How to Set up Kafka and Stream Data to MinIO in Kubernetes

Apache Kafka is an open-source distributed event streaming platform that is used for building real-time data pipelines and streaming applications. It was originally developed by LinkedIn and is now maintained by the Apache Software Foundation. Kafka is designed to handle high volume, high throughput, and low latency data streams, making it a popular choice for building scalable and reliable data streaming solutions.
Some of the benefits of Kafka include:
- Scale and Speed: Handling large-scale data streams and millions of events per second, and .scales horizontally by adding more Kafka brokers to the cluster
- Fault Tolerance: Replicating data across multiple brokers in a Kafka cluster ensures that data is highly available and can be recovered in case of failure, making Kafka a reliable choice for critical data streaming applications
- Versatility: Support for a variety of data sources and data sinks making it highly versatile. It can be used for building a wide range of applications, such as real-time data processing, data ingestion, data streaming, and event-driven architectures
- Durability: All published messages are stored for a configurable amount of time, allowing consumers to read data at their own pace. This makes Kafka suitable where data needs to be retained for historical analysis or replayed for recovery purposes.
Please see Apache Kafka for more information.
Deploying Kafka on Kubernetes, a widely-used container orchestration platform, offers several additional advantages. Kubernetes enables dynamic scaling of Kafka clusters based on demand, allowing for efficient resource utilization and automatic scaling of Kafka brokers to handle changing data stream volumes. This ensures that Kafka can handle varying workloads without unnecessary resource wastage or performance degradation.
It provides easy deployment, management, and monitoring Running Kafka clusters as containers provides easy deployment, management, and monitoring, and makes them highly portable across different environments. This allows for seamless migration of Kafka clusters across various cloud providers, data centers, or development environments.
Kubernetes includes built-in features for handling failures and ensuring high availability of Kafka clusters. For example, it automatically reschedules failed Kafka broker containers and supports rolling updates without downtime, ensuring continuous availability of Kafka for data streaming applications, thereby enhancing the reliability and fault tolerance of Kafka deployments.
Kafka and MinIO are commonly used to build data streaming solutions. MinIO is a high-performance, distributed object storage system designed to support cloud-native applications with S3-compatible storage for unstructured, semi-structured and structured data. When used as a data sink with Kafka, MinIO enables organizations to store and process large volumes of data in real-time.
Some benefits of combining Kafka with MinIO include:
- High Performance: MinIO writes Kafka streams as fast as they come in. MinIO has created a comprehensive blueprint for data infrastructure to support exascale AI and other large scale data lake workloads. It is called the MinIO DataPod. Why? Because exascale data is the reality that is common today in today's enterprise.
- Scalability: MinIO handles large amounts of data and scales horizontally across multiple nodes, making it a perfect fit for storing data streams generated by Kafka. This allows organizations to store and process massive amounts of data in real-time, making it suitable for big data and high-velocity data streaming use cases.
- Durability: MinIO provides durable storage, allowing organizations to retain data for long periods of time, such as for historical analysis, compliance requirements, or data recovery purposes.
- Fault Tolerance: MinIO erasure codes data across multiple nodes, providing fault tolerance and ensuring data durability. This complements Kafka's fault tolerance capabilities, making the overall solution highly available, reliable and resilient.
- Easy Integration: MinIO is easily integrated with Kafka using Kafka Connect, a built-in framework for connecting Kafka with external systems. This makes it straightforward to stream data from Kafka to MinIO for storage, and vice versa for data retrieval, enabling seamless data flow between Kafka and MinIO. We’ll see how straightforward this is in the tutorial below.
In this post, we will walk through how to set up Kafka on Kubernetes using Strimzi, an open-source project that provides operators to run Apache Kafka and Apache ZooKeeper clusters on Kubernetes, including distributions such as OpenShift. Then we will use Kafka Connect to stream data to MinIO.
Prerequisites
Before we start, ensure that you have the following:
- A running Kubernetes cluster
- kubectl command-line tool
- A running MinIO cluster
- mc command line tool for MinIO
- Helm package manager
Install Strimzi Operator
The first step is to install the Strimzi operator on your Kubernetes cluster. The Strimzi operator manages the lifecycle of Kafka and ZooKeeper clusters on Kubernetes.
Add the Strimzi Helm chart repository
Install the chart with release name my-release:
This installs the latest version (0.34.0 at the time of this writing) of the operator in the newly created kafka namespace. For additional configurations refer to this page.
Create Kafka Cluster
Now that we have installed the Strimzi operator, we can create a Kafka cluster. In this example, we will create a Kafka cluster with three Kafka brokers and three ZooKeeper nodes.
Lets create a YAML file as shown here
Let's create the cluster by deploying the YAML file. We’re deploying a cluster, so it will take some time before it is up and running
Check the status of the cluster with
!kubectl -n kafka get kafka my-kafka-cluster
NAME DESIRED KAFKA REPLICAS DESIRED ZK REPLICAS READY WARNINGS
my-kafka-cluster 3 3 True Now that we have the cluster up and running, let’s produce and consume sample topic events, starting with the kafka topic my-topic.
Create Kafka Topic
Create a YAML file for the kafka topic my-topic as shown below and apply it.
Check the status of the topic with
Produce and Consume Messages
With the Kafka cluster and topic set up, we can now produce and consume messages.
To create a Kafka producer pod to produce messages to the my-topic topic, try the below commands in a terminal
This will give us a prompt to send messages to the producer. In parallel, we can bring up the consumer to start consuming the messages that we sent to producer
The consumer will replay all the messages that we sent to the producer earlier and, if we add any new messages to the producer, they will also start showing up at the consumer side.
You can delete the my-topic topic with
Now that the Kafka cluster is up and running with a dummy topic producer/consumer, we can start consuming topics directly into MinIO using the Kafka Connector.
Set Up Kafka Connector with MinIO
Next we will use the Kafka Connector to stream topics directly to MinIO. First let's look at what connectors are and how to set one up. Here is an high level overview of how the different Kafka Components interact
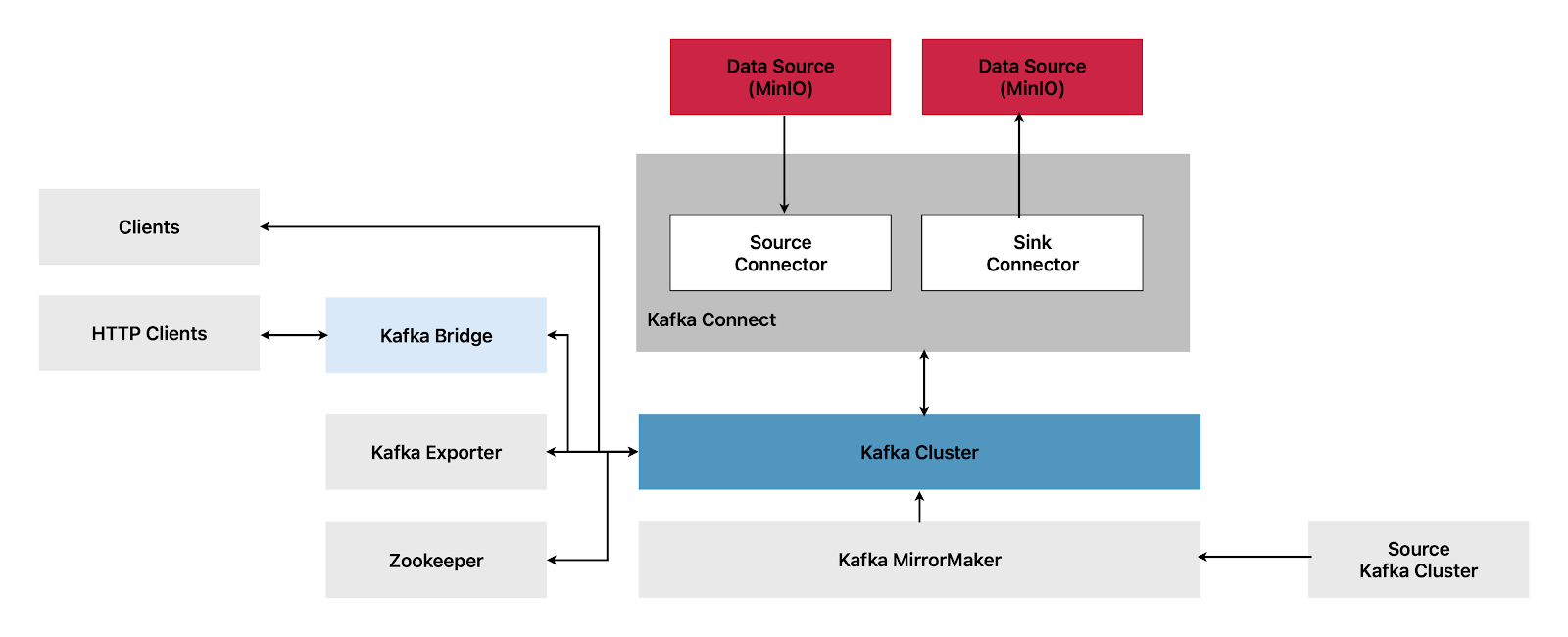
Kafka Connectors
Kafka Connect is an integration toolkit for streaming data between Kafka brokers and other systems. The other system is typically an external data source or target, such as MinIO.
Kafka Connect utilizes a plugin architecture to provide implementation artifacts for connectors, which are used for connecting to external systems and manipulating data. Plugins consist of connectors, data converters, and transforms. Connectors are designed to work with specific external systems and define a schema for their configuration. When configuring Kafka Connect, you configure the connector instance, and the connector instance then defines a set of tasks for data movement between systems.
In the distributed mode of operation, Strimzi operates Kafka Connect by distributing data streaming tasks across one or more worker pods. A Kafka Connect cluster consists of a group of worker pods, with each connector instantiated on a single worker. Each connector can have one or more tasks that are distributed across the group of workers, enabling highly scalable data pipelines.
Workers in Kafka Connect are responsible for converting data from one format to another, making it suitable for the source or target system. Depending on the configuration of the connector instance, workers may also apply transforms, also known as Single Message Transforms (SMTs), which can adjust messages, such as by filtering certain data, before they are converted. Kafka Connect comes with some built-in transforms, but additional transformations can be provided by plugins as needed.
Kafka Connect uses the following components while streaming data
- Connectors - create tasks
- Tasks - move data
- Workers - run tasks
- Transformers - manipulate data
- Converters - convert data
There are 2 types of Connectors
- Source Connectors - push data into Kafka
- Sink Connectors - extracts data from Kafka to external source like MinIO
Let’s configure a Sink Connector that extracts data from Kafka and stores it into MinIO as shown below
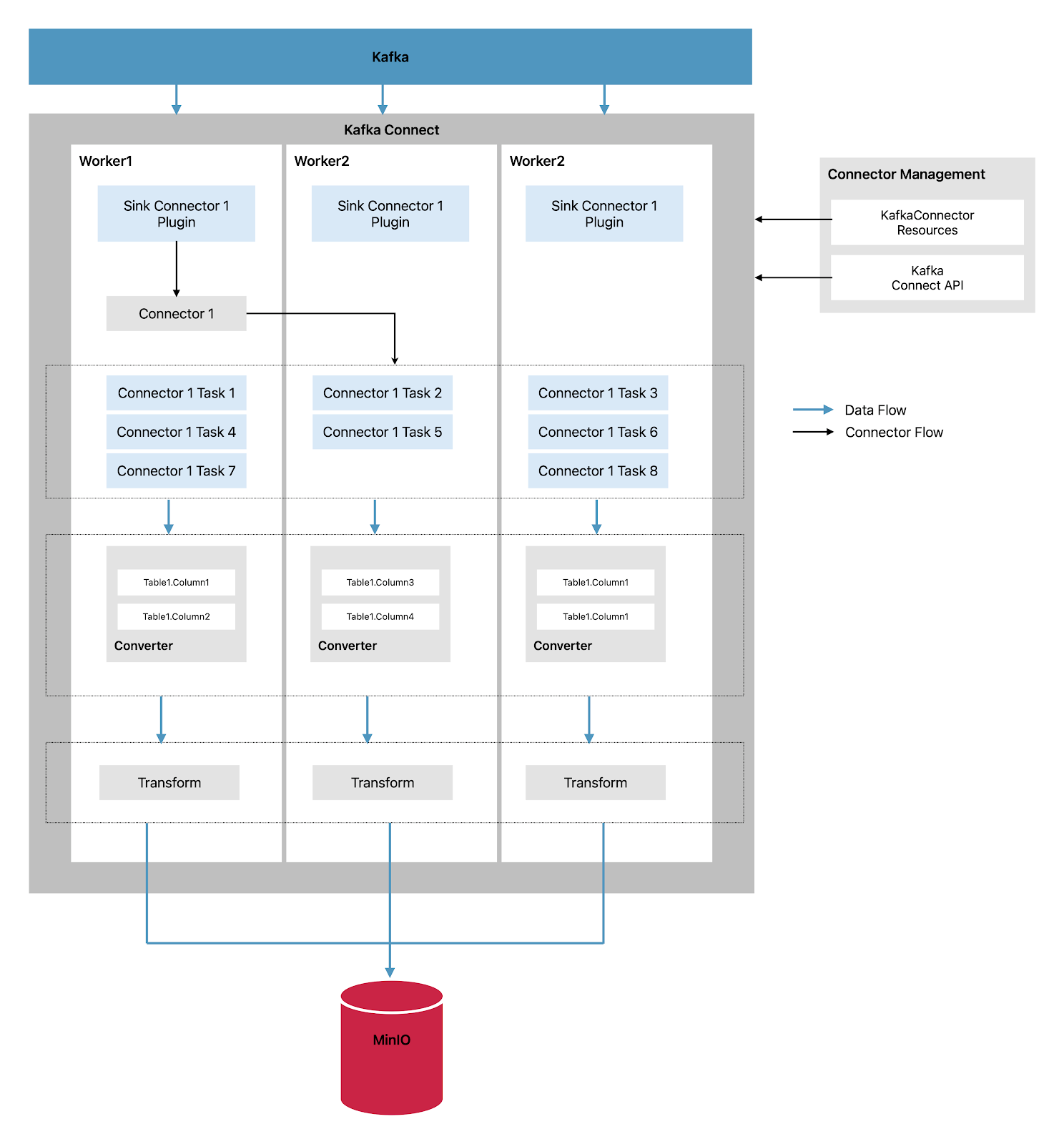
The Sink Connector streams data from Kafka and goes through following steps
- A plugin provides the implementation artifacts for the Sink Connector: In Kafka Connect, a Sink Connector is used to stream data from Kafka to an external system. The implementation artifacts for the Sink Connector, such as the code and configuration, are provided by a plugin. Plugins are used to extend the functionality of Kafka Connect and enable connections to different external data systems.
- A single worker initiates the Sink Connector instance: In a distributed mode of operation, Kafka Connect runs as a cluster of worker pods. Each worker pod can initiate a Sink Connector instance, which is responsible for streaming data from Kafka to the external data system. The worker manages the lifecycle of the Sink Connector instance, including its initialization and configuration.
- The Sink Connector creates tasks to stream data: Once the Sink Connector instance is initiated, it creates one or more tasks to stream data from Kafka to the external data system. Each task is responsible for processing a portion of the data and can run in parallel with other tasks for efficient data processing.
- Tasks run in parallel to poll Kafka and return records: The tasks retrieve records from Kafka topics and prepare them for forwarding to the external data system. The parallel processing of tasks enables high throughput and efficient data streaming.
- Converters put the records into a format suitable for the external data system: Before forwarding the records to the external data system, converters are used to put the records into a format that is suitable for the specific requirements of the external data system. Converters handle data format conversion, such as from Kafka's binary format to a format supported by the external data system.
- Transforms adjust the records, such as filtering or relabeling them: Depending on the configuration of the Sink Connector, transformations, Single Message Transforms (SMTs), can be applied to adjust the records before they are forwarded to the external data system. Transformations can be used for tasks such as filtering, relabeling, or enriching the data to be sent to the external system.
- The sink connector is managed using KafkaConnectors or the Kafka Connect API: The Sink Connector, along with its tasks, is managed using KafkaConnectors, or through the Kafka Connect API, which provides programmatic access for managing Kafka Connect. This allows for easy configuration, monitoring, and management of Sink Connectors and their tasks in a Kafka Connect deployment.
Setup
We will create a simple example which will perform the following steps
- Create a Producer that will stream data from MinIO and produce events for a topic in JSON format
- Build a Kafka Connect Image that has S3 dependencies
- Deploy the Kafka Connect based on the above image
- Deploy Kafka sink connector that consumes kafka topic and stores the data MinIO bucket
Getting Demo Data into MinIO
We will be using the NYC Taxi dataset that is available on MinIO. If you don't have the dataset follow the instructions here
Producer
Below is a simple Python code that consumes data from MinIO and produces events for the topic my-topic
Overwriting sample-code/src/producer.py
adds requirements and Dockerfile based on which we will build the docker image
Overwriting sample-code/producer/requirements.txt
Overwriting sample-code/Dockerfile
Build and push the Docker image for the producer using the above Docker file or you can use the one available in openlake openlake/kafka-demo-producer
Let's create a YAML file that deploys our producer in the Kubernetes cluster as a job
Writing deployment/producer.yaml
Deploy the producer.yaml file
Check the logs by using the below command
Now that we have our basic producer sending JSON events to my-topic, let’s deploy Kafka Connect and the corresponding Connector that stores these events in MinIO.
Build Kafka Connect Image
Let's build a Kafka Connect image that has S3 dependencies
Overwriting sample-code/connect/Dockerfile
Build and push the Docker image for the producer using the above Dockerfile or can use the one available in openlake openlake/kafka-connect:0.34.0
Before we deploy Kafka Connect, we need to create storage topics if not already present for Kafka Connect to work as expected.
Create Storage Topics
Lets create connect-status, connect-configs and connect-offsets topics and deploy them as shown below
Writing deployment/connect-status-topic.yaml
Writing deployment/connect-configs-topic.yaml
Writing deployment/connect-offsets-topic.yaml
Deploy above topics
Deploy Kafka Connect
Next, create a YAML file for Kafka Connect that uses the above image and deploys it in Kubernetes. Kafka Connect will have 1 replica and make use of the storage topics we created above.
NOTE: spec.template.connectContainer.env has the credentials defined in order for Kafka Connect to store data in the Minio cluster. Other details like the endpoint_url, bucket_name will be part of KafkaConnector
Writing deployment/connect.yaml
Deploy Kafka Sink Connector
Now that we have Kafka Connect up and running, the next step is to deploy the Sink Connector that will poll my-topic and store data into the MinIO bucket openlake-tmp.
connector.class - specifies what type of connector the Sink Connector will use, in our case it is io.confluent.connect.s3.S3SinkConnector
store.url - MinIO endpoint URL where you want to store the data from Kafka Connect
storage.class - specifies which storage class to use, in our case we are storing in MinIO so io.confluent.connect.s3.storage.S3Storage will be used
format.class - Format type to store data in MinIO, since we would like to store JSON we will use io.confluent.connect.s3.format.json.JsonFormat
Overwriting deployment/connector.yaml
We can see files being added to the Minio openlake-tmp bucket with
We createdan end-to-end implementation of producing topics in Kafka and consuming it directly into MinIO using the Kafka Connectors. This is a great start learning how to use MinIO and Kafka together to build a streaming data repository. But wait, there’s more.
In my next post, I explain and show you how to take this tutorial and turn it into something that is a lot more efficient and performant.
Achieve Streaming Success with Kafka and MinIO
This blog post showed you how to get started building a streaming data lake. Of course, there are many more steps involved between this beginning and production.
MinIO is cloud-native object storage that forms the foundation for ML/AI, analytics, streaming video, and other demanding workloads running in Kubernetes. MinIO scales seamlessly, ensuring that you can simply expand storage to accommodate a growing data lake.
Customers frequently build data lakes using MinIO and expose them to a variety of cloud-native applications for business intelligence, dashboarding and other analysis. They build them using Apache Iceberg, Apache Hudi and Delta Lake. They use Snowflake, SQL Server, or a variety of databases to read data saved in MinIO as external tables. And they use Dremio, Apache Druid and Clickhouse for analytics, and Kubeflow and Tensorflow for ML.
MinIO can even replicate data between clouds to leverage specific applications and frameworks, while it is protected using access control, version control, encryption and erasure coding.
Don’t take our word for it though — build it yourself. You can download MinIO and you can join our Slack channel.






