object>
...
Encrypted :
X-Amz-Server-Side-Encryption : aws:kms
X-Amz-Server-Side-Encryption-Aws-Kms-Key-Id: arn:aws:kms:my-first-key
Setting a KMS configuration on a S3 bucket will only affect newly incoming objects. Existing objects will remain unencrypted. Therefore, it is important to implement encryption at rest from the beginning.
Access Control
So far we have covered the basics of encrypting data in transit and at rest. However, encryption itself does not allow fine-grained access control. Instead, MinIO uses a role-based access control (RBAC) system based on S3 canned policies.
For example, each MinIO deployment contains a writeonly policy by default:
mc admin policy info <minio-alias> writeonly
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::*"
]
}
]
}
Each policy consists of one or multiple statements. Each statement either explicitly allows or denies a set of actions to be applied on a set of resources. In the writeonly example above, we allow the PutObject action to be applied on any resource; i.e. *.
Access policies are assigned to individual users or groups of users. These users can either be internal or external. Internal users are MinIO-specific and can be created and deleted within MinIO itself. External users are user accounts that live on an external IDP - like an OpenID Connect provider or LDAP server / Active Directory. For now, let's stick to managing policy for internal users and cover external IDPs later.
Let's assume we want to create a new user alice and give her read permission on all resources at the cluster. We can do this by first creating a new user:
mc admin user add <minio-alias> alice
Enter Secret Key:
We are asked to enter an S3 secret key for alice. It should be at least 8
characters long.
Once we add alice, we can assign a policy to her. In this case, let's use the pre-defined readonly policy:
mc admin policy set <minio-alias> readonly user=alice
At this point, alice will be able to read any object on our MinIO cluster but she will not be able to create or delete objects. From here, we could create new user accounts for all our applications and tune their policy permissions. However, there is another access control concept that is particularly useful: Service Accounts.
Service Accounts
Service accounts are static accounts that belong to a user. For alice we can create a new service account via:
mc admin user svcacct add <minio-alias> alice
Access Key: NLJOKS0YFVAXO9XBJ1W3
Secret Key: DZrtGnRKXu++J5IreLmD+BiHsd1sJ9fxy883xWEY
When we create this service account, we obtain a new access key / secret key pair. By default, the service account inherits the policy permissions of the user. However, the permissions of a service account can be reduced to the minimal set of permissions required. Therefore, service accounts are perfectly suited for applications managed by the S3 user.
For example, alice may run several applications that want to fetch data from our MinIO cluster. Instead of configuring these applications with her own S3 credentials, she should generate/request a new service account for each of her applications. Further, she can reduce the permissions of a particular service account - for example when an application needs to access just one bucket instead of the entire cluster.
Once the application is no longer in use, or in case of compromised credentials, alice can simply disable or delete the service account:
mc admin user svcacct rm <minio-alias> <service-account-access-key>
To summarize: MinIO controls data access by applying policies associated to users, groups or service accounts. Regular S3 users are recommended for humans. Service accounts are recommended for applications.
Conclusion
This post explored the basics of How to Secure MinIO. Conceptually, we have to secure the data ingress, the data at rest and define data access rules. However, we did not go through all the details of each topic but instead focused on some key aspects. If you want to dive deeper, checkout our documentation or join our slack channel to learn from our global community.
In the next post of this series, we will take a look at some more advanced topics, like audit logging and external IDPs.






