The New Math on Backup and Replication

The world of backup has entered a brave new world where traditional solutions still have utility but where the scale, speed of change and application landscape require different…radically different…approaches. This post seeks to lay out the challenges of this new world, where the line of demarcation exists and how to think about architecting a data protection framework that can achieve cloud-native scale.
We are not going to provide an exact number where one needs to rethink a traditional backup approach in favor of a cloud-scale replication solution, but it exists for the sole reason that you simply can’t backup or restore data past a certain size. Nonetheless, the goal is to provide a reasonable framework to our customers based on what we see them, and our community, doing. It will cover backup and restore to an object store as well as ditching backup for replication.
First off, the absolute number one consideration is bandwidth. Your dedicated backup network will determine when you need to move from traditional backup approaches to at-scale approaches.
All object stores are throughput oriented. Some are more performant than others. That means they want the fastest network we can get. We almost always max the network in our benchmarks. If your object store isn’t talking about the network's speed, hint-hint, it is because they aren’t very fast. Think 100 GbE for MinIO - even in backup/restore architectures (because getting the business back up and running is the #1 goal right?).
Second, there is some great backup software out there. We are partnered with all of them and we have blogs on Veeam, Commvault and Velero to name a few. This software does far more than simply ensure the data gets backed up from point A to point B - there is deduplication, indexing, cataloging, compression and secure restore and more. This software is built to optimize for bandwidth with incremental replication, changed block tracking etc.
The modern challenges of application type, scale and the speed of mutation create real problems past a certain point. Look at the table below:

The takeaway is that past 1PB, you are looking at 24 hours or more to backup/restore. This again, assumes 100GbE dedicated bandwidth for the task. Even accounting for the cool tricks the backup vendors can apply with dedupe, compression, changed block tracking - you probably can’t get past 2PB.
For the vast majority of companies - that is just fine. It is why the backup vendors have so many customers. They don’t have 2PB of data or it is carefully sliced into different backups.
Best practice #1 - If your data is small or small-ish (<1PB) you can use traditional backup software to backup and restore to MinIO (every vendor now views object storage as the optimal backup location). MinIO’s built in tools (mc mirror or replication) are also valid but will not get you some of the core features outlined above. Be sure you have enough bandwidth to recover in the face of an issue.
Related: Data Storage Optimization Myths: Duduplication vs Compression
Beyond the Red Line
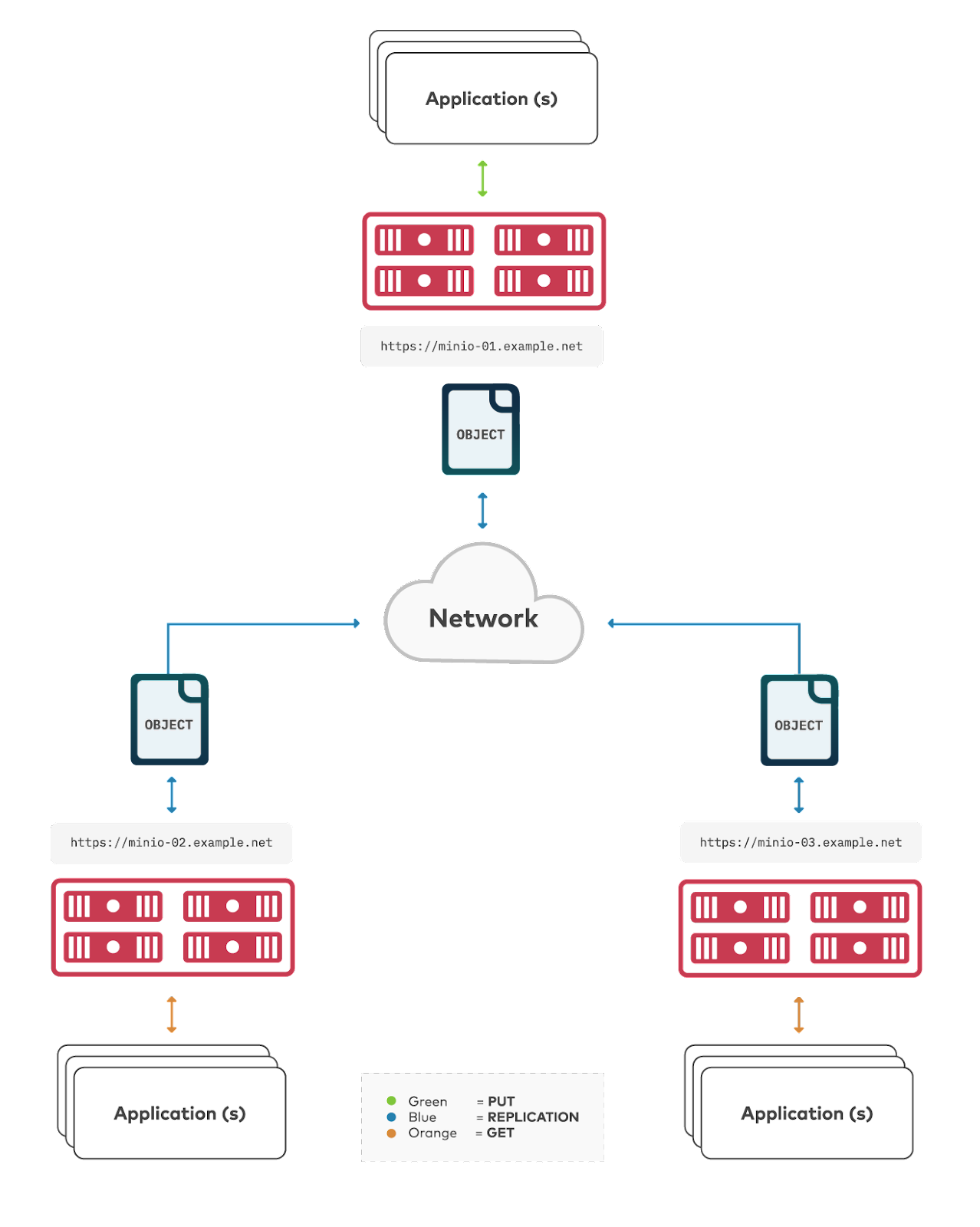
But what about enterprises with multiple PBs of data? This, as you would surmise, requires a different approach. That requires active-active multisite replication. With this approach the enterprises can achieve the backup mantra of 3-2-1 in a way that is both manageable and sustainable.
With an active-active multisite replication approach you would establish three sites (if you choose to follow 3-2-1). The first site is the primary. The second site is geographically remote and the third site is as well. These sites can be on-prem, in a colo, in a public cloud. With MinIO you don’t have to worry about the architectural distinction - MinIO will run anywhere you want it to. You worry about the bandwidth and the configuration.
The multiple sites solve the offsite backup requirement.

In architecting these systems - there will be the initial spin up, then the ongoing management. The initial spin up will be a function of the amount of data and the amount of bandwidth. This may take a week or more depending on the amount of data. From there, it will run constantly and seamlessly.
In this architecture, should the primary go down, the load balancer will point to the secondary source. The secondary source will continue to backup to the tertiary source. No data is lost.
There are features/capabilities to be aware of here:
Active-Active replication is designed for organizations looking for multi-primary topologies, fast hot-hot failover, and multi-geo resiliency. Think of multi-site replication like a mesh network - each bucket synchronized across multiple mesh nodes. This further improves the flexibility of MinIO replication for organizations with more complex requirements around multi-DC or multi-region synchronization.
Multi-site replication starts with configuring which buckets need to be replicated.
Multi-site replication supports replication of delete operations, delete markers, existing objects, and replica metadata changes.
MinIO can replicate:
- Objects and their metadata (which is written atomically with the object in MinIO). Those objects can either be encrypted or unencrypted. This is subject to the constraints outlined above regarding older objects. The owner will need the appropriate permissions.
- Object versions.
- Object tags, if there are any.
- S3 Object Lock retention information, if there is any. It should be noted that the retention information of the source will override anything on the replication side. If no retention information is in place, the object will take on the retention period on the destination bucket. For more information on object locking, look at this blog post or the documentation.
Some slick features:
- The ability for source and destination buckets to have the same name. This is particularly important for the applications to transparently failover to the remote site without any disruption. The load balancer or the DNS simply directs the application traffic to the new site. If the remote bucket is in a different name, it is not possible to establish transparent failover capability. This is a crucial availability requirement for enterprise applications like Splunk or Veeam.
- MinIO also supports automatic object locking/retention replication across the source and destination buckets natively out of the box. This is in stark contrast to other implementations which make it very difficult to manage.
- MinIO does not require configurations/permission for AccessControlTranslation, Metrics and SourceSelectionCriteria - significantly simplifying the operation and reducing the opportunity for error.
- MinIO uses near-synchronous replication to update objects immediately after any mutation on the bucket. Other vendors may take up to 15 minutes to update the remote bucket. MinIO follows strict consistency within the data center and eventual-consistency across the data centers to protect the data. Replication performance is dependent on the bandwidth of the WAN connection and the rate of mutation. As long as there is sufficient bandwidth, the changes are propagated immediately after the commit. Versioning capability enables MinIO to behave like an immutable data store to easily merge changes across the active-active configuration. The ability to push changes without delay is critical to protecting enterprise data in the event of total data center failure.
- MinIO has also extended the notification functionality to push replication failure events. Applications can subscribe to these events and alert the operations team. Documentation on this can be found here.
Architectural Considerations
Multi-Site replication shares the basic considerations for Two-Way Active-Active replication, with a few additional considerations around latency:
Hardware: MinIO recommends the same hardware on all deployments participating in the multi-site replication configuration. Each added MinIO deployment with heterogeneous hardware profiles increases complexity and slows identification of potential issues. This is a best practice - not a hard rule, and we acknowledge it can be difficult to ensure - particularly if one of the endpoints is a cloud storage service.
Network: Each MinIO deployment participating in multi-site bucket replication adds to the bandwidth and throughput requirements of all other deployments in the replication configuration. Ensure the entire network - the NICs, cross-site WAN, switches, and cables themselves - provide more throughput and bandwidth than required for the amount of data replicated between sites.
Latency: Multi-site replication has increased latency sensitivity, as MinIO does not consider an object as replicated until it has synchronized to all configured remote targets. Replication latency is therefore dictated by the slowest link in the replication mesh.
Scale: The main limitation to scale for multi-site replication is the management overhead of each MinIO deployment participating in the configuration. Each MinIO deployment is an independent object storage service - replication only synchronizes objects between configured buckets. Administrators remain responsible for synchronizing server-level configurations, such as Identity and Access Management or network ingress.
Best practice #2 - Beyond a PB, we recommend active-active, multi-site replication. We also recommend getting a commercial license to have MinIO by your side in the architecture and deployment of the system. Active-active is more expensive than backup but less expensive than data loss.
Enable Time Machine-Like Behaviors with Continuous Data Protection
Continuous Data Protection (CDP) enables the enterprise to restore from any point you choose. CDP is extremely challenging at scale for file and block approaches.
With MinIO, a user can go to where an object was at any point of time; since every change is automatically versioned, the concept of “recovering” a snapshot is irrelevant because it already exists.
Continuous data protection, utilizes MinIO’s versioning capabilities. Versioning is enabled at the bucket level and creates a unique version ID for each version of an object. When a new version of the object is written, both the old and new versions of the object exist, each with its own unique identifier. Old versions of individual objects can be exposed quickly and easily as required simply by removing their delete flags.
When versioning is enabled, MinIO tracks every single operation and never overwrites any object. You can use the MinIO Console, MinIO Client (mc) or SDK to apply versioning and work with different versions of objects.
Only admins and users with appropriate permissions can change versioning configuration. Once enabled for a bucket, versioning cannot be disabled, it can only be suspended.
Versioning has a tradeoff - while it protects data from unintended actions, it results in larger bucket sizes as buckets hold multiple versions of objects. This can be mitigated using Life Cycle Management to remove versions of objects that are no longer required. MinIO life cycle management tools is a policy-based approach that determines how long data stays on disk before being removed - but that’s for another blog post.
Best practice #3 - Backup is one variable of a larger data protection and data management equation. Combine backup with data lifecycle management to control for costs and complexity.
Data Lifecycle Management Options
If the architect is intent on adhering to the 3-2-1 plan - they should use different media types. MinIO supports NVMe, SSD, HDD so this shouldn’t be a problem. Combine the multi-site, active-active replication with data lifecycle management and tier from expensive fast drives to inexpensive slow drives or to cheap storage on public clouds via the ILM capabilites. This is easily configured.
All Together Now
So let’s summarize:
Always be thinking about your bandwidth. Overprovision. This is independent of your architectural choices.
Small data (less than 1PB). Use your backup vendor of choice and backup to object storage (MinIO). One constant - your data will grow. Make sure you are putting it on something that can scale.
Medium to Large Data (1-2PB+). Traditional backup of large data volumes to MinIO will not work (and stopped working for SAN/NAS devices hundreds of TBs ago). Move to replication. Depending on the organization’s needs that can be two site or multi-site. Don’t forget your bandwidth.






