Building Streaming Data Lakes with Hudi and MinIO


Apache Hudi is a streaming data lake platform that brings core warehouse and database functionality directly to the data lake. Not content to call itself an open file format like Delta or Apache Iceberg, Hudi provides tables, transactions, upserts/deletes, advanced indexes, streaming ingestion services, data clustering/compaction optimizations, and concurrency.
Introduced in 2016, Hudi is firmly rooted in the Hadoop ecosystem, accounting for the meaning behind the name: Hadoop Upserts anD Incrementals. It was developed to manage the storage of large analytical datasets on HDFS. Hudi’s primary purpose is to decrease latency during ingestion of streaming data.

Over time, Hudi has evolved to use cloud storage and object storage, including MinIO. Hudi’s shift away from HDFS goes hand-in-hand with the larger trend of the world leaving behind legacy HDFS for performant, scalable, and cloud-native object storage. Hudi’s promise of providing optimizations that make analytic workloads faster for Apache Spark, Flink, Presto, Trino, and others dovetails nicely with MinIO’s promise of cloud-native application performance at scale.
Companies using Hudi in production include Uber, Amazon, ByteDance, and Robinhood. These are some of the largest streaming data lakes in the world. The key to Hudi in this use case is that it provides an incremental data processing stack that conducts low-latency processing on columnar data. Typically, systems write data out once using an open file format like Apache Parquet or ORC, and store this on top of highly scalable object storage or distributed file system. Hudi serves as a data plane to ingest, transform, and manage this data. Hudi interacts with storage using the Hadoop FileSystem API, which is compatible with (but not necessarily optimal for) implementations ranging from HDFS to object storage to in-memory file systems.
Hudi file format
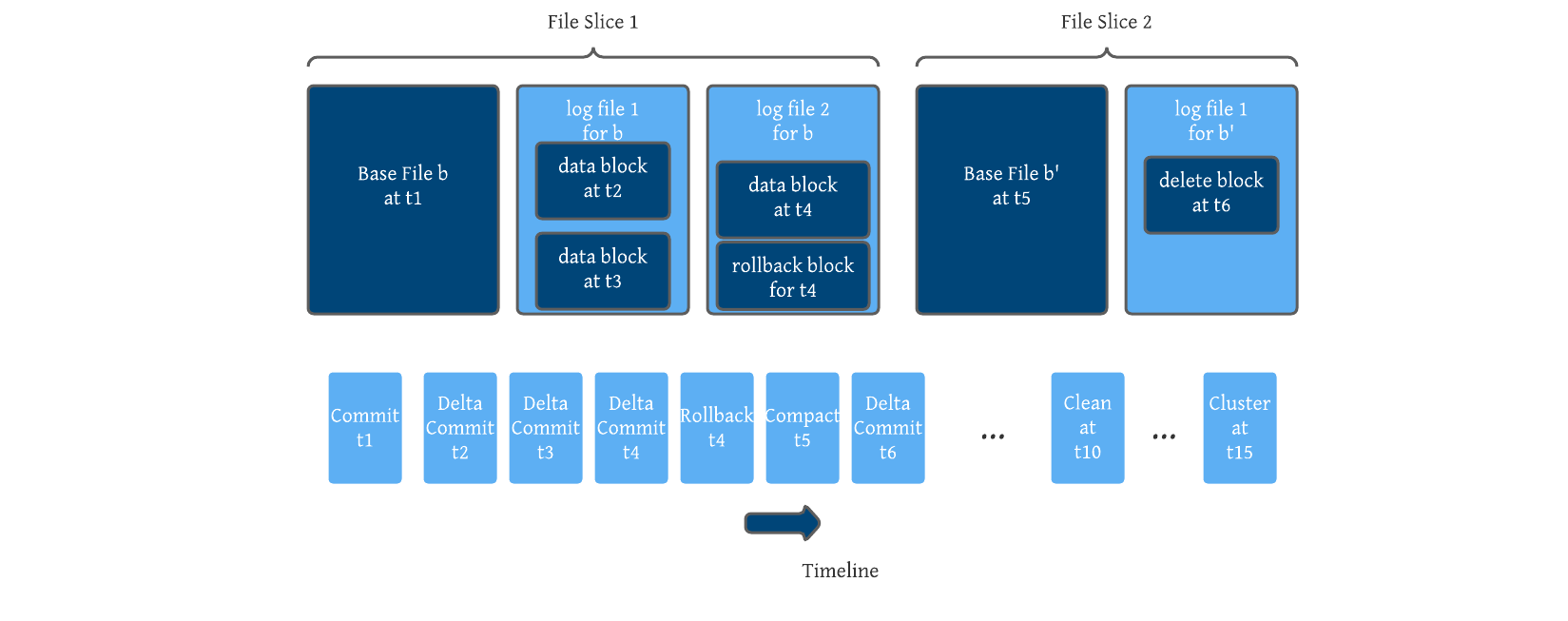
Hudi uses a base file and delta log files that store updates/changes to a given base file. Base files can be Parquet (columnar) or HFile (indexed). The delta logs are saved as Avro (row) because it makes sense to record changes to the base file as they occur.
Hudi encodes all changes to a given base file as a sequence of blocks. Blocks can be data blocks, delete blocks, or rollback blocks. These blocks are merged in order to derive newer base files. This encoding also creates a self-contained log.
Hudi table format
A table format consists of the file layout of the table, the table’s schema, and the metadata that tracks changes to the table. Hudi enforces schema-on-write, consistent with the emphasis on stream processing, to ensure pipelines don’t break from non-backwards-compatible changes.
Hudi groups files for a given table/partition together, and maps between record keys and file groups. As mentioned above, all updates are recorded into the delta log files for a specific file group. This design is more efficient than Hive ACID, which must merge all data records against all base files to process queries. Hudi’s design anticipates fast key-based upserts and deletes as it works with delta logs for a file group, not for an entire dataset.
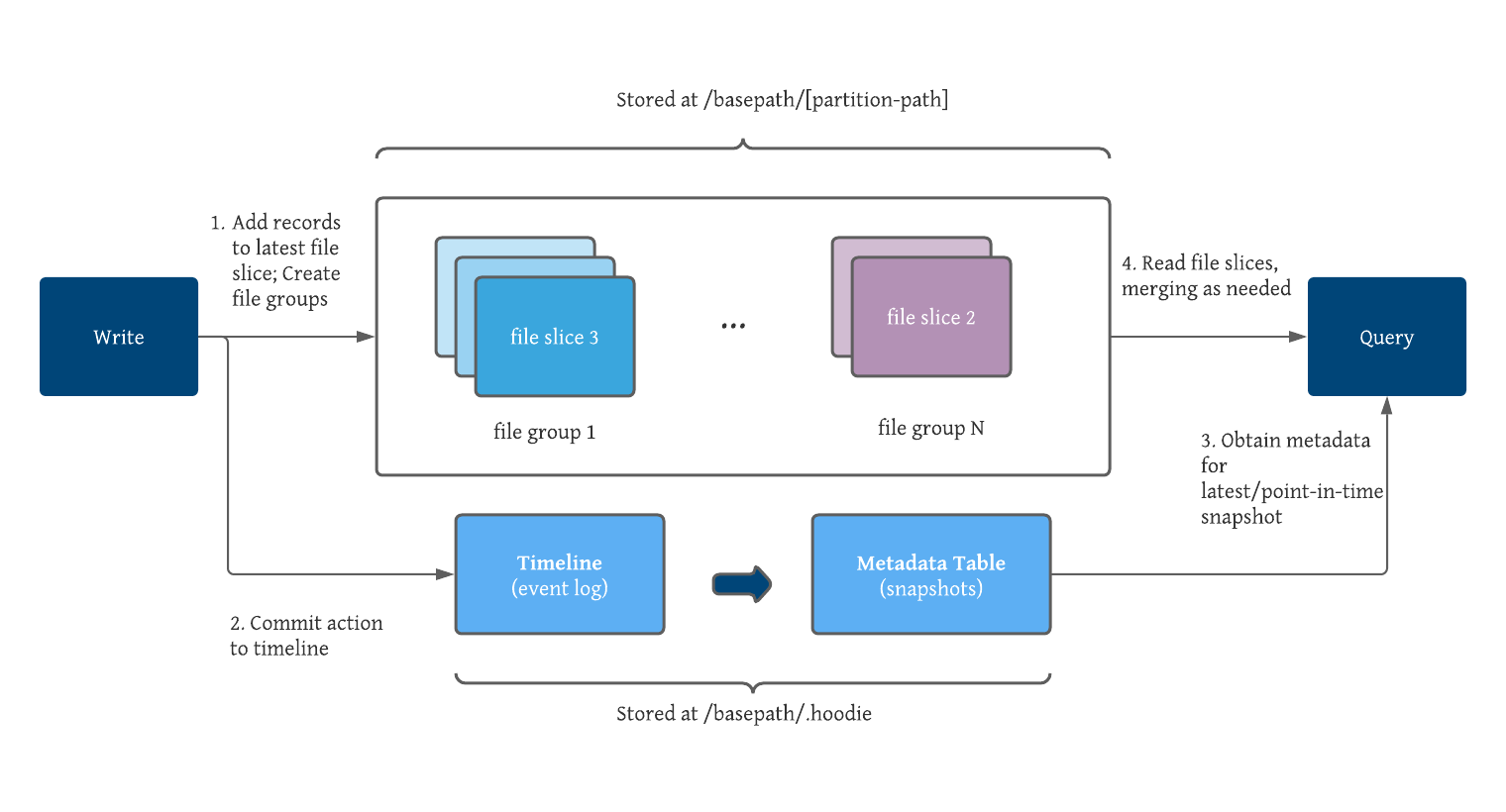
The timeline is critical to understand because it serves as a source of truth event log for all of Hudi’s table metadata. The timeline is stored in the .hoodie folder, or bucket in our case. Events are retained on the timeline until they are removed. The timeline exists for an overall table as well as for file groups, enabling reconstruction of a file group by applying the delta logs to the original base file. In order to optimize for frequent writes/commits, Hudi’s design keeps metadata small relative to the size of the entire table.
New events on the timeline are saved to an internal metadata table and implemented as a series of merge-on-read tables, thereby providing low write amplification. As a result, Hudi can quickly absorb rapid changes to metadata. In addition, the metadata table uses the HFile base file format, further optimizing performance with a set of indexed lookups of keys that avoids the need to read the entire metadata table. All physical file paths that are part of the table are included in metadata to avoid expensive time-consuming cloud file listings.
Hudi writers
Hudi writers facilitate architectures where Hudi serves as a high-performance write layer with ACID transaction support that enables very fast incremental changes such as updates and deletes.
A typical Hudi architecture relies on Spark or Flink pipelines to deliver data to Hudi tables. The Hudi writing path is optimized to be more efficient than simply writing a Parquet or Avro file to disk. Hudi analyzes write operations and classifies them as incremental (insert, upsert, delete) or batch operations (insert_overwrite, insert_overwrite_table, delete_partition, bulk_insert ) and then applies necessary optimizations.
Hudi writers are also responsible for maintaining metadata. For each record, the commit time and a sequence number unique to that record (this is similar to a Kafka offset) are written making it possible to derive record level changes. Users can also specify event time fields in incoming data streams and track them using metadata and the Hudi timeline. This can have dramatic improvements on stream processing as Hudi contains both the arrival and the event time for each record, making it possible to build strong watermarks for complex stream processing pipelines.
Hudi readers
Snapshot isolation between writers and readers allows for table snapshots to be queried consistently from all major data lake query engines, including Spark, Hive, Flink, Prest, Trino and Impala. As Parquet and Avro, Hudi tables can be read as external tables by the likes of Snowflake and SQL Server.
Hudi readers are developed to be lightweight. Wherever possible, engine-specific vectorized readers and caching, such as those in Presto and Spark, are used. When Hudi has to merge base and log files for a query, Hudi improves merge performance using mechanisms like spillable maps and lazy reading, while also providing read-optimized queries.
Hudi includes more than a few remarkably powerful incremental querying capabilities. Metadata is at the core of this, allowing large commits to be consumed as smaller chunks and fully decoupling the writing and incremental querying of data. Through efficient use of metadata, time travel is just another incremental query with a defined start and stop point. Hudi atomically maps keys to single file groups at any given point in time, supporting full CDC capabilities on Hudi tables. As discussed above in the Hudi writers section, each table is composed of file groups, and each file group has its own self-contained metadata.
Hooray for Hudi!
Hudi’s greatest strength is the speed with which it ingests both streaming and batch data. By providing the ability to upsert, Hudi executes tasks orders of magnitudes faster than rewriting entire tables or partitions.
To take advantage of Hudi’s ingestion speed, data lakehouses require a storage layer capable of high IOPS and throughput. MinIO’s combination of scalability and high-performance is just what Hudi needs. MinIO is more than capable of the performance required to power a real-time enterprise data lake — a recent benchmark achieved 325 GiB/s (349 GB/s) on GETs and 165 GiB/s (177 GB/s) on PUTs with just 32 nodes of off-the-shelf NVMe SSDs.
An active enterprise Hudi data lake stores massive numbers of small Parquet and Avro files. MinIO includes a number of small file optimizations that enable faster data lakes. Small objects are saved inline with metadata, reducing the IOPS needed both to read and write small files like Hudi metadata and indices.
Schema is a critical component of every Hudi table. Hudi can enforce schema, or it can allow schema evolution so the streaming data pipeline can adapt without breaking. In addition, Hudi enforces schema-on-writer to ensure changes don’t break pipelines. Hudi relies on Avro to store, manage and evolve a table’s schema.
Hudi provides ACID transactional guarantees to data lakes. Hudi ensures atomic writes: commits are made atomically to a timeline and given a time stamp that denotes the time at which the action is deemed to have occurred. Hudi isolates snapshots between writer, table, and reader processes so each operates on a consistent snapshot of the table. Hudi rounds this out with optimistic concurrency control (OCC) between writers and non-blocking MVCC-based concurrency control between table services and writers and between multiple table services.
Hudi and MinIO tutorial
This tutorial will walk you through setting up Spark, Hudi, and MinIO and introduce some basic Hudi features. This tutorial is based on the Apache Hudi Spark Guide, adapted to work with cloud-native MinIO object storage.
Note that working with versioned buckets adds some maintenance overhead to Hudi. Any object that is deleted creates a delete marker. As Hudi cleans up files using the Cleaner utility, the number of delete markers increases over time. It is important to configure Lifecycle Management correctly to clean up these delete markers as the List operation can choke if the number of delete markers reaches 1000. Hudi project maintainers recommend cleaning up delete markers after one day using lifecycle rules.
Prerequisites
Download and install Apache Spark.
Download and install MinIO. Record the IP address, TCP port for the console, access key, and secret key.
Download and install MinIO Client.
Download the AWS and AWS Hadoop libraries and add them to your classpath in order to use S3A to work with object storage.
- AWS:
aws-java-sdk:1.10.34(or higher) - Hadoop:
hadoop-aws:2.7.3(or higher)
Download the Jar files, unzip them and copy them to /opt/spark/jars.
Create a MinIO bucket
Use the MinIO Client to create a bucket to house Hudi data:
mc alias set myminio http://<your-MinIO-IP:port> <your-MinIO-access-key> <your-MinIO-secret-key>
mc mb myminio/hudiLaunch Spark with Hudi
Start the Spark shell with Hudi configured to use MinIO for storage. Make sure to configure entries for S3A with your MinIO settings.
spark-shell \
--packages org.apache.hudi:hudi-spark3.3-bundle_2.12:0.12.0,org.apache.hadoop:hadoop-aws:3.3.4 \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension' \
--conf 'spark.hadoop.fs.s3a.access.key=<your-MinIO-access-key>' \
--conf 'spark.hadoop.fs.s3a.secret.key=<your-MinIO-secret-key>'\
--conf 'spark.hadoop.fs.s3a.endpoint=<your-MinIO-IP>:9000' \
--conf 'spark.hadoop.fs.s3a.path.style.access=true' \
--conf 'fs.s3a.signing-algorithm=S3SignerType'Then, initialize Hudi within Spark.
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.common.model.HoodieRecordNote that it will simplify repeated use of Hudi to create an external config file.
Create a table
Try it out and create a simple small Hudi table using Scala. The Hudi DataGenerator is a quick and easy way to generate sample inserts and updates based on the sample trip schema.
val tableName = "hudi_trips_cow"
val basePath = "s3a://hudi/hudi_trips_cow"
val dataGen = new DataGeneratorInsert data into Hudi and write table to MinIO
The following will generate new trip data, load them into a DataFrame and write the DataFrame we just created to MinIO as a Hudi table. mode(Overwrite) overwrites and recreates the table in the event that it already exists. The trips data relies on a record key (uuid), partition field (region/country/city) and logic (ts) to ensure trip records are unique for each partition. We will use the default write operation, upsert. When you have a workload without updates, you could use insert or bulk_insert which could be faster.
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Overwrite).
save(basePath)Open a browser and log into MinIO at http://<your-MinIO-IP>:<port> with your access key and secret key. You will see the Hudi table in the bucket.

The bucket also contains a .hoodie path that contains metadata, and americas and asia paths that contain data.

Take a look at the metadata. This is what my .hoodie path looks like after completing the entire tutorial. We can see that I modified the table on Tuesday September 13, 2022 at 9:02, 10:37, 10:48, 10:52 and 10:56.

Query data
Let’s load Hudi data into a DataFrame and run an example query.
// spark-shell
val tripsSnapshotDF = spark.
read.
format("hudi").
load(basePath)
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
spark.sql("select fare, begin_lon, begin_lat, ts from hudi_trips_snapshot where fare > 20.0").show()
spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot").show()Time travel with Hudi
No, we’re not talking about going to see a Hootie and the Blowfish concert in 1988.
Every write to Hudi tables creates new snapshots. Think of snapshots as versions of the table that can be referenced for time travel queries.
Try out a few time travel queries (you will have to change timestamps to be relevant for you).
spark.read.
format("hudi").
option("as.of.instant", "2022-09-13 09:02:08.200").
load(basePath)Update data
This process is similar to when we inserted new data earlier. To showcase Hudi’s ability to update data, we’re going to generate updates to existing trip records, load them into a DataFrame and then write the DataFrame into the Hudi table already saved in MinIO.
Note that we’re using the append save mode. A general guideline is to use append mode unless you are creating a new table so no records are overwritten. A typical way of working with Hudi is to ingest streaming data in real-time, appending them to the table, and then write some logic that merges and updates existing records based on what was just appended. Alternatively, writing using overwrite mode deletes and recreates the table if it already exists.
// spark-shell
val updates = convertToStringList(dataGen.generateUpdates(10))
val df = spark.read.json(spark.sparkContext.parallelize(updates, 2))
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)Querying the data will show the updated trip records.
Incremental query
Hudi can provide a stream of records that changed since a given timestamp using incremental querying. All we need to do is provide a start time from which changes will be streamed to see changes up through the current commit, and we can use an end time to limit the stream.
Incremental query is a pretty big deal for Hudi because it allows you to build streaming pipelines on batch data.
// spark-shell
// reload data
spark.
read.
format("hudi").
load(basePath).
createOrReplaceTempView("hudi_trips_snapshot")
val commits = spark.sql("select distinct(_hoodie_commit_time) as commitTime from hudi_trips_snapshot order by commitTime").map(k => k.getString(0)).take(50)
val beginTime = commits(commits.length - 2) // commit time we are interested in
// incrementally query data
val tripsIncrementalDF = spark.read.format("hudi").
option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).
option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).
load(basePath)
tripsIncrementalDF.createOrReplaceTempView("hudi_trips_incremental")
spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_incremental where fare > 20.0").show()Point in time query
Hudi can query data as of a specific time and date.
// spark-shell
val beginTime = "000" // Represents all commits > this time.
val endTime = commits(commits.length - 2) // commit time we are interested in
//incrementally query data
val tripsPointInTimeDF = spark.read.format("hudi").
option(QUERY_TYPE_OPT_KEY, QUERY_TYPE_INCREMENTAL_OPT_VAL).
option(BEGIN_INSTANTTIME_OPT_KEY, beginTime).
option(END_INSTANTTIME_OPT_KEY, endTime).
load(basePath)
tripsPointInTimeDF.createOrReplaceTempView("hudi_trips_point_in_time")
spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_trips_point_in_time where fare > 20.0").show()Deleting data with soft deletes
Hudi supports two different ways to delete records. A soft delete retains the record key and nulls out the values for all other fields. Soft deletes are persisted in MinIO and only removed from the data lake using a hard delete.
// spark-shell
spark.
read.
format("hudi").
load(basePath).
createOrReplaceTempView("hudi_trips_snapshot")
// fetch total records count
spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()
spark.sql("select uuid, partitionpath from hudi_trips_snapshot where rider is not null").count()
// fetch two records for soft deletes
val softDeleteDs = spark.sql("select * from hudi_trips_snapshot").limit(2)
// prepare the soft deletes by ensuring the appropriate fields are nullified
val nullifyColumns = softDeleteDs.schema.fields.
map(field => (field.name, field.dataType.typeName)).
filter(pair => (!HoodieRecord.HOODIE_META_COLUMNS.contains(pair._1)
&& !Array("ts", "uuid", "partitionpath").contains(pair._1)))
val softDeleteDf = nullifyColumns.
foldLeft(softDeleteDs.drop(HoodieRecord.HOODIE_META_COLUMNS: _*))(
(ds, col) => ds.withColumn(col._1, lit(null).cast(col._2)))
// simply upsert the table after setting these fields to null
softDeleteDf.write.format("hudi").
options(getQuickstartWriteConfigs).
option(OPERATION_OPT_KEY, "upsert").
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)
// reload data
spark.
read.
format("hudi").
load(basePath).
createOrReplaceTempView("hudi_trips_snapshot")
// This should return the same total count as before
spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()
// This should return (total - 2) count as two records are updated with nulls
spark.sql("select uuid, partitionpath from hudi_trips_snapshot where rider is not null").count()Deleting data with hard deletes
In contrast, hard deletes are what we think of as deletes. The record key and associated fields are removed from the table.
// spark-shell
// fetch total records count
spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()
// fetch two records to be deleted
val ds = spark.sql("select uuid, partitionpath from hudi_trips_snapshot").limit(2)
// issue deletes
val deletes = dataGen.generateDeletes(ds.collectAsList())
val hardDeleteDf = spark.read.json(spark.sparkContext.parallelize(deletes, 2))
hardDeleteDf.write.format("hudi").
options(getQuickstartWriteConfigs).
option(OPERATION_OPT_KEY,"delete").
option(PRECOMBINE_FIELD_OPT_KEY, "ts").
option(RECORDKEY_FIELD_OPT_KEY, "uuid").
option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
option(TABLE_NAME, tableName).
mode(Append).
save(basePath)
// run the same read query as above.
val roAfterDeleteViewDF = spark.
read.
format("hudi").
load(basePath)
roAfterDeleteViewDF.registerTempTable("hudi_trips_snapshot")
// fetch should return (total - 2) records
spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count()Insert overwrite
The data lake becomes a data lakehouse when it gains the ability to update existing data. We’re going to generate some new trip data and then overwrite our existing data. This operation is faster than an upsert where Hudi computes the entire target partition at once for you. Here we specify configuration in order to bypass the automatic indexing, precombining and repartitioning that upsert would do for you.
// spark-shell
spark.
read.format("hudi").
load(basePath).
select("uuid","partitionpath").
sort("partitionpath","uuid").
show(100, false)
val inserts = convertToStringList(dataGen.generateInserts(10))
val df = spark.
read.json(spark.sparkContext.parallelize(inserts, 2)).
filter("partitionpath = 'americas/united_states/san_francisco'")
df.write.format("hudi").
options(getQuickstartWriteConfigs).
option(OPERATION.key(),"insert_overwrite").
option(PRECOMBINE_FIELD.key(), "ts").
option(RECORDKEY_FIELD.key(), "uuid").
option(PARTITIONPATH_FIELD.key(), "partitionpath").
option(TBL_NAME.key(), tableName).
mode(Append).
save(basePath)
// Should have different keys now for San Francisco alone, from query before.
spark.
read.format("hudi").
load(basePath).
select("uuid","partitionpath").
sort("partitionpath","uuid").
show(100, false)Evolve table schema and partitioning
Schema evolution allows you to change a Hudi table’s schema to adapt to changes that take place in the data over time.
Below are some examples of how to query and evolve schema and partitioning. For a more in-depth discussion, please see Schema Evolution | Apache Hudi. Note that if you run these commands, they will alter your Hudi table schema to differ from this tutorial.
-- Alter table name
ALTER TABLE oldTableName RENAME TO newTableName
-- Alter table add columns
ALTER TABLE tableIdentifier ADD COLUMNS(colAndType (,colAndType)*)
-- Alter table column type
ALTER TABLE tableIdentifier CHANGE COLUMN colName colName colType
-- Alter table properties
ALTER TABLE tableIdentifier SET TBLPROPERTIES (key = 'value')
#Alter table examples
--rename to:
ALTER TABLE hudi_cow_nonpcf_tbl RENAME TO hudi_cow_nonpcf_tbl2;
--add column:
ALTER TABLE hudi_cow_nonpcf_tbl2 add columns(remark string);
--change column:
ALTER TABLE hudi_cow_nonpcf_tbl2 change column uuid uuid bigint;
--set properties;
alter table hudi_cow_nonpcf_tbl2 set tblproperties (hoodie.keep.max.commits = '10');Currently, SHOW partitions only works on a file system, as it is based on the file system table path.
This tutorial used Spark to showcase the capabilities of Hudi. However, Hudi can support multiple table types/query types and Hudi tables can be queried from query engines like Hive, Spark, Presto, and much more. The Hudi project has a demo video that showcases all of this on a Docker-based setup with all dependent systems running locally.
Hoot! Hoot! Let’s build Hudi data lakes on MinIO!
Apache Hudi was the first open table format for data lakes, and is worthy of consideration in streaming architectures. The Hudi community and ecosystem are alive and active, with a growing emphasis around replacing Hadoop/HDFS with Hudi/object storage for cloud-native streaming data lakes. Using MinIO for Hudi storage paves the way for multi-cloud data lakes and analytics. MinIO includes active-active replication to synchronize data between locations — on-premise, in the public/private cloud and at the edge — enabling the great stuff enterprises need like geographic load balancing and fast hot-hot failover.
Try Hudi on MinIO today. If you have any questions or want to share tips, please reach out through our Slack channel.