Transparent Data Compression on MinIO
In this blog post we will discuss the transparent data compression options in MinIO. We will look at the benefits of enabling compression, and how to fine-tune settings in MinIO.
Introduction
Most data is stored in easy to read file formats for easy application interoperability. While there are widely used formats for image, video, and sound compression, most other data is stored as text, as JSON, CSV, or other similar text-based formats.
Formats like Parquet, Avro, and ORC have optional compression, so typically these formats are already compressed when stored. Video and images are also typically compressed with domain-specific algorithms that offer better compression than generic formats.
However, for custom data, it is preferable to keep data in an uncomplicated format which doesn’t include a decompression step to access. We want to offer an option to have this data compressed before it is stored on disks.
Transparent Compression at IO Speed
Compression for MinIO has been developed to enable transparent compression without affecting the overall performance of the system.
MinIO uses a compression method based on Snappy called S2. It is compatible with Snappy content, but has two format extensions. First of all, it allows bigger blocks than the 64KB blocks allowed for Snappy streams. This greatly improves compression. Secondly it adds “repeat offsets,” which offers compression improvements mainly to machine generated data, like log files, JSON, and CSV. It also allows for matches longer than 64 bytes bytes to be effectively encoded, which is a pain point for Snappy.
S2 also allows for concurrent compression of multiple blocks when input is faster than what a single core can absorb. This is important to keep the responsiveness of individual requests up. Effectively the limitation with 16+ cores will be memory speed.
Compression Ratios
Some appliance vendors will promise, or even assume, a given compression ratio when calculating cost per TB. With compression there is no guaranteed ratio above 1:1. Different data types yield different compression ratios, and in our opinion there is no meaningful way to provide any average compression ratio. Compression ratios should never be evaluated in a vacuum — they should always be paired with the compression speed, since practical compression is a tradeoff of these two factors.
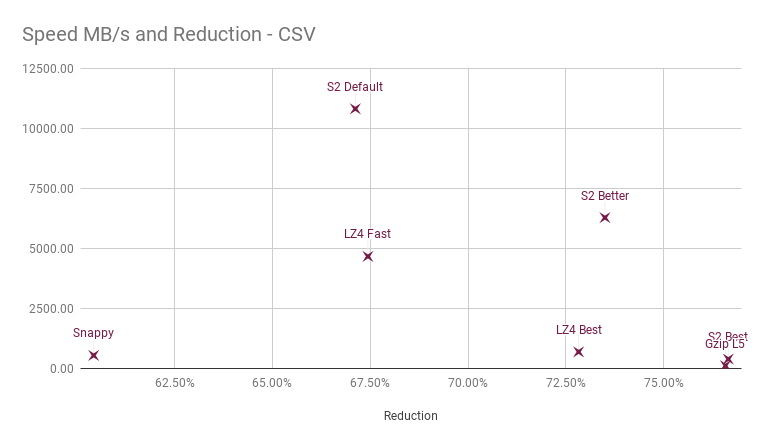
Let’s compare a single data type to observe the differences. We compare Go implementations of these algorithms on an AMD64 platform, using up to 16 cores.
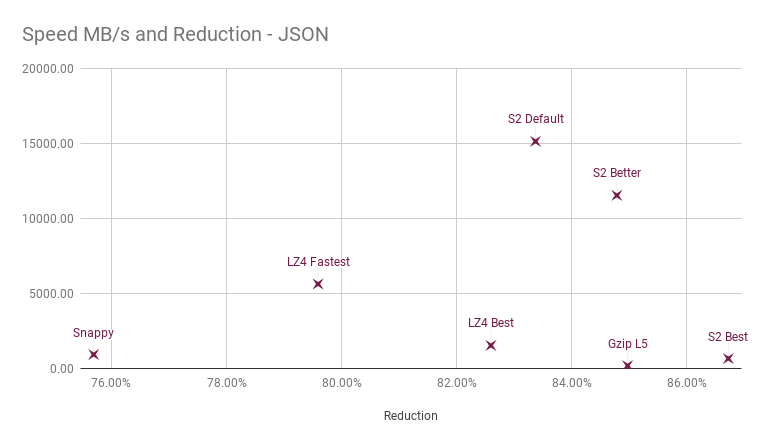
First of all, the horizontal axis is a truncated compression ratio, reduction achieved from the uncompressed size. Right is better. To give a reference, the single-threaded gzip level 5 has been included.
Decompression speed is using a single core, even though S2 offers concurrent decompression.
For this data, Snappy falls about 10% short of the Gzip reference. Since we are dealing with reduction percentages, this also means that Snappy takes up about 1.6x the space of Gzip compressed data. This ignores the fact that Snappy decompresses about 4x faster than Gzip.
LZ4 is typically seen as superior to Snappy. An implementation of LZ4 that allows for compression on multiple cores also makes this point clearer. But base compression is better. The LZ4 Best, also sometimes referred to as LZ4-HC, offers compression close to gzip, but even though decompression is fast, the compression is not at interactive speeds.
S2 offers three compression levels; S2 Default is the fastest possible, and can be seen as a direct competitor to Snappy with regards to single core usage. With this data type it performs better than any LZ4 level with a significantly higher throughput. This mode is used by MinIO for platforms where an assembly implementation isn’t available.
S2 Better allows trading of a bit of CPU for higher compression. Here compression rivals Gzip, but decompression speed is a great deal better. This mode is used by MinIO on platforms where assembly is available — currently AMD64.
S2 Best is the best compression S2 can do with the current format. This can be used in situations where compression speed/resources aren’t the most important, but fast decompression is still needed. Currently MinIO does not use this mode, but may implement it as a lifecycle option for objects that haven’t changed in a while.
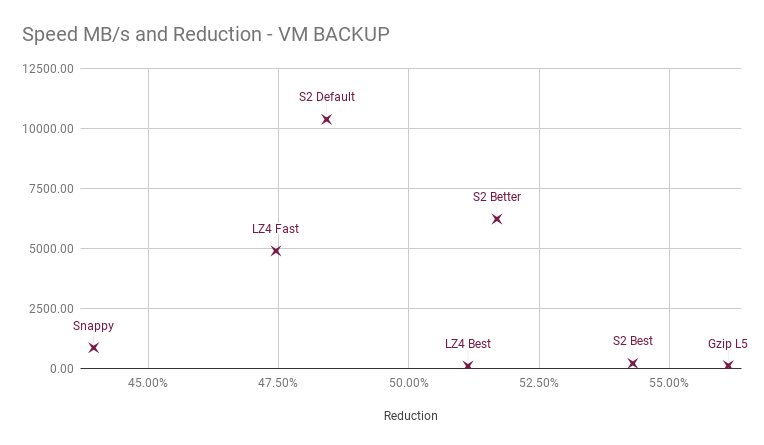
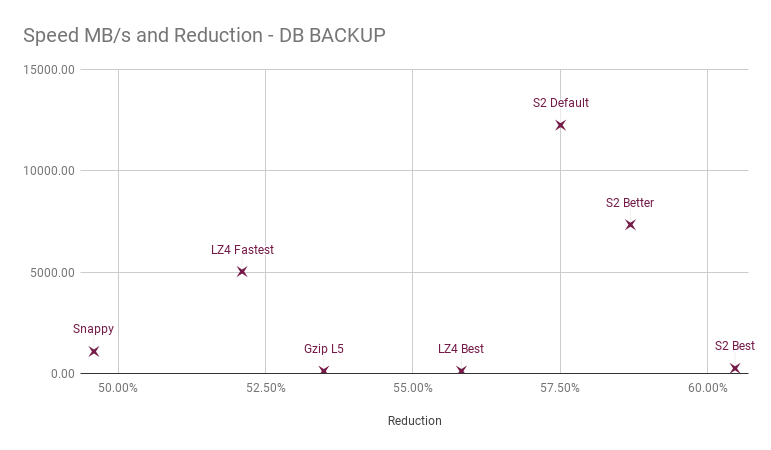
To compare, here are a few comparisons of other data types:
Incompressible Objects
An important feature of modern compression is that it behaves well with pre-compressed data. Traditionally pre-compressed data has been a problem for compression algorithms. Often compressors would slow down unreasonably when confronted with incompressible data.
Many people therefore instinctively know that it is bad to recompress already compressed data. However, many modern implementations are now able to a reasonable degree to skip incompressible sections quickly.
For the compressors above, these are the speeds on 2GiB (2,147,483,647 bytes) incompressible data:
Here we also included gzip from the Go standard library as a representative of this “bad” behavior. An alternative gzip implementation doesn’t show this problem. In all other cases the content is processed quite fast and they get a pass.
This means that MinIO can be expected to handle pre-compressed data well.
Seeking Compressed Files
A typical downside of compression is that the ability to skip within a file is lost. The solution for this is to compress blocks independently and keep an index that maps a number of uncompressed offsets to compressed offsets where the decompression can start.
Compressing independent blocks will reduce compression slightly, but less with bigger blocks. Snappy/S2compresses streams as independent blocks by design.
For MinIO this is relevant since S3 GetObject requests can include optional ranges to retrieve. This allows retrieving parts of objects, and we want that to be as efficient as possible.
Starting from RELEASE.2022-07-13T23-29-44Z we now generate an index for every file part uploaded that is bigger than 8MB. The index is then attached internally to the metadata. This allows us to effectively skip forward and only decode the part of the object needed to return the requested data.
The index is typically 16 bytes + approximately 3 bytes per MB of data. This allows MinIO to serve any byte from within a compressed file at the same speed as retrieving the first byte.
Compression + Encryption at Rest
By default an extra parameter is required for MinIO to compress data to be encrypted on disk. This is to ensure that you are aware of the implications of this.
When compressing data you get two numbers; the uncompressed and the compressed size. Without compression anyone obtaining your data can only see one of these — the uncompressed size.
While this still does not give you access to any data within the compressed file, it does give some hints at the data. It can tell you some types of data that it cannot possibly be. If you see a file that is compressed by 50% it is extremely unlikely that it will contain MP4 compressed video.
Similarly, a file compressed to only a few bytes will likely contain a very simple repeated sequence. It is not possible to tell what the sequence is, but it reduces the possibilities. MinIO from RELEASE.2022-07-13T23-29-44Z will pad compressed output to a multiple of 256 bytes. This padding is not recorded anywhere. We do not consider this a full fix for the issue, but it greatly reduces the usefulness of the leaked size information to adversaries.
This is the main reason MinIO does not return any information about the compressed sizes to clients. Therefore any information about this would require access to backend storage or backend network communication.
With this information you are now equipped with enough knowledge to determine if you deem it safe to enable compression and encryption.
CRIME-style attacks are not possible on MinIO, since we do not allow modifying or appending to any compressed stream. We also do not deduplicate/compress across object versions since this would leak too much information about files.
Configuring Compression in MinIO
By default, on-disk compression is disabled in MinIO. On-disk compression can be enabled or disabled at any time. To enable on-disk compression use mc admin config set myminio compression enable=on.
This will enable compression for a preset number of extensions and MIME types. By default these will include:
You can inspect current settings with mc admin config get myminio compression.
You can modify this list at any time by modifying:
mc admin config set myminio compression \
extensions=.txt,.log,.csv,.json,.tar,.xml,.bin \
mime_types=text/*,application/json,application/xml,binary/octet-streamBy default MinIO forcefully excludes extensions of commonly incompressible data, such as gzip, audio, video, image files.
It is possible to enable compression for all objects, except the excluded ones by setting the extension list and mime types to empty:
mc admin config set myminio compression enable=on extensions= mime_types=
The final setting is allow_encryption=on, which allows compression even for objects that will be encrypted. Only set this when you have read the section above and understand the implications.
Conclusion
MinIO offers the best-in-class compression scheme that allows for fully transparent compression of data on disk. This can in many scenarios lead to a reduction in storage costs, simply by enabling compression.
GET and PUT performance should in all cases remain close to the same when compression is enabled. In fact, in situations where performance is limited by disk read speed, compression may offer additional performance since less data has to be read.
We will keep adding new features. We are currently evaluating bucket/prefix level configuration options as well as compression-via-lifecycle which will compress files as they reach a certain age.
If you are interested in these features, download MinIO and try it out for yourself. If you have any questions or want to tell us about the great apps you’re building using MinIO, ping us on hello@min.io, join the Slack community, follow our blog, or subscribe to our newsletter.






