Turbocharging MinIO Data Lakes with Apache Arrow

More and more enterprises have begun or have already implemented a data lake strategy based on some of the work we did a couple of years ago. If you want to take a moment to review - you can find those posts below here and here.
Objective
In this article, I am going to explain a mechanism to turbocharge the use of MinIO. Nothing changes as far as MinIO is concerned, the optimization will be on the underlying storage of our data. We are going to choose one of the latest formats to improve agility manifoldly. We are going to show the ways by which your data lake data can travel across systems without experiencing any "conversion" time.
Apache Arrow
I believe understanding this article needs some basic concepts of how applications like Spark works. Let me explain it in simple terms.
Imagine you got a nice job at a location different from where you live currently and you want to relocate, as the new company demands it and pays for it. You have got the most modern televisions, refrigerators, super soft leather sofas, bed and so on. You engage a moving company, who comes, disassembles everything, packs it conveniently. They also make sure to pack as much possible in containers to fill the truck such that they can do it in a single trip. Once they reach the destination, they unpack, assembles and restore everything as it was.
The same applies to data. When I store some data in MinIO , and I need to feed it to, say, another application, say Spark, the consuming application needs to disassemble the data from MinIO data lake, pack it and transport it through the wire (or wireless), receive, unpack and re-assemble.
Let's use more technical terms for this disassembly and assembly - serialization and de-serialization of data. The unfortunate part is, both these processes are complex and time consuming. Here is a brief diagram illustrating what happens in Apache Spark when it reads data
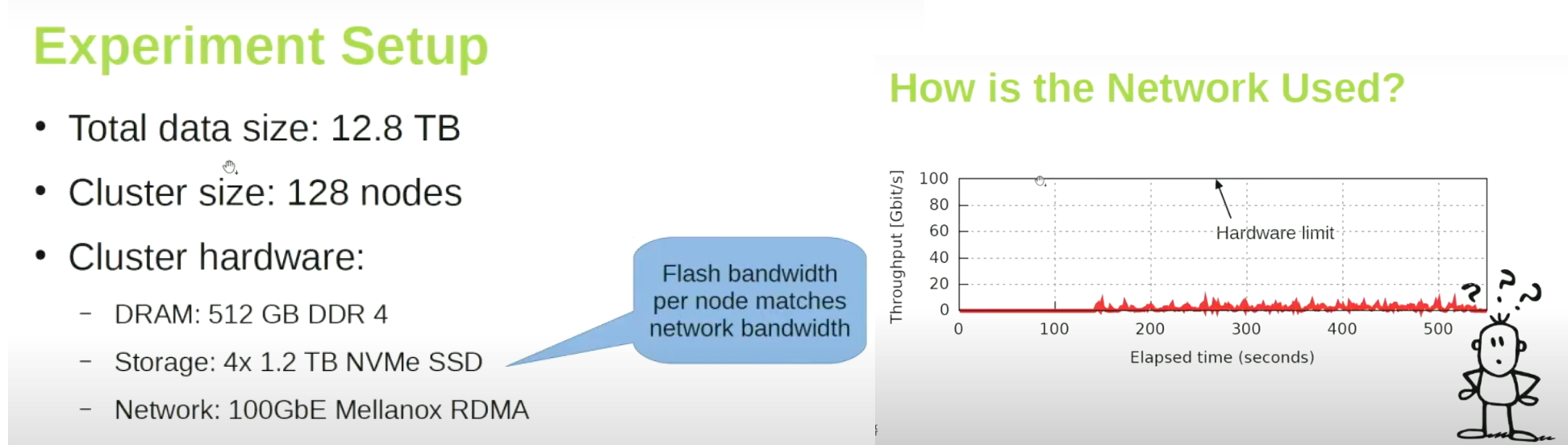
You may not have noticed this problem before. Assume that MinIO is on a machine(s) on the network. We write a Spark Map-Reduce application. Eventhough the network limit is 100 GbE, we are almost getting less that 10 GbE speed. What's the use of this high speed network then? What is the potential problem which is not allowing us to utilize the full potential of the network, or at least 70-80% of it?
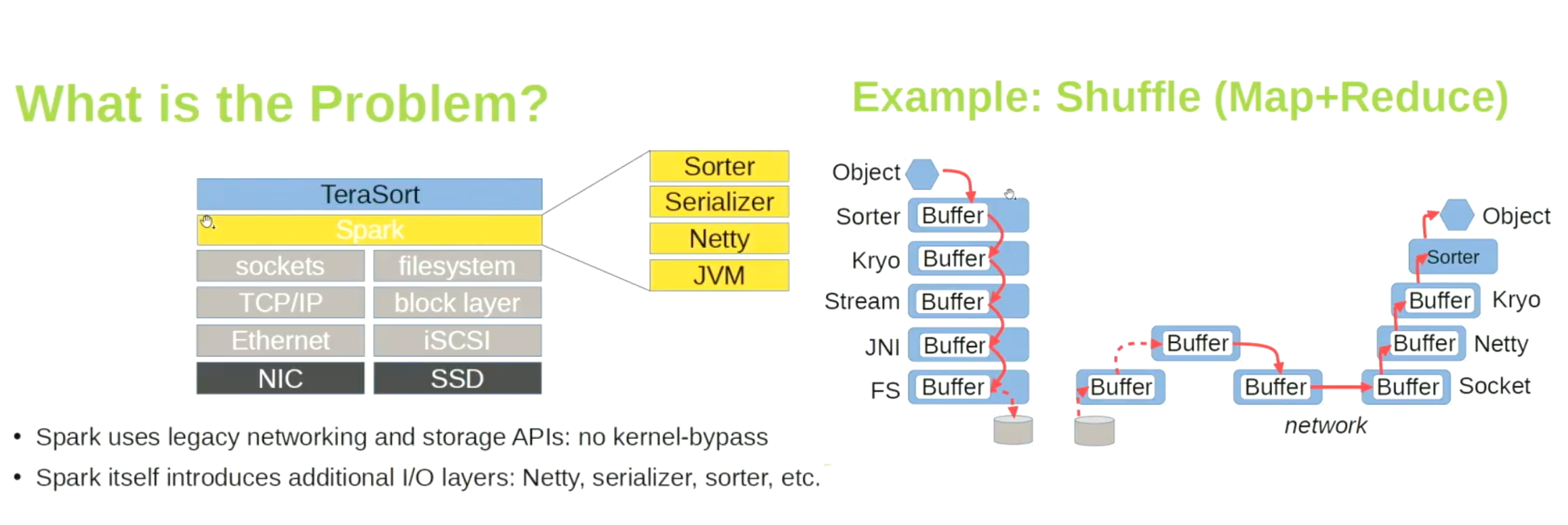
The issues are with the way in which Spark is retrieving the data. Look at the number of layers the data has to pass though. This creates a limit on the throughput that we can achieve. There are projects like Apache Crail, which are designed to address these issues.
Optimization : Columnar Data Format
If we think about the relocation example mentioned above, we see that the logistic company will never take the sofa as it is, they will break it down to make it easy to transport. Note that this is for transportation purposes only - if that objective is different, then disassembling the sofa might not be the right approach.
Given that the objective for a data lake is analytics - rather than transactional needs we must take that under consideration. For transactions, we often use OLTP systems like Oracle or PostGres - given that they are particularly well suited for the job. A quick review of OLAP's analytics requirements is probably in order.
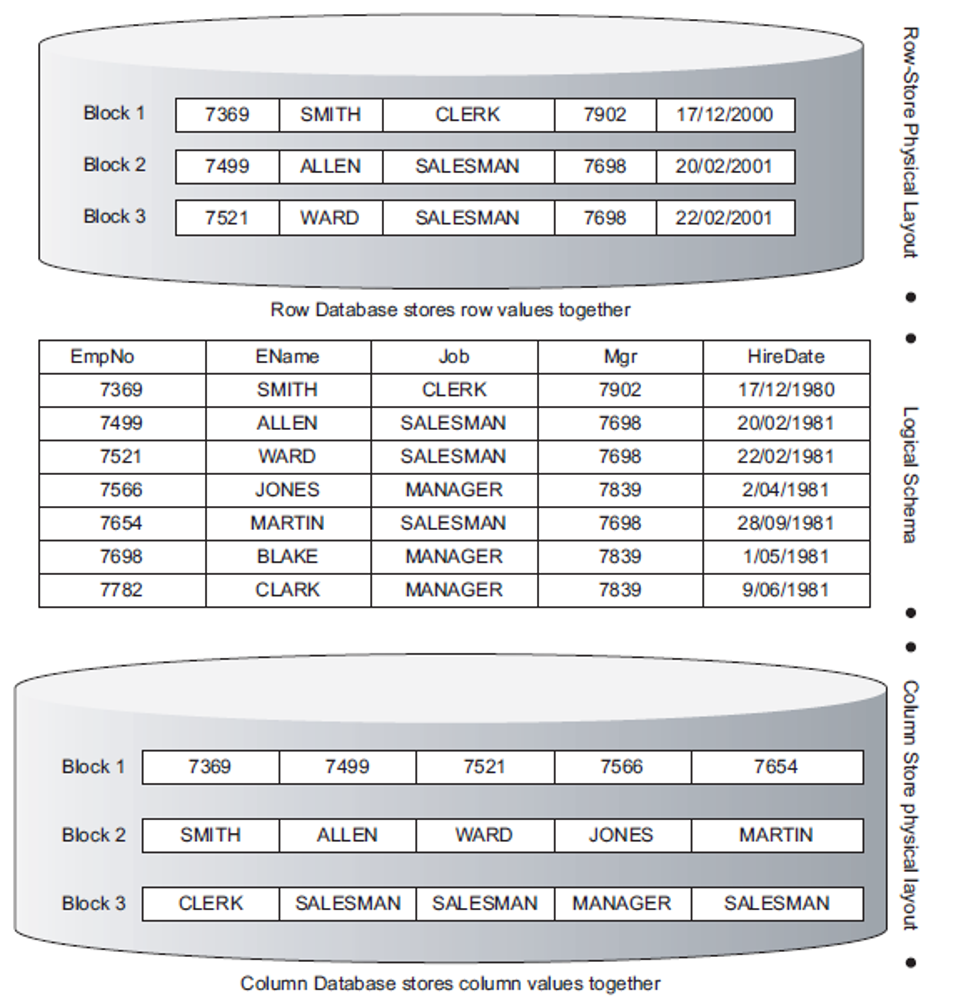
Let's start with one of the most famous RDMBS table - the "emp" table of Oracle. The top part shows how the data is stored in RDBMS as a "relation" or "tuple". We call it a table. I am providing you two queries
- select ename from emp where job = 'CLERK'
- select sum(sal) from emp
The first is a transactional query. It has to scan every row on the table and find out the name of the employee wherever the job is clerk. The second is an analytical query - rather than an atomic result, the goal is a general result. Unfortunately, the first and second query has to scan through all the rows, if we use RDBMS way of representation of data. If the size of data is 20 GB, all the 20 GB more or less will be scanned. This is the top part of above figure.
Let's make some changes - taking all of our columns and make them into rows. Like a transpose of a matrix - and see the bottom part of above figure, how your data will look like. Following this transposition, an entire block is just representing one column. How many blocks need to be scanned for the second analytical query? Just one block, probably around 2 GB of size.
The difference is significant? Columnar representation is what is being used in ORC (Optimized Row Columnar) and Parquet files - with the goal of making the analytics faster.
Columnar formats are easier to read, however, they pose another problem - they are usually stored in compressed format. As a result, the consuming application will need to uncompress it while reading and compress it back while writing.
Note this, as we will revisit the point later.
The Science of Reading/Writing Data
Let me explain briefly how reading/writing happens in a software system and what role is played by the hardware.
Microprocessors normally use two methods to connect external devices: memory mapped or port mapped I/O.
Memory mapped I/O is mapped into the same address space as program memory and/or user memory, and is accessed in the same way.
Port mapped I/O uses a separate, dedicated address space and is accessed via a dedicated set of microprocessor instructions.
In memory mapped approach, I/O devices are mapped into the system memory map along with RAM and ROM. To access a hardware device, simply read or write to those 'special' addresses using the normal memory access instructions.The advantage to this method is that every instruction which can access memory can be used to manipulate an I/O device.
Usually applications use Port mapped I/O. If we are using memory mapped I/O for a particular format, it will be faster, especially for analytical needs. When combined with our columnar data format, then it becomes even more advantageous.
Welcome to Apache Arrow.
Arrow uses memory mapped I/O and avoids serialization/deserialization overheads when you convert between most of the formats while leveraging the columnar data format.
Thanks to Wes McKinney for this brilliant innovation, its not a surprise that such an idea came from him and team, as he is well known as the creator of Pandas in Python. He calls Arrow as the future of data transfer.
Store Data in MinIO in Arrow Format
This is how we are going to make MinIO even more powerful.
We are going to store that data in Arrow and then let the consuming applications read it - resulting in dramatically increased speeds. Step one has us putting the data into MinIO in Arrow format. I was using my own approach until I saw a much better implementation from Bryan Cutler, whose contributions include integrating Arrow formats to Spark as well.
We will start with a a .csv file, in this case movie ratings downloaded from the movielens site. For illustration purposes, I took about 100K rows. First, let's write a Spark program to read this CSV file and write it into Arrow format using Arrow RDD. You can get the full code from the link given towards the bottom of this article.
Step 1: build.sbt , please note the arrow dependencies
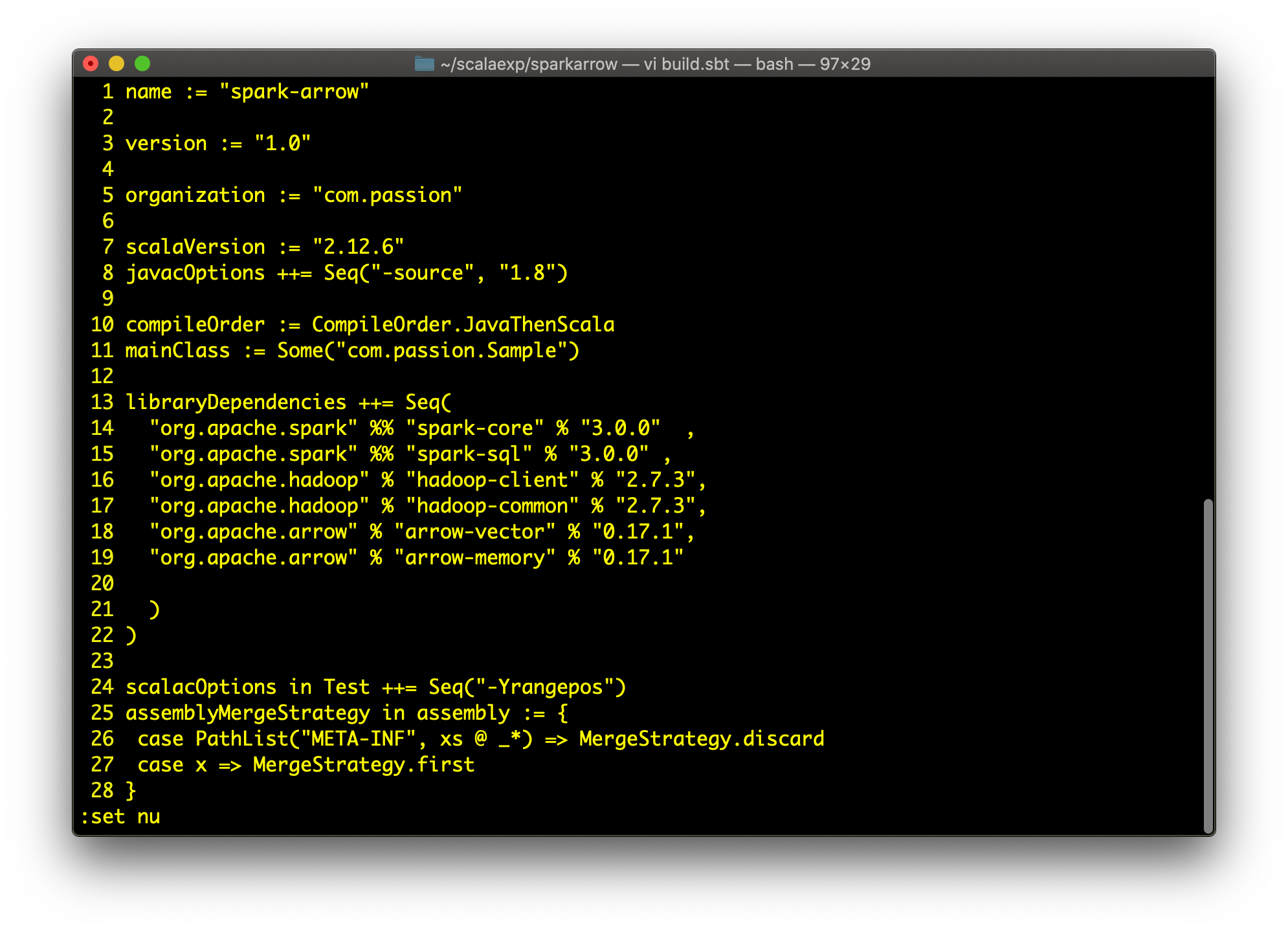
We will use Spark 3.0, with Apache Arrow 0.17.1
The ArrowRDD class has an iterator and RDD itself. For creating a custom RDD, essentially you must override mapPartitions method. You can browse the code for details.
Next, start MinIO and create a bucket named "arrowbucket".

Let's use ArrowRDD and create an ArrowFile in local. Here is the code:
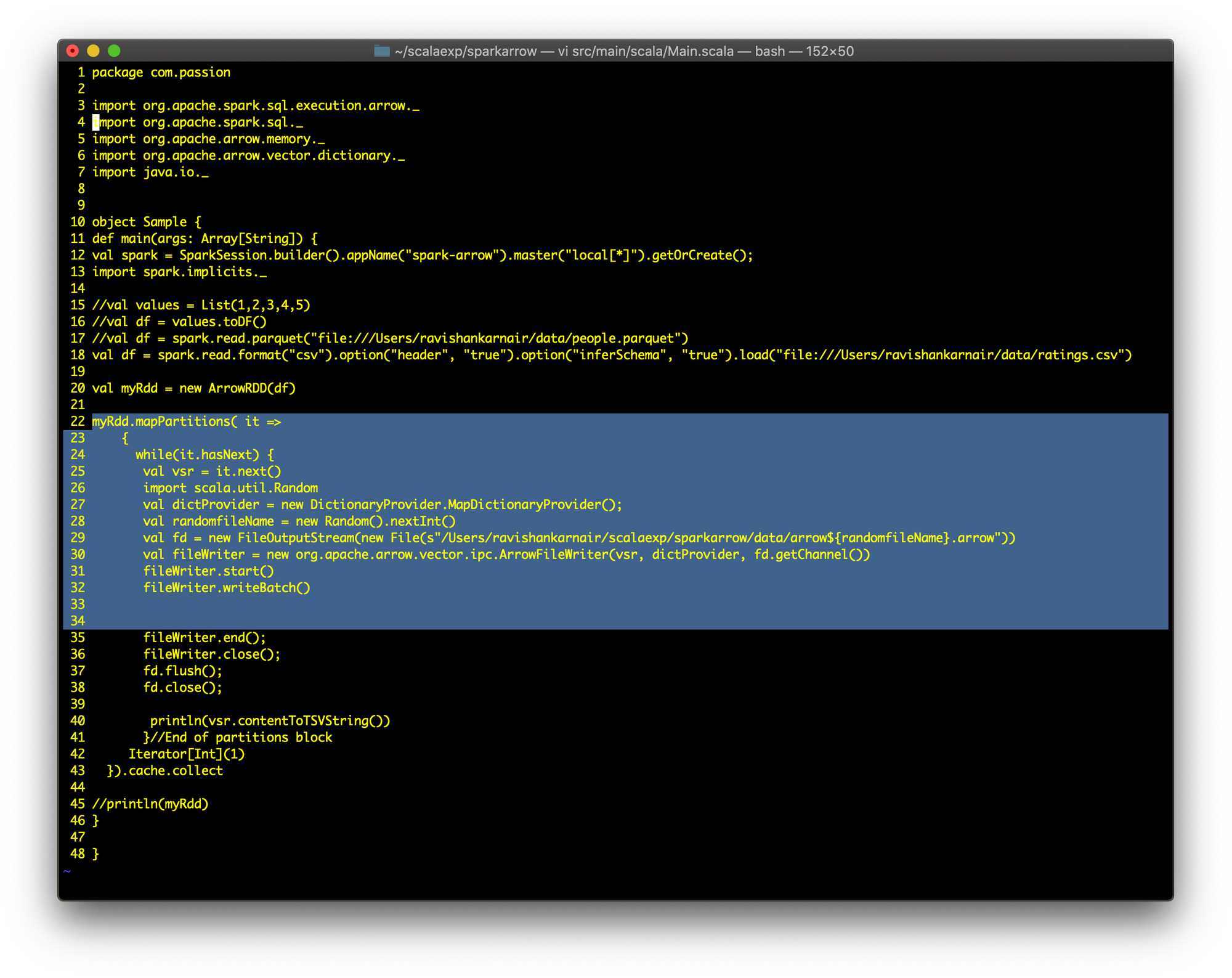
Lines 22 to 34 do the main part. Compile and execute the code:
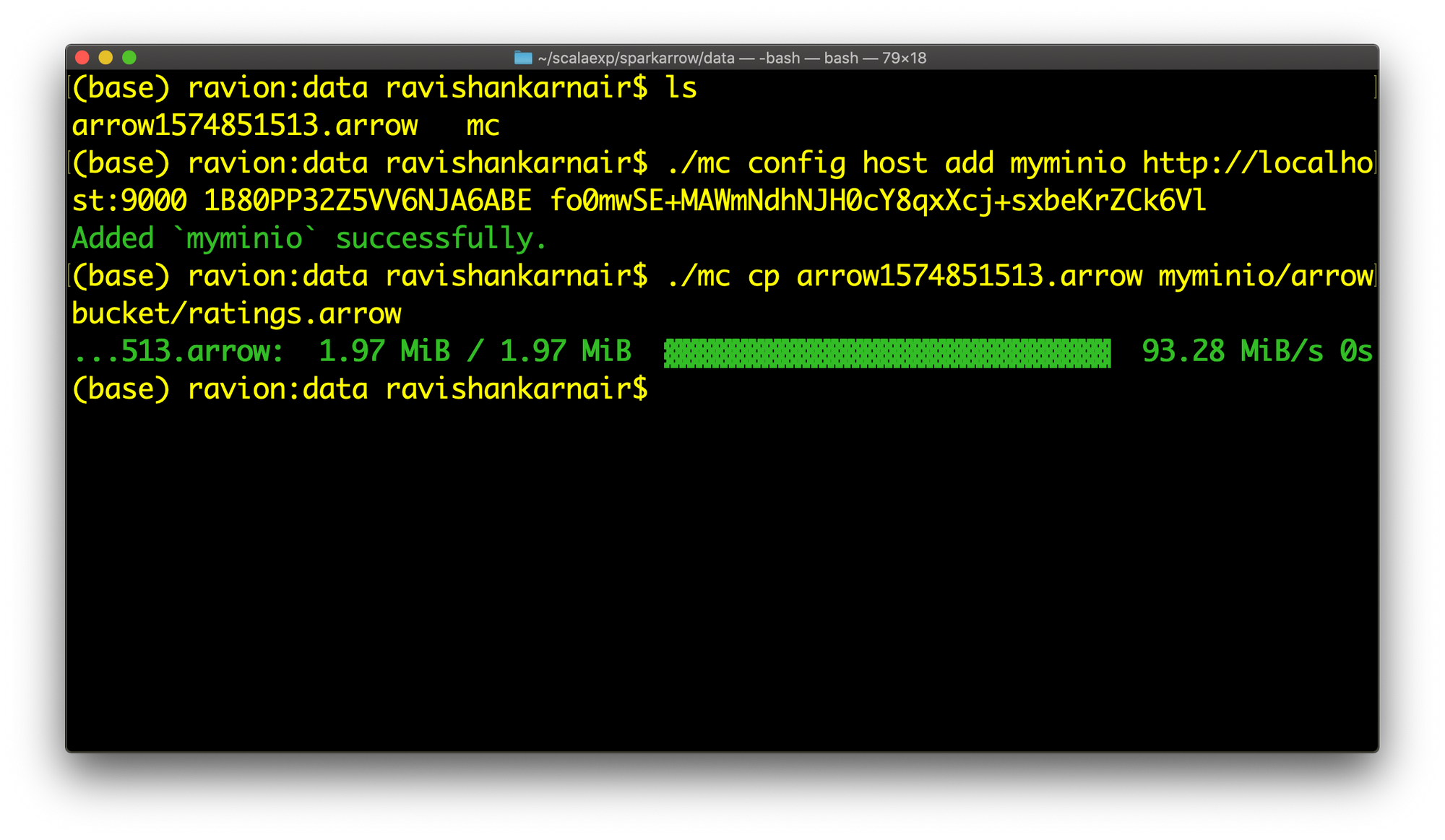
As you see from code, the Arrow format file is is generated in data directory. Let's copy it to the MinIO bucket we created earlier (bucket name is arrowbucket)
Let's have some fun now.
Use your favorite Python editor, and write some code. First, let us start with Spark reading the file and converting it to a dataframe, with and without Arrow enabled options.
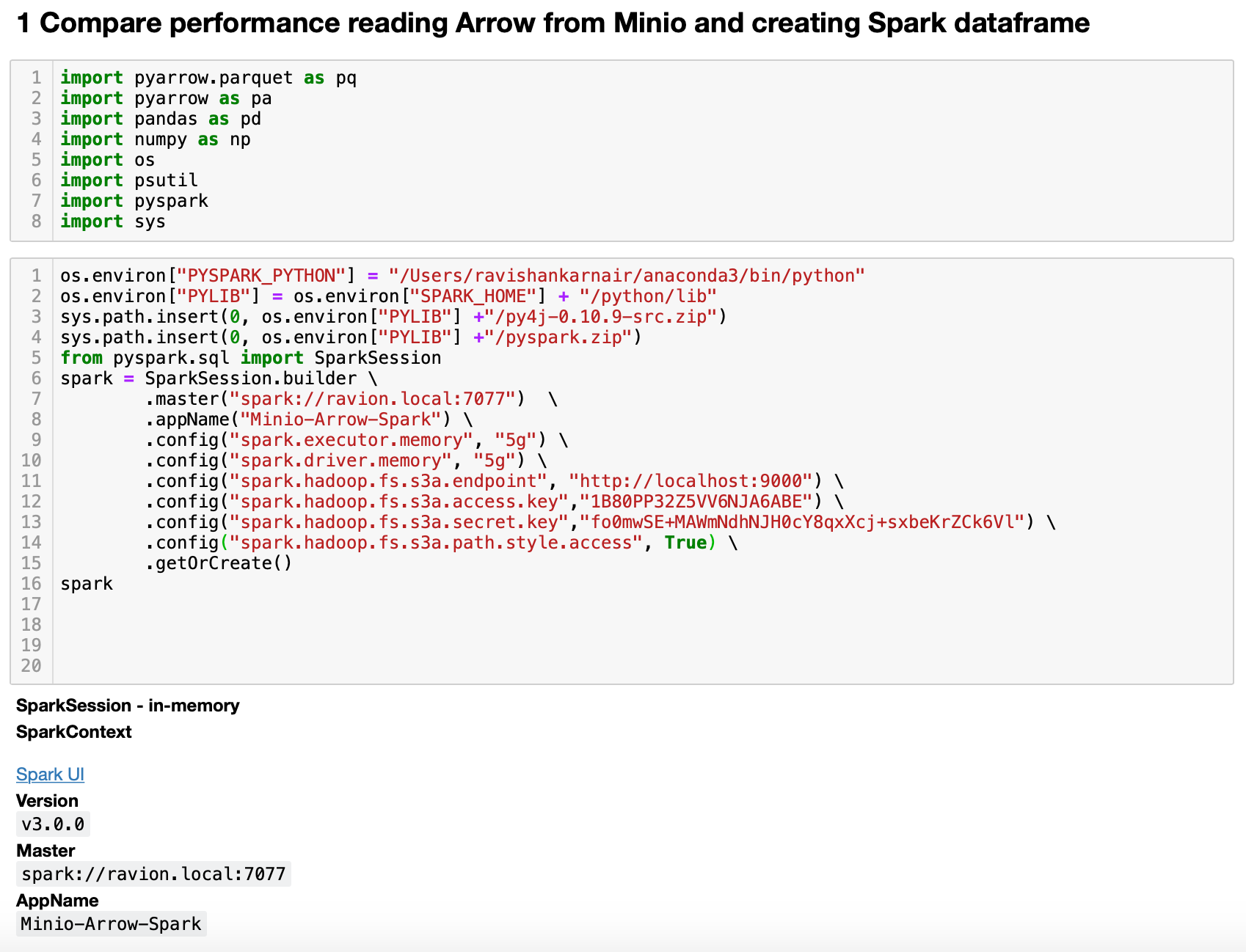
Start your Spark cluster. Complete the code with all settings and check whether we created the Spark context successfully. To ensure that our app (named Minio-Arrow-Spark at line 8) is connected, just check the Spark UI. You should see something like this:
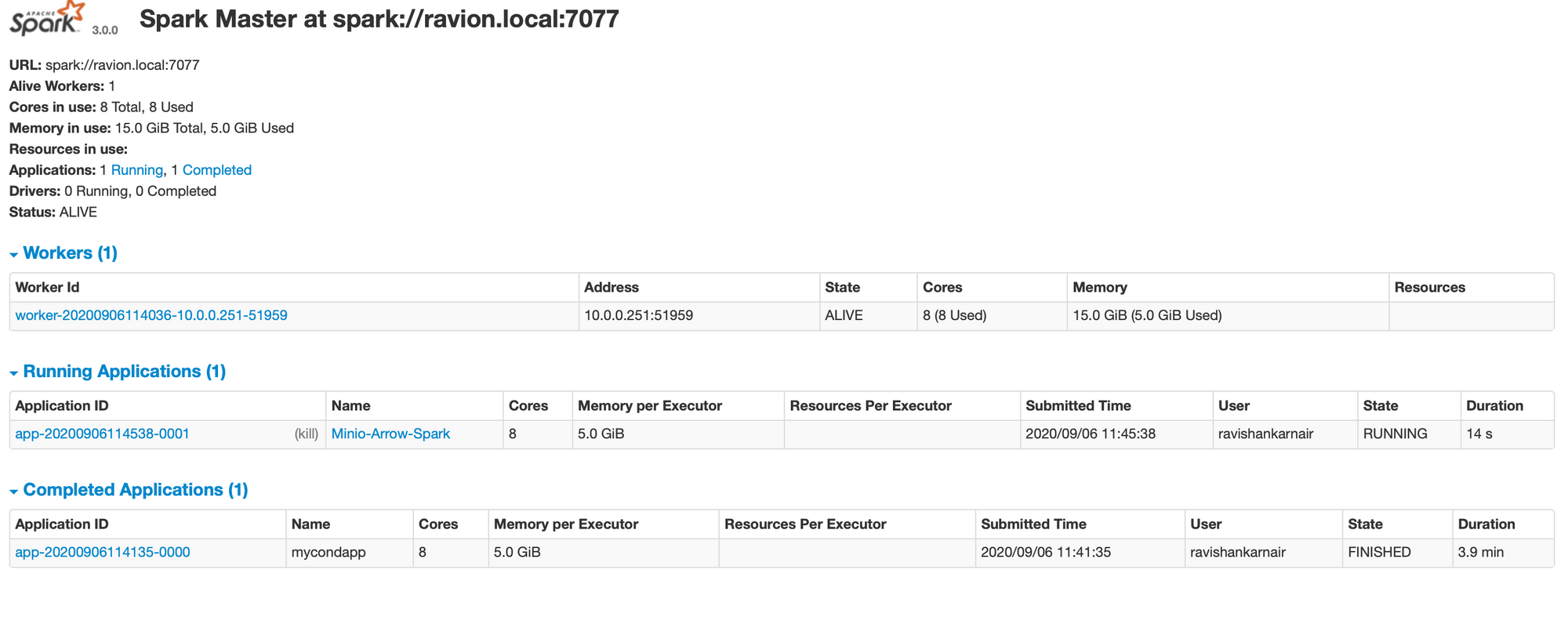
Run the below code now:
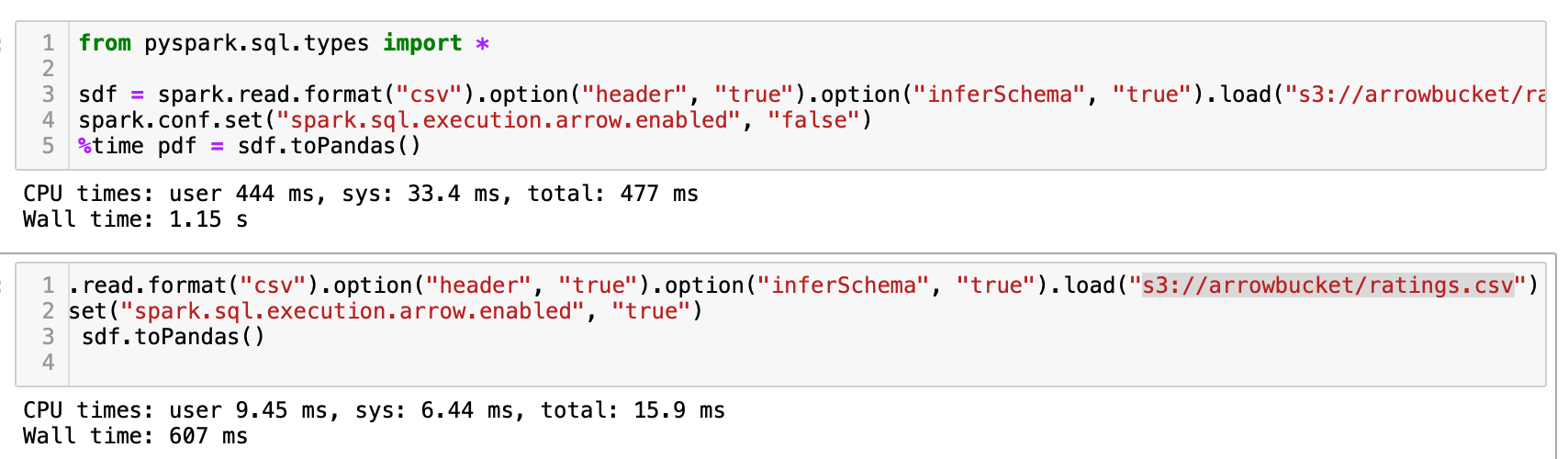
The output which displays the time, shows the power of this approach. The performance boost is tremendous, almost 50%.
Recall that we created an ArrowRDD earlier and used it to write to MinIO. Let us test the memory consumption in reading it. We will use different methods.
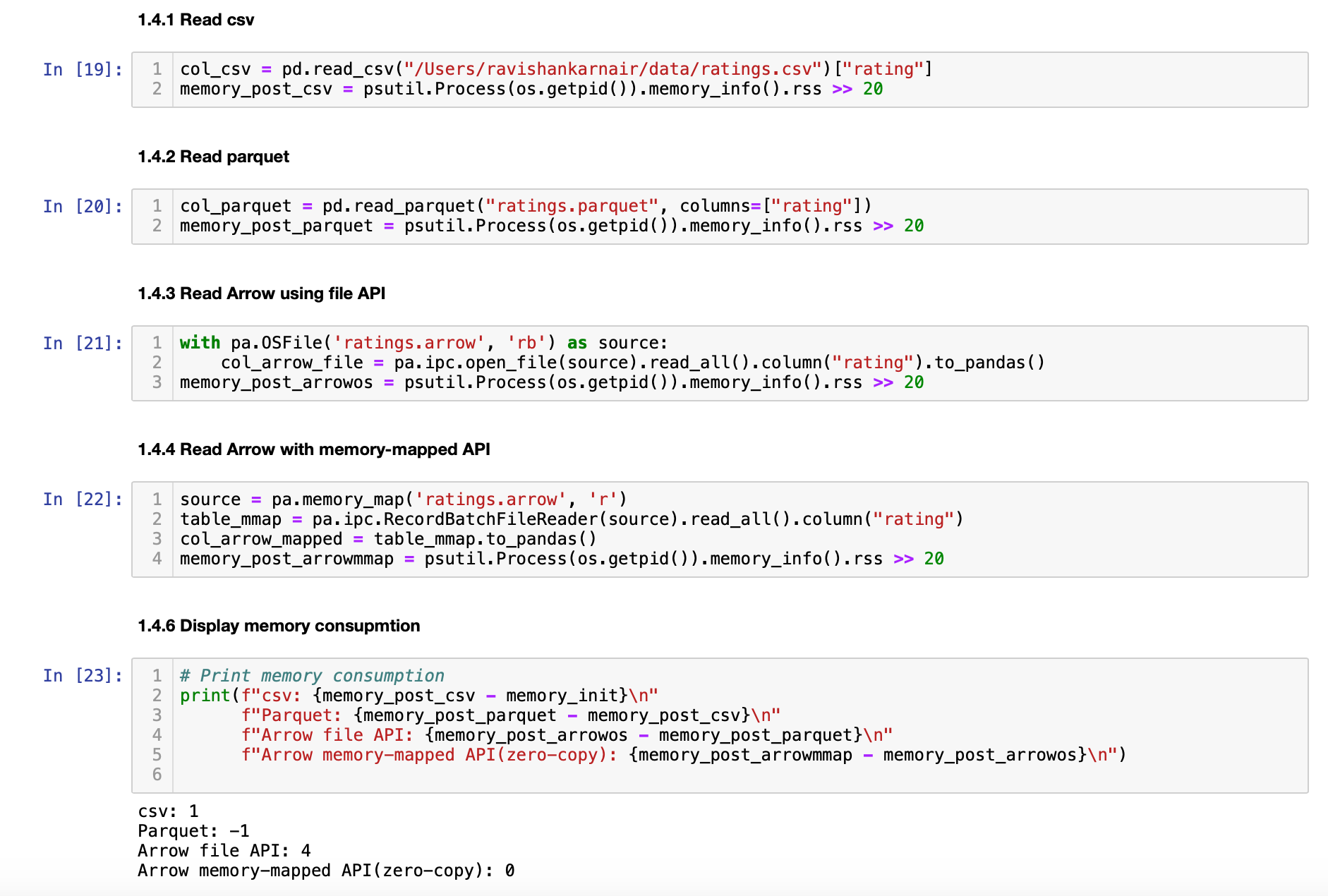
We are reading different file formats and seeing the memory consumption for each. As it is evident, Arrow format based files are zero copy - almost no memory consumed at all.
By combining MinIO with the Arrow Format, you can enhance your analytics ecosystem and virtually eliminating the friction associated with converting between different formats. This is primarily due to the reduction of serialization overhead.
Code
You can see the Jupyter notebook and ArrowRDD code here.
About the author
Ravishankar Nair is a technology evangelist, a consultant and an inspiring speaker. He is the CTO of PassionBytes, based in Florida. With his vast expertise in data engineering, Ravi provides consultancy in machine learning, modern data lakes and distributed computing technology. You can refer to his other articles related to MinIO here:
1) Modern Data Lakes with Minio - Part 1
2) Modern Data Lakes with MinIO - Part 2
3) Building an on-premise ML ecosystem with MinIO Powered by Presto, R and S3 Select Feature
You can connect Ravi on LinkedIn.






