The Definitive Guide to Lakehouse Architecture with Iceberg and AIStor

Apache Iceberg seems to have taken the data world by a (snow) storm. Initially incubated at Netflix by Ryan Blue (also of Tabular, now Databricks fame), it was eventually transmitted to the Apache Software Foundation where it currently resides. At its core, it is an open table format for at-scale data sets (think hundreds of TBs to hundreds of PBs). With AI gobbling up vast amounts of data for model creation, tuning, and real-time inference, the need for this technology has only increased since its initial development.
Iceberg is a multi-engine compatible format. That means that Spark, Trino, Flink, Presto, Snowflake and Dremio can all operate independently and simultaneously on the same data set. Iceberg supports SQL, the universal language of data analysis, and provides advanced features like atomic transactions, schema evolution, partition evolution, time travel, rollback, and zero-copy branching. This post examines how Iceberg’s features and design, when paired with AIStor’s high-performance storage layer, offers the flexibility and reliability needed to build data lakehouses.
Related: Data Lakehouse Solutions by MinIO
Goals for a Modern Open Table Format
The promise of a lakehouse lies in its ability to unify the best of data lakes and warehouses. Data lakes stored on object storage were designed to store massive amounts of raw data in its native format, offering scalability, ease of use, and cost-effectiveness. However, data lakes on their own struggled with issues like data governance, and the ability to efficiently query the data stored in them. Warehouses, on the other hand, were optimized for structured data and SQL analytics but fell short in handling semi-structured or unstructured data at scale.
Iceberg and other open table formats like Apache Hudi and Delta Lake represent a leap forward. These formats make data lakes behave like warehouses all while retaining the initial flexibility and scalability of object storage. This new stack of open table formats and open storage can support diverse workloads such as AI, machine learning, advanced analytics, and real-time visualization. Iceberg distinguishes itself with its SQL-first approach and focus on multi-engine compatibility.
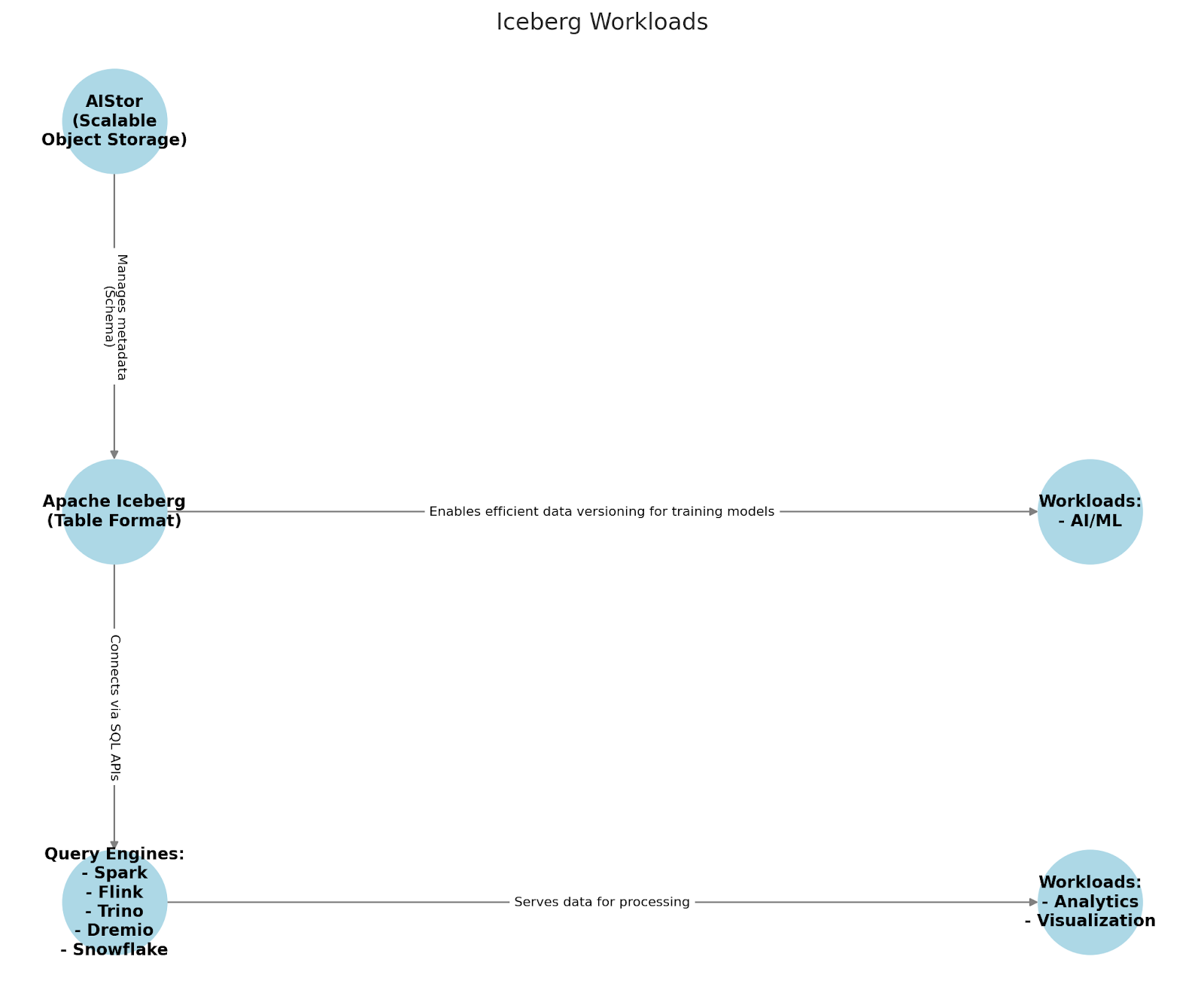
Here is a look at how this infrastructure could function. The query engines can sit directly on top of the object storage in your stack and query the data inside it without migration. The old paradigm of migrating data into a d databases’ storage is no longer relevant. Instead, you can and should be able to query your Iceberg Tables from anywhere.
Analytics tools and Visualizations can often connect directly to your storage where your Iceberg tables are stored, but more typically interface with your query engine for a more streamlined user experience.
Finally, AI/ML has the same design principle as the query engines. These AI/ML tools will use Iceberg tables directly in object storage without migration. While not all AI/ML tools utilize Iceberg at this time, there is a deepening interest in using Iceberg for AI/ML workloads, particularly for their capability of maintaining multiple versions of models and datasets without difficulty.
What’s Special About Iceberg
Apache Iceberg distinguishes itself from the through a combination of features and design principles that set it apart from alternatives like Apache Hudi and Delta Lake.
Schema Evolution: Iceberg offers comprehensive support for schema evolution, allowing users to add, drop, update, or rename columns without necessitating a complete rewrite of existing data. This flexibility ensures that changes to the data model can be implemented seamlessly, maintaining operational continuity.
Partition Evolution: Iceberg supports partition evolution, enabling modifications to partitioning schemes over time without requiring data rewrites. This capability allows for dynamic optimization of data layout as access patterns change.
Metadata Management: Iceberg employs a hierarchical metadata structure, including manifest files, manifest lists, and metadata files. This design enhances query planning and optimization by providing detailed information about data files, facilitating efficient data access and management.
Multi-Engine Compatibility: Designed with openness in mind, Iceberg is compatible with various processing engines such as Apache Spark, Flink, Trino, and Presto. This interoperability provides organizations with the flexibility to choose the tools that best fit their needs and effectively commodizes query engines driving down pricing and driving up innovation in these products.
Open Source Community: As with all of the open table formats, Iceberg benefits from a diverse and active community, contributing to its robustness and continuous improvement. ‘
Object Storage and Iceberg
Object storage forms the foundation of modern lakehouse architectures, providing the scalability, durability, and cost-efficiency required to manage vast datasets across many environments. In a lakehouse architecture, the storage layer plays a critical role in ensuring the durability and availability of data, while an open table format like Iceberg manages the metadata.
AIStor is particularly well-suited for these requirements. For example, for high-throughput workloads like model training, AIStor’s support for S3 over RDMA ensures low-latency access to data. This feature makes the combination of the two technologies a very effective solution, particularly for large-scale AI and analytics pipelines. High performance is critical for the success of lakehouse initiatives - It doesn’t matter how cool your table format is if it can’t serve up queries as fast as your users require.
Try it out Yourself: Prerequisites
You’ll need to install Docker and Docker Compose. When both are required, it’s often easier to install Docker Desktop. Download and install Docker Desktop from the official Docker website. Follow the installation instructions provided in the installer for your operating system. Open Docker Desktop to ensure it’s running.
If you would prefer, you can also verify the installation of Docker and Docker Compose by opening a terminal and running:
docker --version
docker-compose --versionIceberg Tutorial
This section demonstrates how to integrate Iceberg and AIStor for a robust lakehouse architecture. We'll use the Apache Iceberg Spark Quickstart to set up our initial environment:
Step 1: Setup with Docker Compose
Follow the Apache Iceberg Spark Quickstart guide to launch a containerized environment with Spark and Iceberg pre-configured. The first step in the guide is to copy the below information into a file and save as a file named docker-compose.yml:
version: "3"
services:
spark-iceberg:
image: tabulario/spark-iceberg
container_name: spark-iceberg
build: spark/
networks:
iceberg_net:
depends_on:
- rest
- minio
volumes:
- ./warehouse:/home/iceberg/warehouse
- ./notebooks:/home/iceberg/notebooks/notebooks
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
ports:
- 8888:8888
- 8080:8080
- 10000:10000
- 10001:10001
rest:
image: apache/iceberg-rest-fixture
container_name: iceberg-rest
networks:
iceberg_net:
ports:
- 8181:8181
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
- CATALOG_WAREHOUSE=s3://warehouse/
- CATALOG_IO__IMPL=org.apache.iceberg.aws.s3.S3FileIO
- CATALOG_S3_ENDPOINT=http://minio:9000
minio:
image: minio/minio
container_name: minio
environment:
- MINIO_ROOT_USER=admin
- MINIO_ROOT_PASSWORD=password
- MINIO_DOMAIN=minio
networks:
iceberg_net:
aliases:
- warehouse.minio
ports:
- 9001:9001
- 9000:9000
command: ["server", "/data", "--console-address", ":9001"]
mc:
depends_on:
- minio
image: minio/mc
container_name: mc
networks:
iceberg_net:
environment:
- AWS_ACCESS_KEY_ID=admin
- AWS_SECRET_ACCESS_KEY=password
- AWS_REGION=us-east-1
entrypoint: >
/bin/sh -c "
until (/usr/bin/mc config host add minio http://minio:9000 admin password) do echo '...waiting...' && sleep 1; done;
/usr/bin/mc rm -r --force minio/warehouse;
/usr/bin/mc mb minio/warehouse;
/usr/bin/mc policy set public minio/warehouse;
tail -f /dev/null
"
networks:
iceberg_net:
Next, in a terminal window navigate to the place where you saved the .yml file and start up the docker containers with this command:
docker-compose upYou can then run the following commands to start a Spark-SQL session.
docker exec -it spark-iceberg spark-sql
Step 2: Create a Table
Open a Spark shell and create a table:
CREATE TABLE my_catalog.my_table (
id BIGINT,
data STRING,
category STRING
)
USING iceberg
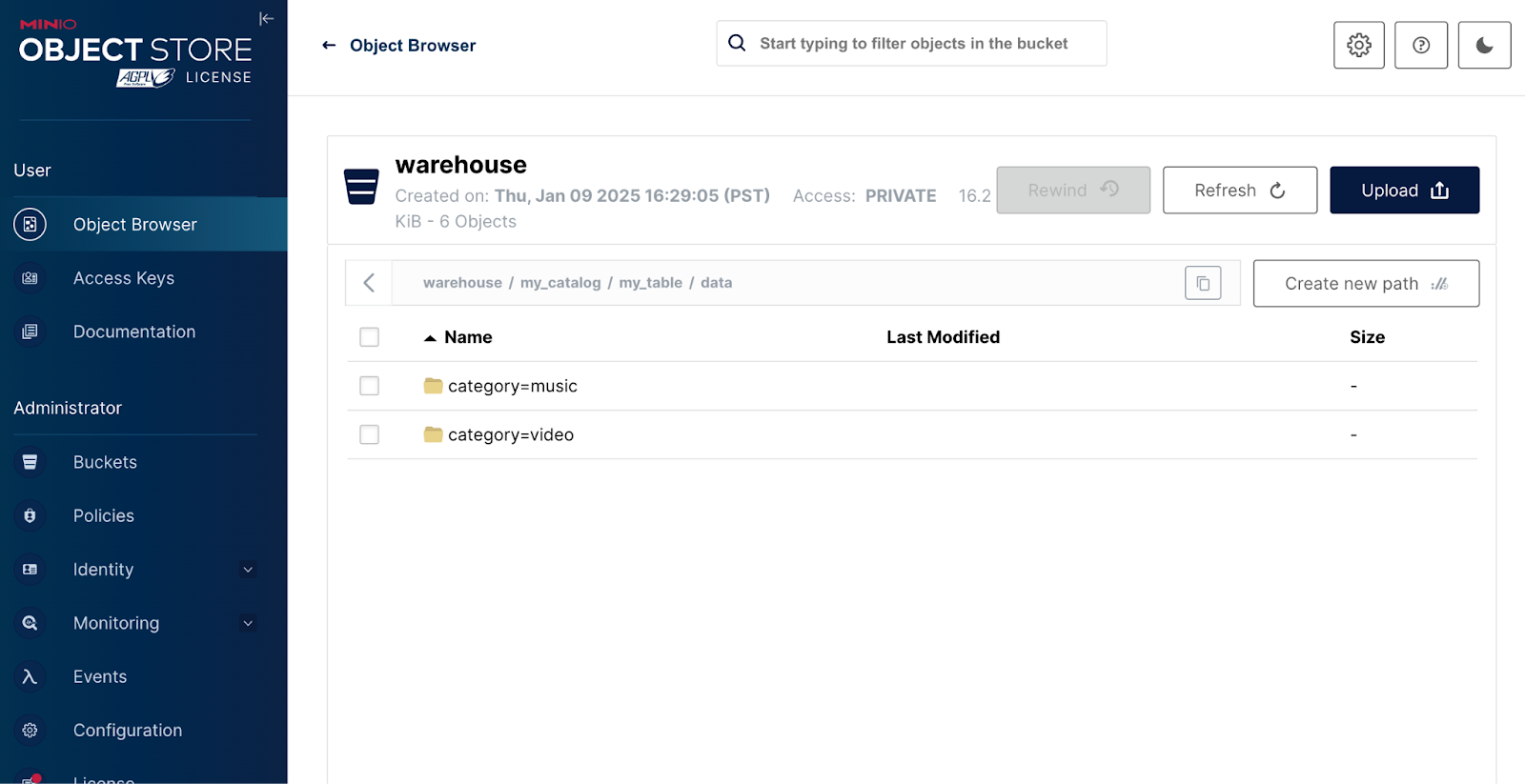
PARTITIONED BY (category);Inspect your MinIO Console by navigating to http://127.0.0.1:9001 and logging in with the credentials from the .yml: AWS_ACCESS_KEY_ID=admin, AWS_SECRET_ACCESS_KEY=password
Here, observe the iceberg/my_table/metadata path created for the table. Initially, no data files exist—only metadata that defines the schema and partitions.
Step 3: Insert Data
Insert some mock data:
INSERT INTO my_catalog.my_table VALUES
(1, 'a', 'music'),
(2, 'b', 'music'),
(3, 'c', 'video');This operation creates data files in the appropriate partitions (my_table/data/category=...) and updates the metadata.
Step 4: Query the Data
Run a basic query to validate:
SELECT COUNT(1) AS count, data
FROM my_catalog.my_table
GROUP BY data;Your output should look something like the following:
spark-sql ()> SELECT COUNT(1) AS count, data
> FROM my_catalog.my_table
> GROUP BY data;
1 c
1 b
1 a
Time taken: 0.575 seconds, Fetched 3 row(s)Testing Key Iceberg Features
Now that you’ve established a baseline data lakehouse with data that you can manipulate. Let’s check out the features that make Iceberg unique: Schema Evolution, and Partition Evolution.
Schema Evolution
Schema evolution is one of Apache Iceberg’s most powerful and defining features, addressing a significant pain point in traditional warehouse systems. It allows you to modify a table's schema without requiring expensive and time-consuming data rewrites, which is particularly beneficial for large-scale datasets. This capability enables organizations to adapt their data models as business needs evolve without disrupting ongoing queries or operations.
In Iceberg, schema changes are handled purely at the metadata level. Each column in a table is assigned a unique ID, ensuring that changes to the schema do not affect the underlying data files. For instance, if a new column is added, Iceberg assigns it a new ID without reinterpreting or rewriting existing data. This avoids errors and ensures backward compatibility with historical data.
Here’s an example of how schema evolution works in practice. Suppose you need to add a new column, buyer, to store additional information about transactions. You can execute the following SQL command:
ALTER TABLE my_catalog.my_table ADD COLUMN buyer STRING;This operation updates the table's metadata, allowing new data files to include the buyer column. Older data files remain untouched, and queries can be written to handle both new and old data seamlessly.
Similarly, if a column is no longer required, you can remove it without affecting the stored data:
ALTER TABLE my_catalog.my_table DROP COLUMN buyer;This action updates the schema to exclude the category column. Iceberg ensures that any associated metadata is cleaned up while maintaining the integrity of historical queries that might still reference older data versions.
Iceberg’s schema evolution also supports renaming columns, changing column types, and rearranging column order, all through efficient metadata-only operations. These changes are made without altering the data files, making schema modifications instantaneous and cost-effective.
This approach is especially advantageous in environments with frequent schema changes, such as those driven by AI/ML experiments, dynamic business logic, or evolving regulatory requirements.
Partition Evolution
Iceberg supports partition evolution that can handle the tedious and error-prone tasks of producing partition values for rows in a table. Users focus on adding filters to the queries that solve business problems and do not worry about how the table is partitioned. Iceberg automatically avoids reads from unnecessary partitions.
Iceberg handles the intricacies of partitioning and changing the partition scheme of a table for you, greatly simplifying the process for end users. You can define partitioning or let Iceberg take care of it for you. Iceberg likes to partition on a timestamp, such as event time. Partitions are tracked by snapshots in manifests. Queries no longer depend on a table’s physical layout. Because of this separation between physical and logical tables, Iceberg tables can evolve partitions over time as more data is added.
ALTER TABLE my_catalog.my_table ADD COLUMN month int AFTER buyer;
ALTER TABLE my_catalog.my_table ADD PARTITION FIELD month;We now have two partitioning schemes for the same table. From now on, query plans are split, using the old partition scheme to query old data, and the new partition scheme to query new data. Iceberg takes care of this for you — people querying the table don’t need to know that data is stored using two partition schemes. Iceberg does this through a combination of behind-the-scenes WHERE clauses and partition filters that prune out data files without matches.
Time Travel and Rollback
Every write to Iceberg tables creates new snapshots. Snapshots are like the versions and can be used to time travel and rollback just like the way we do with AIStor versioning capabilities. The way snapshots are managed is by setting expireSnapshot so the system is maintained well. Time travel enables reproducible queries that use exactly the same table snapshot, or lets users easily examine changes. Version rollback allows users to quickly correct problems by resetting tables to a good state.
As tables are changed, Iceberg tracks each version as a snapshot and then provides the ability to time travel to any snapshot when querying the table. This can be very useful if you want to run historical queries or reproduce the results of previous queries, perhaps for reporting. Time travel can also be helpful when testing new code changes because you can test new code with a query of known results.
To see the snapshots that have been saved for a table run the following query:
SELECT * FROM my_catalog.my_table.snapshots;Your output should look something like this:
2025-01-10 00:35:03.35 4613228935063023150 NULL append s3://warehouse/my_catalog/my_table/metadata/snap-4613228935063023150-1-083e4483-566f-4f5c-ab47-6717577948cb.avro {"added-data-files":"2","added-files-size":"1796","added-records":"3","changed-partition-count":"2","spark.app.id":"local-1736469268719","total-data-files":"2","total-delete-files":"0","total-equality-deletes":"0","total-files-size":"1796","total-position-deletes":"0","total-records":"3"}
Time taken: 0.109 seconds, Fetched 1 row(s)Some examples:
-- time travel to October 26, 1986 at 01:21:00
SELECT * FROM my_catalog.my_table TIMESTAMP AS OF '1986-10-26 01:21:00';-- time travel to snapshot with id 10963874102873
SELECT * FROM prod.db.table VERSION AS OF 10963874102873;You can do incremental reads using snapshots, but you must use Spark, not Spark-SQL. For example
scala> spark.read()
.format(“iceberg”)
.option(“start-snapshot-id”, “10963874102873”)
.option(“end-snapshot-id”, “10963874102994”)
.load(“s3://iceberg/my_table”)You can also roll back the table to a point in time or to a specific snapshot, as in these two examples
CALL my_catalog.system.rollback_to_timestamp(‘my_table’, TIMESTAMP ‘2022-07-25 12:15:00.000’); CALL my_catalog.system.rollback_to_snapshot(‘my_table’, 527713811620162549);Expressive SQL
Iceberg supports all the expressive SQL commands like row level delete, merge, and update, and the biggest thing to highlight is that Iceberg supports both Eager and lazy strategies. We can encode all the things we need to delete (for example, GDPR or CCPA,) but not rewrite all those data files immediately, we can lazily collect garbage as needed and that helps in efficiency on the huge tables supported by Iceberg.
For example, you can delete all records in a table that match a specific predicate. The following will remove all rows from the video category.
DELETE FROM my_catalog.my_table WHERE category = 'video';Alternatively, you could use CREATE TABLE AS SELECT or REPLACE TABLE AS SELECT to accomplish this:
CREATE TABLE my_catalog.my_table_music AS SELECT * FROM my_catalog.my_table WHERE category = 'music';You can merge two tables very easily:
MERGE INTO my_catalog.my_data pt USING (SELECT * FROM my_catalog.my_data_new) st ON pt.id = st.id WHEN NOT MATCHED THEN INSERT *;Data Engineering
Iceberg is the foundation for the open analytic table standard and uses SQL behavior and applies the data warehouse fundamentals to fix the problems before we know we have it. With declarative data engineering we can configure tables and not worry about changing each engine to fit the needs of the data. This unlocks automatic optimization and recommendations. With safe commits, data services are possible which helps in avoiding humans babysitting data workloads. Here are some examples of these types of configurations:
To inspect a table’s history, snapshot,s and other metadata, Iceberg supports querying metadata. Metadata tables are identified by adding the metadata table name (for example, history) after the original table name in your query.
To display a table’s data files:
SELECT * FROM my_catalog.my_table.files;To display manifests:
SELECT * FROM my_catalog.my_table.manifests;To display table history
SELECT * FROM my_catalog.my_table.history;To display snapshots
SELECT * FROM my_catalog.my_table.snapshots;You can also join snapshots and table history to see the application that wrote each snapshot
select
h.made_current_at,
s.operation,
h.snapshot_id,
h.is_current_ancestor,
s.summary['spark.app.id']
from my_catalog.my_table.history h
join my_catalog.my_table.snapshots s
on h.snapshot_id = s.snapshot_id
order by made_current_at;Now that you’ve learned the basics, load some of your data into Iceberg, then learn more from the Iceberg Documentation.
Integrations
Various query and execution engines have implemented Iceberg connectors, making it easy to create and manage Iceberg tables. The engines support Iceberg include Spark, Flink, Presto ,Trino, Dremio, Snowflake and the list is growing.
This extensive integration landscape ensures that organizations can adopt Apache Iceberg without being constrained to a single processing engine, promoting flexibility and interoperability in their data infrastructure.
Catalogs
It would be remiss in any definitive guide not to mention catalogs. Iceberg catalogs are central to managing table metadata and facilitating connections between datasets and query engines. These catalogs maintain critical information such as table schemas, snapshots, and partition layouts, enabling Iceberg’s advanced features like time travel, schema evolution, and atomic updates. Several catalog implementations are available to meet diverse operational needs. For instance, Polaris offers a scalable, cloud-native cataloging solution tailored to modern data infrastructures, while Dremio Nessie introduces versioning with Git-like semantics, enabling teams to track changes to data and metadata with precision. Traditional solutions like Hive Metastore are still widely used, particularly for backward compatibility with legacy systems.
It’s Cool to Build Data Lakes with Iceberg and AIStor
Apache Iceberg gets a lot of attention as a table format for data lakes. The growing open-source community and increasing number of integrations from multiple cloud providers and application frameworks means that it’s time to take Iceberg seriously, and start experimenting, learning, and planning on integrating it into existing data lake architecture. Pair Iceberg with AIStor for multi-cloud data lakehouses and analytics.
As you get started with Iceberg and AIStor, please reach out and share your experiences or ask questions through our Slack channel.






