Supercharging Inference for AI Factories: KV Cache Offload as a Memory-Hierarchy Problem

Summary for Skimmers
For end users, inference quality is defined by performance consistency and responsiveness. In modern large language model systems, delivering that experience depends less on “traffic” and more on how effectively KV cache pressure is managed as input sequence lengths, context sizes and concurrency grow.
As a result, the constraint on user experience is no longer raw GPU compute. It is whether the inference stack can sustain growing model state without cascading cache eviction, recomputation, and tail-latency spikes. This piece explains why KV cache offload must be treated as a memory-hierarchy design problem, not a storage optimization, and why that distinction directly determines latency predictability, concurrency limits, and output quality at scale.
Executive takeaway: KV cache offload is how AI factories scale long-context, high-concurrency inference without “buying GPUs for memory,” by converting KV from a RAM constraint into a tiered, schedulable resource that uses both memory and fast storage.
Business outcome: Reduce tail-latency spikes from KV cache eviction/recompute, raise effective concurrency per GPU, and improve unit economics (tokens/sec per dollar, cost per token, tokens/sec per watt) while keeping latency predictable under bursty, multi-tenant demand.
Background
An AI Factory is a purpose-built stack that turns data, power, and GPUs into AI outcomes at industrial scale. For the end user, those outcomes surface as agentic conversations with fast responses, coherent long-form answers, and systems that do not degrade under load. In production, the “output” is often tokens, and the governing economics are inference throughput (tokens/sec), latency (especially time-to-first-token), and efficiency (tokens/sec per watt and tokens/$).
That is why inference sits at the heart of every AI Factory. Training may be episodic, but inference is the production line running every day. The winning AI Factory is the one that converts power, GPUs, and data into the most tokens at the lowest cost, with predictable tail latency under adversarial traffic loads.
Large Language Model (LLM) inference demands ever longer contexts and higher throughput, especially with agents and research or reasoning models. Satisfying these demands requires extending the KV cache beyond GPU memory limits, making it effectively “infinite” in practice.
In practice, this “infinite” KV cache is achieved by tiering state across the platform: GPU memory for the hottest working set, CPU memory/local SSD for warm state, and an external tier that can scale independently as demand grows. The external tier is what prevents node-local ceilings from becoming the next bottleneck as context windows expand and fleet utilization rises.
Our partner, GMI Cloud, sees this pressure daily in production inference clusters serving billions of tokens. The KV cache capacity crisis is an operational constraint that directly shapes cluster design, scheduling, and cost efficiency.
KV cache is the dominant moving state
Modern decoder-only transformers generate tokens one at a time. To avoid reprocessing the entire prior sequence for every new token, inference engines store intermediate attention state in a key-value (KV) cache. The important point is not that KV caching exists. The important point is that:
- KV cache grows with model size, sequence length and concurrency
- KV cache is the largest elastic consumer of GPU memory
- When the KV state crosses GPU memory boundaries, system behavior changes nonlinearly
Once the KV footprint dominates, the system stops being compute-bound and becomes state-bound. You can add more GPUs and still lose to tail-latency spikes caused by cache misses, evictions, or poorly placed workloads.
At enterprise scale, the “dominant moving state” problem becomes an operational problem: the platform needs a place to put KV that is:
- Large enough to absorb growth
- Shared enough to avoid fragmentation and maximize reuse across nodes
- Predictable enough under concurrency that it doesn’t reintroduce latency volatility through the back door
Why “bigger GPUs” don’t eliminate OOM dynamics
State-of-the-art GPU servers are not immune to out-of-memory (OOM) behavior. In production, inference rarely fails as a clean “hard OOM.” Instead, it fails as a sequence of compensations:
- cache eviction to avoid hard OOM,
- recomputation on cache misses,
- TTFT inflation,
- throughput collapse due to increased prefill/decode work,
- and finally SLA violations driven by tail latency.
The outcome is the same: you cap concurrency to preserve latency, leaving GPU potential unused and eroding ROI.KV cache offload changes the failure mode from “evict → recompute” toward “spill → recall.” This does not eliminate cost; it makes the cost explicit and engineerable (bandwidth, queueing, placement), which is exactly what enterprise operators need to enforce SLAs and capacity plans.
KV cache offload only works in production if the stack is designed for it
KV cache offload is often described as “move KV state somewhere else.” In production, that is an incomplete description. Offload is effective only when it is co-designed with scheduling, networking, and storage semantics.
1) Scheduling: locality is a first-class signal
Inference schedulers must account for KV cache locality when placing workloads. If you ignore locality, you recreate the same cost elsewhere:
- you increase cache movement,
- you increase recomputation,
- you increase tail latency,
- and you lose throughput under burst.
In other words, offload alone does not eliminate the KV problem. It only shifts the cost from layer to layer.
Enterprise implication: Locality becomes a placement constraint and a cost model input. The scheduler needs enough degrees of freedom to place work near state when possible, and a sufficiently capable offload tier when it is not. Externalizing KV cache into a shared tier is what makes rescheduling, failover, and burst absorption feasible without turning every move into a full prefill recompute.
2) Networking: transfers must be sustained, not best-effort
KV movement is not like sporadic object reads. Under real traffic, you need sustained, high-bandwidth transfer behavior that keeps GPUs compute-bound instead of I/O-bound. If transfers are treated as best-effort, tail latency becomes unpredictable.
What matters operationally is not peak bandwidth; it is sustained bandwidth under concurrency, plus predictable queueing behavior. The network must be sized and validated as part of the inference data plane, not treated as an incidental dependency.
3) Storage: the cache tier must behave like memory
For KV cache offload to be viable at scale, the offload tier must behave like an extension of the memory hierarchy:
- predictable access characteristics
- semantics compatible with real-time inference
- and failure behavior that doesn’t turn transient hiccups into global stalls
If the offload tier behaves like a cold archive, you can claim “infinite KV” but still lose on latency and throughput.
What local SSD proved, and what it could not
In earlier production deployments, we validated a critical insight: meaningful KV reuse exists in real conversational workloads, and extending KV beyond GPU memory reduces recomputation and stabilizes latency.
But those deployments also revealed the next ceiling. SSD-backed KV cache improves performance, yet remains bounded by node-local capacity. As context lengths grow and concurrency rises, node-local tiers become a new hard constraint. And local SSDs are hard to share across compute nodes, making KV cache reuse less common.
At that point, extending the memory hierarchy beyond the server boundary becomes the next structural requirement.
This is also where inference becomes more fluid. When context can survive beyond a single GPU’s memory boundary, model routing, failover, and experimentation become cheaper and safer.
As is the case for GMI Cloud, our partners must directly support model liquidity: applications optimized for outcomes, not attachment to a single model.
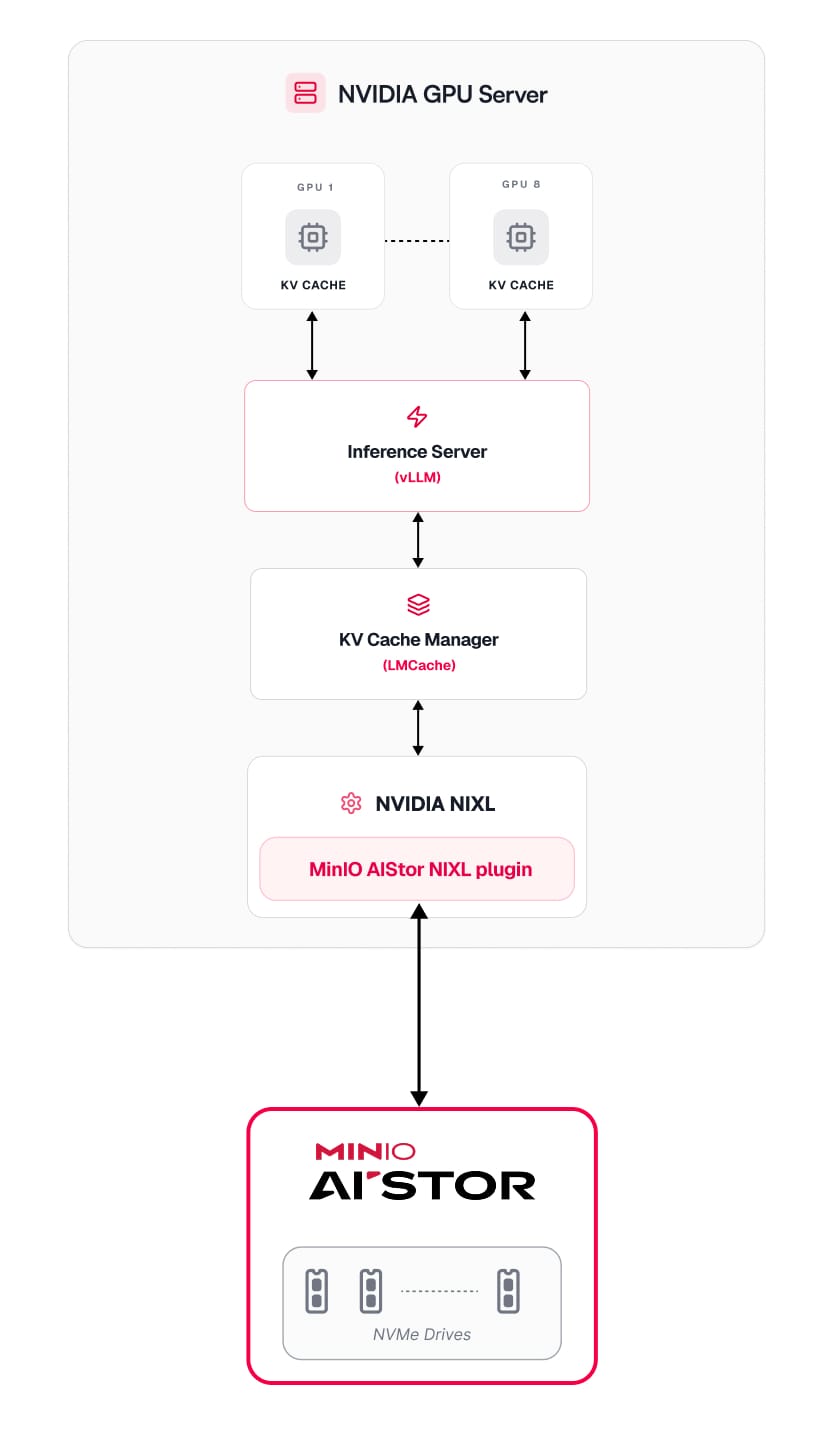
A practical implementation: MinIO AIStor + NVIDIA NIXL inside an inference-first cloud
Once you accept the premise that KV cache offload is a memory-hierarchy problem, the implementation question becomes: how do you move KV state across tiers fast enough that GPUs remain compute-bound?
The approach involves pairing high-performance object storage with a transfer layer designed for inference movement, not generic data access.
- MinIO AIStor serves as a scalable offload tier
- NVIDIA’s Inference Transfer Library (NVIDIA NIXL), which is part of NVIDIA Dynamo inference framework, provides an abstraction for efficient KV transfer
- AIStor’s NIXL S3 plugin enables KV cache movement to MinIO AIStor cluster
The relevant point is not “S3 exists.” The relevant point is that, with the right transfer path and storage behavior, an S3-compatible tier can function as a near-infinite KV cache offload layer.
MinIO AIStor provides a high-performance, S3-compatible object tier that scales out linearly by adding nodes. For KV cache offload, the value is not archival durability, it is the combination of parallel throughput, operational consistency, and elastic capacity so that KV cache can spill beyond node boundaries without turning into an unpredictable bottleneck.
Why this integration is attractive:
This class of design brings in:
- Operational simplicity: integrating directly into the NIXL plugin framework reduces server-side software sprawl and lowers deployment risk.
- Architectural flexibility: using standard S3 allows deployment on existing IP networks today, without requiring exotic fabrics to start realizing benefits.
- Performance potential: a purpose-built transfer path can materially outperform generic object access patterns and reduce GPU idle time caused by KV movement.
Early internal testing shows significant throughput gains over the generic S3 plugin. We’ll soon be sharing full benchmarking results using NVIDIA’s AIPerf tool, measuring:
- TTFT (Time to First Token)
- ITL (Inter-Token Latency)
- End-to-End Request Latency
- TPS (Output Tokens Throughput)
- RPS (Requests Throughput)
Goal: To show that the system stays compute-bound when KV state no longer fits in GPU memory. Full results coming soon, stay tuned.
Closing
GMI Cloud continues to evolve its inference stack to remove bottlenecks before they surface to end users. Treating memory hierarchy as a first-class system problem will solve many problems down the line.
KV cache offload is a prerequisite for running inference economically without sacrificing predictability. When you treat KV state as a first-class tier in the memory hierarchy, you can absorb longer contexts and higher concurrency without forcing application-layer tradeoffs.
MinIO AIStor is the production-grade external tier that operationalizes KV cache offload at scale. Its S3-compatible, scale-out architecture is engineered for sustained parallel throughput and predictable behavior under concurrency, so the KV cache tier behaves like a state layer rather than a cold archive. With multi-tenancy, encryption, and policy controls, AIStor helps teams run shared KV infrastructure with clear guardrails. Together with NVIDIA NIXL, AIStor completes the memory hierarchy: GPU memory for hot state, local tiers for warm state, and AIStor as the elastic external tier for overflow, so the platform stays compute-bound longer, absorbs bursts more gracefully, and improves GPU ROI.






