Gracefully handling disk failures in MinIO

MinIO is renowned for its industry-leading performance, data durability and straightforward simplicity. This blog post focuses on the fault-tolerance and troubleshooting mechanisms that make MinIO a reliable home for data lakehouses and data-intensive application workloads.
MinIO uses built-in Erasure Coding to provide data redundancy, fault tolerance and availability. MinIO deployments have built-in fault tolerance for multiple drive failures. In fact, MinIO can lose up to half of the drives and nodes without losing any data. Erasure coding is so integral to MinIO that we encourage customers to plan their deployments with our online Erasure Code Calculator.
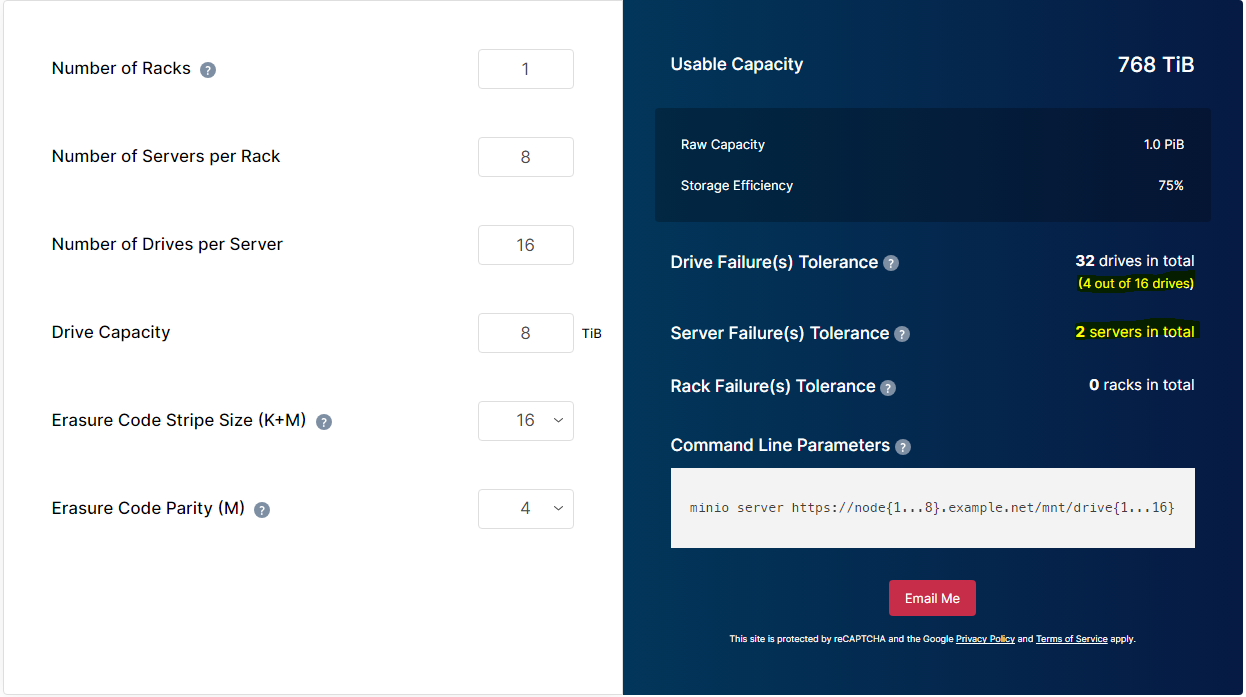
In this post we’ll primarily focus on how to manage drives that are failing. We’ll either try to bring them to a good state or show the best practices on how to replace them altogether without impacting existing operations. Just like a hardware RAID configuration, MinIO allows you to hot-swap failed drives with healthy drives then add those to the pool to get it back into an overall healthy state.
MinIO was designed from its inception with resiliency in mind. It can continue to operate through "typical" drive failures, such as a single drive failure, and also with critical issues such as multiple drive failures – as long as the number of drives failed at once does not go beyond the erasure calculator threshold. It's paramount that bad drives get replaced as quickly as possible because if more drives fail that the configured level of parity then it could cause irreversible data corruption.
Generally, you can remove a drive from the MinIO server by using a simple umount command. You can also use other basic linux tools such as iostat, iotop, SMART warnings, driver errors in system logs and MinIO logs to troubleshoot and repair, or even use dd to write random characters to the failed disk and verify the read/write performance. It probably goes without saying, but we'll say it for the sake of thoroughness, if you remove a drive and dispose of it please make sure to destroy all data on it. It would be pretty tough, if not impossible, to re-engineer erasure coded data from a single drive in a single node, but we don't want anyone taking chances with data.
MinIO partitions each object into data and parity shards and distributes those shards across a single erasure set. For each unique object namespace (BUCKET/PREFIX/[PREFIX/...]/OBJECT.EXTENSION) MinIO always selects the same erasure set for read/write operations. This includes all versions of that same object.
This is best served with a quick visual. Let's say you have a single node with 16 drives. You can configure it with a parity of EC: 4, which is the default, so that up to 4 drives can fail before you are unable to read from the node.
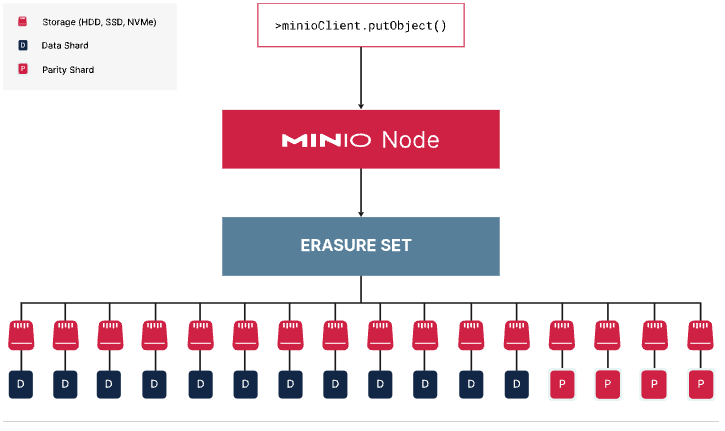
In the EC: 4 configuration, if two of the drives fail, the node uses the data from the data drives and parity drives to service the request.

With the above configuration MinIO supports a drive failure of up to 4 drives per erasure set and still serves write operations. When an erasure set is in a degraded state, MinIO automatically increases parity of the degraded erasureset to meet the same level as the healthy sets. But the degraded set needs to be brought back up to a healthy state as soon as possible as mentioned earlier.
By managing data at a software layer, MinIO forgoes the need for expensive hardware and RAID controllers and simplifies the management of disks without the need to do rebalancing or working with RAID CLI to do drive maintenance.
When a drive is damaged beyond repair and a shard in an erasure set is damaged, once the disk has been replaced with a good one, MinIO can heal the damaged shard using any of the data or the parity shards.
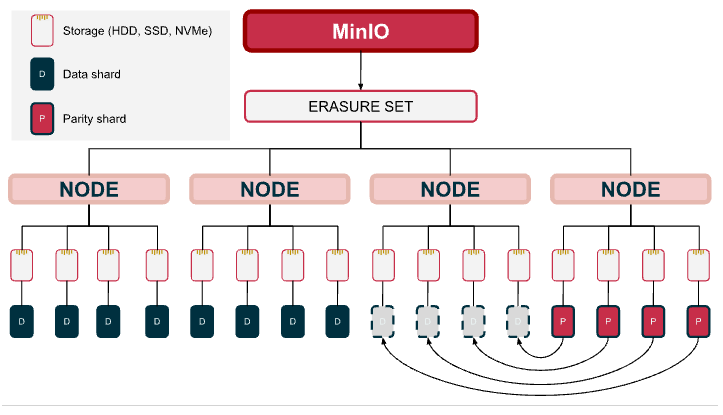
In our previous example, since we configured parity as EC : 4, the erasure set can tolerate a failure of up to 4 drives at any given time.
However, in the event of data corruption, the objects are healed using the data from the data and parity drives. This healing process is transparent to the end-user application as it runs in the background without affecting the performance of the overall cluster. Depending on the amount of data being healed, this process can take anywhere from a few minutes to a few hours. While the disk is being rehydrated, it will immediately start to be used for read and write operations as new data comes in. MinIO does not need to wait until the healing is finished to use the new drive.
The following are some enhancements we’ve made recently to improve healing speed:
- Avoid healing new objects uploaded after healing of a disk is started. This makes healing complete faster if there are active uploads of new objects in a cluster.
- Healing of multiple disks replaced at the same time and in the same erasure set. This makes the healing process intelligent and avoids having to rescan every time for healing.
- We’ve made multiple fixes to resume healing after errors.
- Assigned more workers by default to make the healing faster.
MinIO's erasure coding algorithm ensures corrupted objects are captured and healed on the fly with an implementation designed for speed. MinIO easily hits hashing speeds over 10 GB/sec on single core CPUs.
MinIO can not only withstand several drive failures but also several node and multi-site failures. By default MinIO detects these defective slow drives and removes them out of the erasure set in the server pool. Later, these failed drives can be hot swapped with new drives from which MinIO will start the healing process without impacting any application or cluster performance. We’ll go through a simple early process of how easy it is to replace a drive in MinIO which ensures the consistency and correctness of all data restored onto the drive.
After identifying the failed drive, in this case let's say that was /dev/sdb, let's replace that drive.
Unmount the failed drive device
umount /dev/sdbReplace the failed drive with a known good drive
Format the drive and create a partition
mkfs.xfs /dev/sdb -L DRIVE1Check /etc/fstab to make sure if this drive needs to be added as a new drive or an existing entry has to be modified. This varies from OS to OS and Cloud provider to cloud provider so be sure to use the correct configuration for your drive.
cat /etc/fstabOnce the proper changes have been made go ahead and mount the replaced drive.
mount -aDrivePerf: ✔
NODE PATH READ WRITE
http://minio1:9000 /disk1 445 MiB/s 150 MiB/s
http://minio1:9000 /disk2 451 MiB/s 150 MiB/s
http://minio3:9000 /disk1 446 MiB/s 149 MiB/s
http://minio3:9000 /disk2 446 MiB/s 149 MiB/s
http://minio2:9000 /disk1 446 MiB/s 149 MiB/s
http://minio2:9000 /disk2 446 MiB/s 149 MiB/s
http://minio4:9000 /disk1 445 MiB/s 149 MiB/s
http://minio4:9000 /disk2 447 MiB/s 149 MiB/s
ObjectPerf: ✔
THROUGHPUT IOPS
PUT 461 MiB/s 7 objs/s
GET 1.1 GiB/s 17 objs/s
MinIO 2023-10-03T18:10:45Z, 4 servers, 8 drives, 64 MiB objects, 6 threadsOnce the drive is mounted, fetch the logs of the MinIO server regarding the replaced drive using the mc admin console command. In addition to that, you can monitor the overall healing process using mc admin heal. MinIO ensures all drives are healed in a swift manner without affecting the performance of the overall system.
If you would like to learn more about erasure coding and drive healing in MinIO, please see our MinIO Erasure Code Lab training video.
SUBNET is the way to go
In order to provide a comprehensive understanding of the client system, MinIO developed a capability called HealthCheck, which is available only to commercial customers using the SUBNET subscription portal.
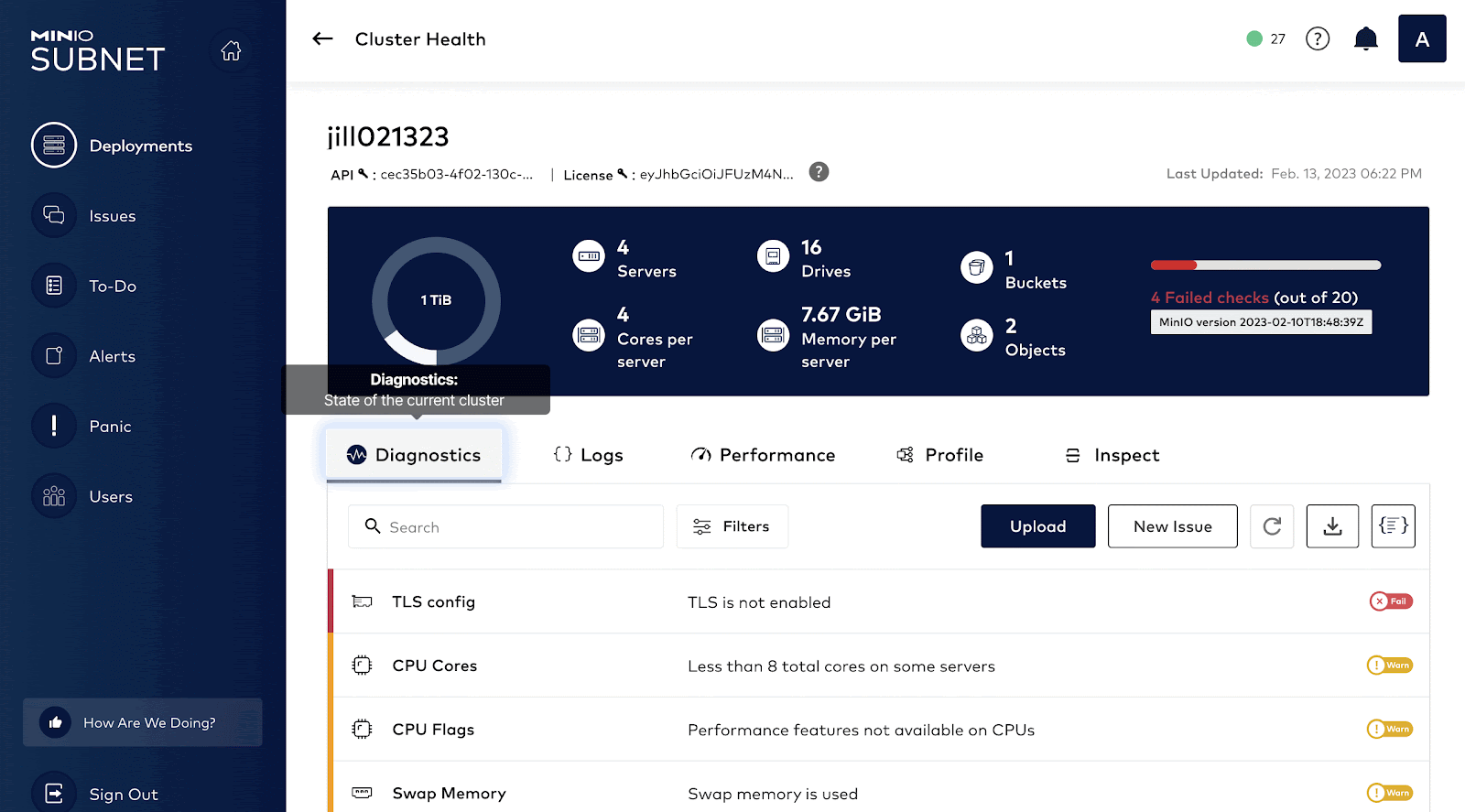
Healthcheck runs continuously on your MinIO cluster and drives and the results are constantly monitored for any failures or decrease in performance.
You can send disk and other logs to SUBNET by issuing the following command
mc support diag minio
● CPU Info ... ✔
● Disk Info ... ✔
● OS Info ... ✔
● Mem Info ... ✔
● Process Info ... ✔
● Server Config ... ✔
● System Errors ... ✔
● System Services ... ✔
● System Config ... ✔
● Admin Info ... ✔
mc: MinIO diagnostics report was successfully uploaded to SUBNET. Please click here to view
our analysis: https://subnet.min.io/health/1/860MinIO SUBNET subscription not only provides 24/7 support to help manage your existing systems but also help you in the initial planning, architecture, implementation and until your cluster is deployed to production. When planning large deployments (> 1PB), we highly recommend having the strategy and architecture reviewed by the MinIO Engineering team to ensure the cluster can be scaled easily and grow with you as your needs grow.
For more information, ask our experts using the live chat at the bottom right of the blog to learn more about the SUBNET experience.






