Small File Archives in MinIO

MinIO RELEASE.2021-06-14 added an “s3zip” extension that allows downloading individual files from ZIP archives. We will explore the use cases where this is a benefit compared to downloading regular objects, and explain how to use it.
Background
We have previously described how MinIO internally optimizes small objects. However, internally storing individual objects still imposes file system limitations such as slower listing and minimum block size.
Through feedback we found that in certain situations it would be desirable to be able to reference small data segments without the full feature set of individual objects. To make this as easy as possible to use, we added ZIP file indexing.
This feature allows retrieving individual files within ZIP files uploaded to MinIO. With this feature it is possible to upload a single ZIP file that contains thousands of files. A MinIO indexing tool then ensures that accessing a file inside a ZIP file can be done with the same performance as individual objects. All of this is done transparently.
ZIP files are commonly known and well supported across most development platforms, as well as having well-established tools available. In most languages the ZIP format allows for streaming writes, so it doesn’t require all data to be in memory when creating the archive. We choose a common format over a custom built format since it provides the functionality we need. Other formats like TAR do not fulfill the requirements for this, so we do not expect to implement other formats.
Related: The Small Files Problem: Solutions for Big Data
Use Cases
Our main target for this feature is to allow fast upload of many small pieces of data that do not change and allow fast download of individual files. This also has the added benefit of taking up much less space since all data is stored as a single file.
A prime usage example could be weekly/daily/hourly reports that need to be accessed on a per user basis. You might have a data lake where you store ZIP archives of files to be analyzed. File names would then be the ID on which you would like to perform the lookup. With regular objects this would create one object per user per interval. Instead, all content for a given time interval can be uploaded and individual records can be accessed by the ID.
It is not possible to update individual files inside the ZIP file. Therefore this should only be used for data that isn’t expected to change. If the ZIP file is overwritten, all files are replaced atomically at the same time. If you know that you will be modifying the contents of the ZIP file, then don’t use a ZIP file, save the files as regular objects instead.
There is no individual metadata for files inside a zip, only name and size. Modification time is inherited from the parent ZIP object. This means that ILM rules and retention are applied to the ZIP object as a whole.
ZIP compression is secondary, and generally it is recommended to just leave files inside ZIP files uncompressed. This can be set when compressing the files. Individual files can be stored uncompressed or compressed with deflate.
The size in bytes of the archive has little impact on the responsiveness of retrieving individual files. To keep individual requests responsive it is recommended to keep each zip file below 100,000 individual files. If you plan to go above this, we recommend splitting your input into several files, targeting 10,000 files in each.
Benchmarks show that for zip files with 10,000 files, each access takes roughly 1ms. This scales linearly, so with 100,000 files an additional 10ms should be expected per operation, assuming CPU resources are available.
Basic Usage
Working with indexed ZIP files is made possible by an extension to the existing S3 API. To ensure there can be no unintended side-effects, all use is guarded by headers that must be present to enable the new functionality. To enable the extension the header x-minio-extract must have the value true set.
The following API request types support the s3zip extensions: HeadObject, GetObject and ListObjectsV2.This will allow listing files within archives and retrieving them.
Files inside zip files are referenced as /prefix/file.zip/path-in-zip/file.ext. Zip files must have the zip extension and the path within the zip file is used to reference each file.
For example, to list all files in a file uploaded as prefix/file.zip issue a GetObject with prefix prefix/file.zip/. Note how the forward slash indicates content inside the zip file. Prefixes, markers and separators operate as regular ListObjectsV2 calls.
Uploading Files
Uploading files is done through regular functions. No special action is needed for uploading files, except that the object key must end with .zip.
To trigger immediate indexing on upload, it is possible to trigger it by setting the x-minio-extract header to true. If it is not set, the index will be created by the first request mentioned above that retrieves or lists files inside the zip.
Zip64 (zip files above 4GB) is fully supported. Zip files with zip-based encryption are not supported.
Unicode names are supported, and should use UTF-8 encoding. However, there do exist non-compliant compressors that rely on local codepages to work. If you are planning to use Unicode names check if file names are decoded correctly. It is generally recommended to stick to the general object key naming guidelines.
Listing Files
Regular listing operations will return the zip file as a regular object.
To list the content of a zip file, send a prefix containing the zip file as a prefix and the header described above. For example prefix/file.zip/ will list all content of the zip file with the key prefix/file.zip. Regular ListObjectV2 parameters like additional prefix, markers and separators are supported.
For example, listing with prefix = prefix/file.zip/folder/, delimiter = / will list only content within the folder specified.
To keep the complexity low a few limitations are in place: ListObjectV2 must be used. Only a single zip file can be listed per call and only the most recent version of a zip file can be listed.
Downloading Individual Files
As mentioned above, accessing individual files requires a header and a path to indicate the zip file and the file within it. To get the path, ListObjectsV2 can be used. The object name can also be constructed by manually combining the object path with the path inside the zip file.
See examples on how to download files…
Individual files are handled as single requests. This will produce single files at the same speed as separate objects. If you need to access the content of many files within an archive it will be faster to download the entire ZIP archive and process it locally.
MC support
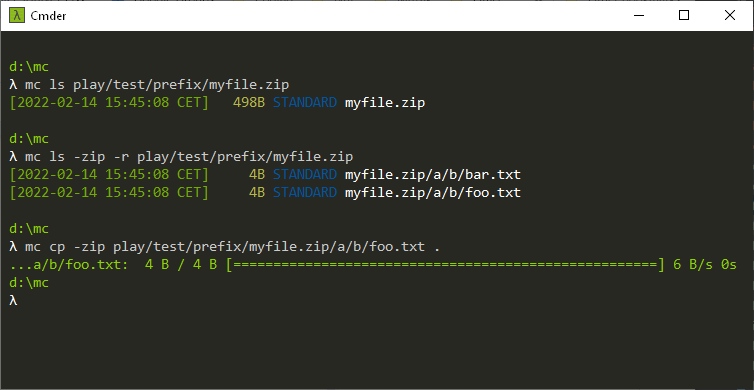
mc RELEASE.2022-02-16 adds support for accessing files inside zip files remotely. Specifically, the ls, cp and cat commands support operations where the source is a remote zip file. These commands have a “--zip” parameter to indicate that you intend the operation to run on zip files.
To list all files inside a zip file, use
λ mc ls --zip -–recursive play/test/test.zip/
This will list all files as regular objects. Individual folders can also be listed:
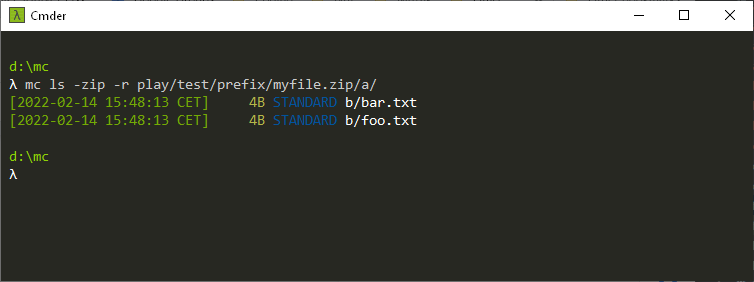
λ mc ls --zip play/test/test.zip/folder/
… will list all files and folders within the folder.
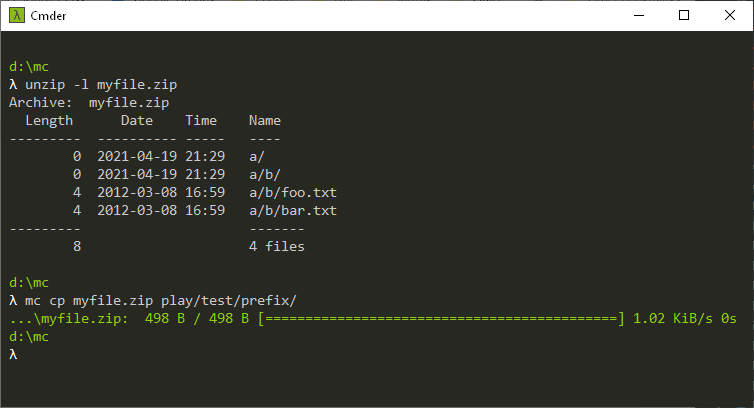
Files can be extracted using the cp command:
λ mc cp --zip play/test/test.zip/file.txt
Files can also be recursively extracted from folders, with the regular syntax:
λ mc cp --zip —-recursive play/test/test.zip/folder/ ./extracted/
Finally, it is possible to display single files inside zip files:
λ mc cat --zip play/test/test.zip/file.txt
This will only work when the remote is a MinIO server running in distributed or Single-Drive-Single-Disk mode.
Conclusion
The s3zip feature allows you to store many small individual files in a compact way. This can be a good alternative to many individual objects, which will reduce the storage overhead and processing time for ILM and other operations.
As with any extension, the usual caveats apply. While it is technically possible to implement a local index and use HTTP range requests to provide similar functionality without any server side support, it would require a considerable effort, and the result would not be as streamlined as what we’ve accomplished with our extension.
For archival purposes this extension provides a much more space and bandwidth efficient method for retrieving rarely accessed archived data through the mc command interface. This can be an effective method for storing log data that you only occasionally need to access. It can be used for fast upload of multiple data segments that need fast access by an ID.
Consider daily user statistics with a userid -> json mapping. When using regular objects this could be implemented as a yyyy/mm/dd/user_id/file.json object naming. This would require uploading an object for each user each day.
Instead a single zip file could be created per day, and user stats could be looked up by reading yyyy-mm-dd.zip/user_id.json - which will be both faster to upload, maintain and take up less space - all good things when working in a data lake.
If there are many users, using a deterministic splitting approach, like yyyy-mm-dd/user0-10000.zip/user_id.json would allow this to scale to billions of users, with 5 orders of magnitude less objects.
Zip Through ZIP Files with MinIO
Download MinIO and take advantage of the ability to list and download individual files from ZIP files. If you have any questions or want to tell us about the great apps you’re building using MinIO, ping us on hello@min.io or join the Slack community.






