Data Lake Mysteries Unveiled: Nessie, Dremio, and MinIO Make Waves

Many of us have made changes to data based on requirements that later evolve. By the time we realize it, it becomes impossible to roll back. Change isn't just a constant; it's an essential part of managing data that demands a sophisticated approach. Enter the Git-like functionality of Dremio's data catalog Nessie.
Just as Git has become fundamental to software development, data engineers need similar tools to work in parallel, compare data versions, promote changes to production and roll back data when needed. Nessie provides data engineers with a Git-like version control system for managing data versions, branches, merges, and commits. This can be very helpful when multiple data engineers are working with and transforming data at the same time. Nessie allows each engineer to work in separate branches while maintaining a single source of truth in the form of the main branch. This functionality empowers data engineering teams to maintain data quality collaboratively in the face of unrelenting change.
This article provides a step-by-step guide demonstrating how Nessie, Dremio and MinIO work together to enhance data quality and collaboration in your data engineering workflows. Whether you're a data engineer, ML engineer, or just a modern data lake enthusiast, this blog equips you with the knowledge and tools needed to effectively enhance your data versioning practices.
Understanding the Basics: Nessie Workloads
Nessie allows for Git-like workloads that let you test, develop and push to production. Let's break down some key concepts:
- Branches: Just like in Git, branches in Nessie allow you to work on different data engineering tasks concurrently. For example, you might have a branch for feature development, data cleaning and data transformation. Each branch can have its own set of data changes.
- Commits: In Nessie, a commit represents a snapshot of the data at a specific point in time. When you make changes to your data, you create a new commit, which records those changes. Commits are linked to a specific branch. When you need to revert your data to a stable or known-good state, Nessie makes it easy to select a specific commit and roll back to that data version. This ensures data quality and consistency.
- Merges: Nessie allows you to merge the changes from one branch into another. This is similar to merging code changes in Git. When you merge a branch, the data changes made in that branch become part of the target branch.
The Components
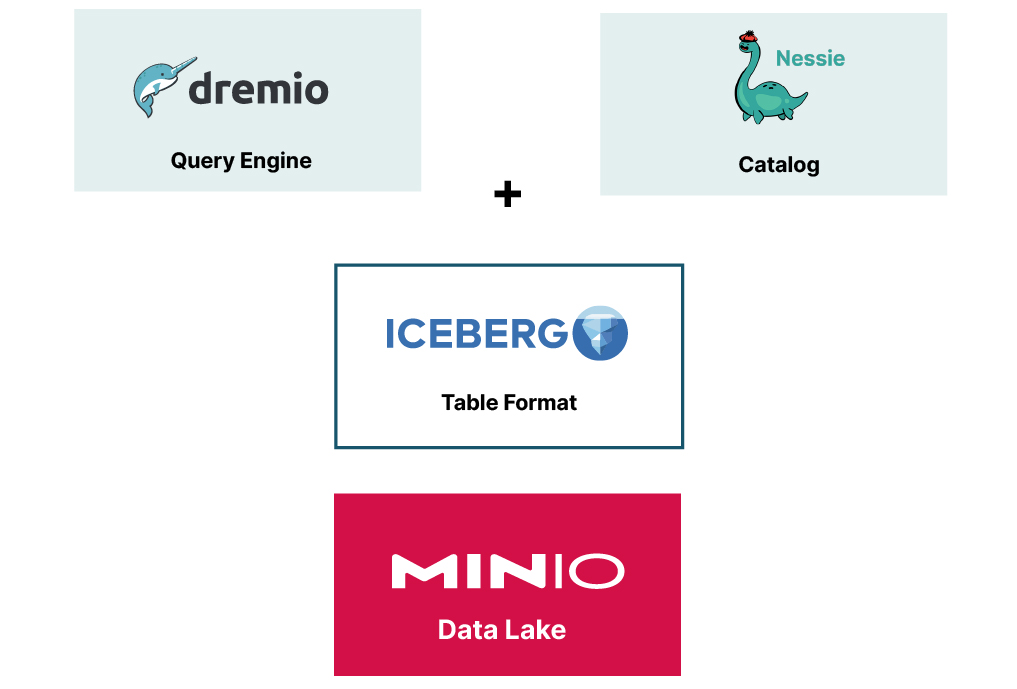
Dremio is a distributed analytics engine that operates as an open-source platform, offering an intuitive self-service interface for data exploration, transformation and collaborative work. Its design is grounded in Apache Arrow, a high-speed columnar memory format.
We’ve already explored how to deploy Dremio with Kubernetes, and also how to query Iceberg tables on MinIO with Dremio. For additional information about Dremio, consult Dremio Resources.
MinIO is high-performance object storage. Renowned for its exceptional speed and scalability, MinIO serves as a pivotal component in building and maintaining modern data lake infrastructures. MinIO empowers architects to efficiently manage and store massive volumes of data on-prem, on bare metal, on the edge, or on any of the public clouds.
Apache Iceberg is an open table format suited for managing large volumes of data in data lakes. Unique features like time travel, dynamic schema evolution, and Partition Evolution make it a game-changer, allowing query engines to work concurrently on the same data safely and efficiently. See The Definitive Guide to Lakehouse Architecture with Iceberg and MinIO for more information about Iceberg features.
Getting Started
You’ll need the Docker Engine and Docker Compose for this tutorial. The easiest way to get both if you don’t already have them is to install Docker Desktop.
This part of the tutorial is based on Dremio’s blog post. You can get the repo for this project here.
To begin, open a terminal and navigate to the folder where you cloned/downloaded the repo, and run the command below to start up Dremio.
docker-compose up dremioWait a few moments and then navigate to http://localhost:9047 to access Dremio. Update the requested fields and then click Next.
Next, run the following command to start MinIO.
docker-compose up minio
The final docker-compose up command below will start up Nessie.
docker-compose up nessieNavigate to http://localhost:9001 to log in to MinIO with the username and password of minioadmin:minioadmin. You’ll be prompted to create a bucket.
Make one named iceberg-datalake.
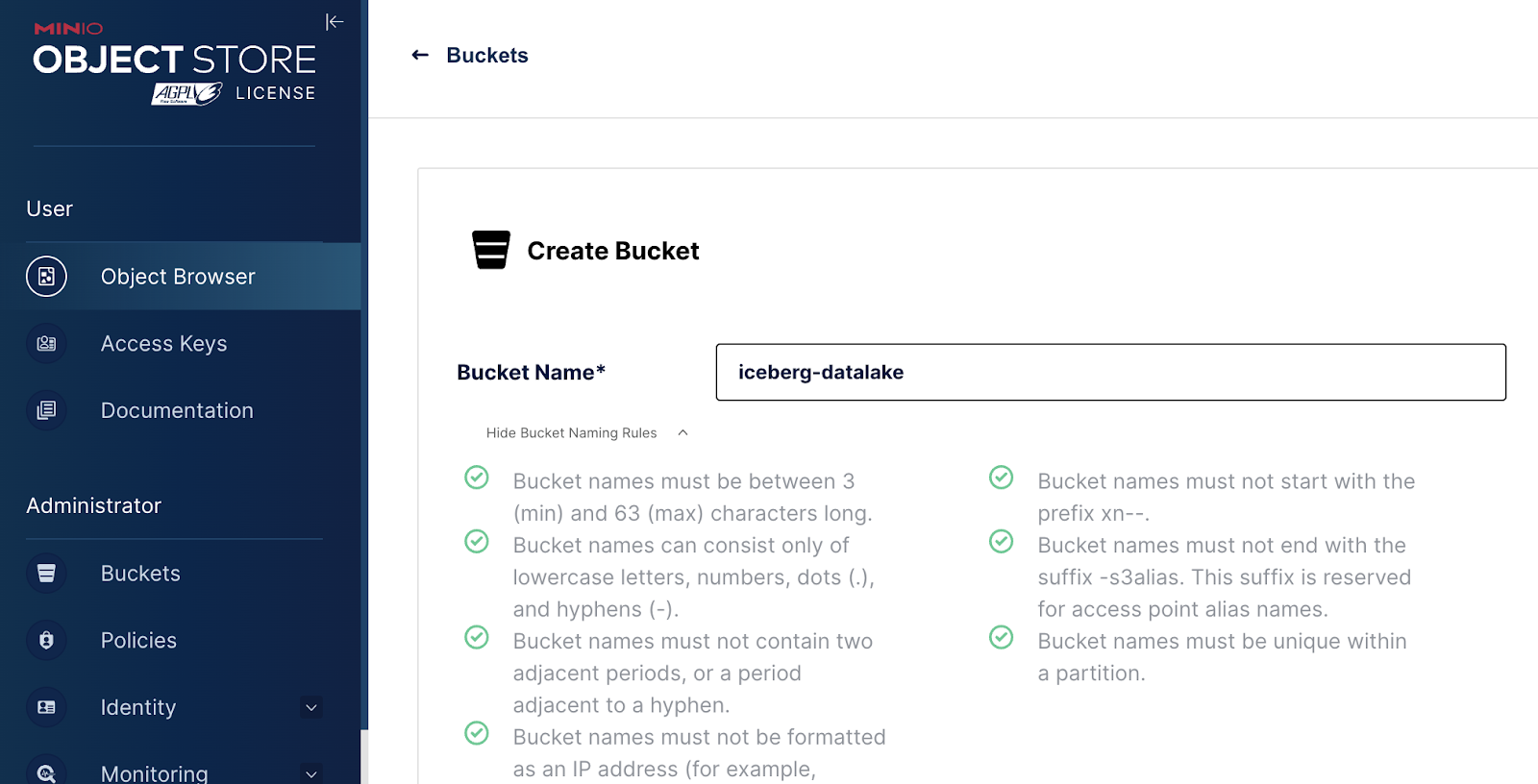
Then head back over to Dremio at http://localhost:9047 and click on Add Source and select Nessie.
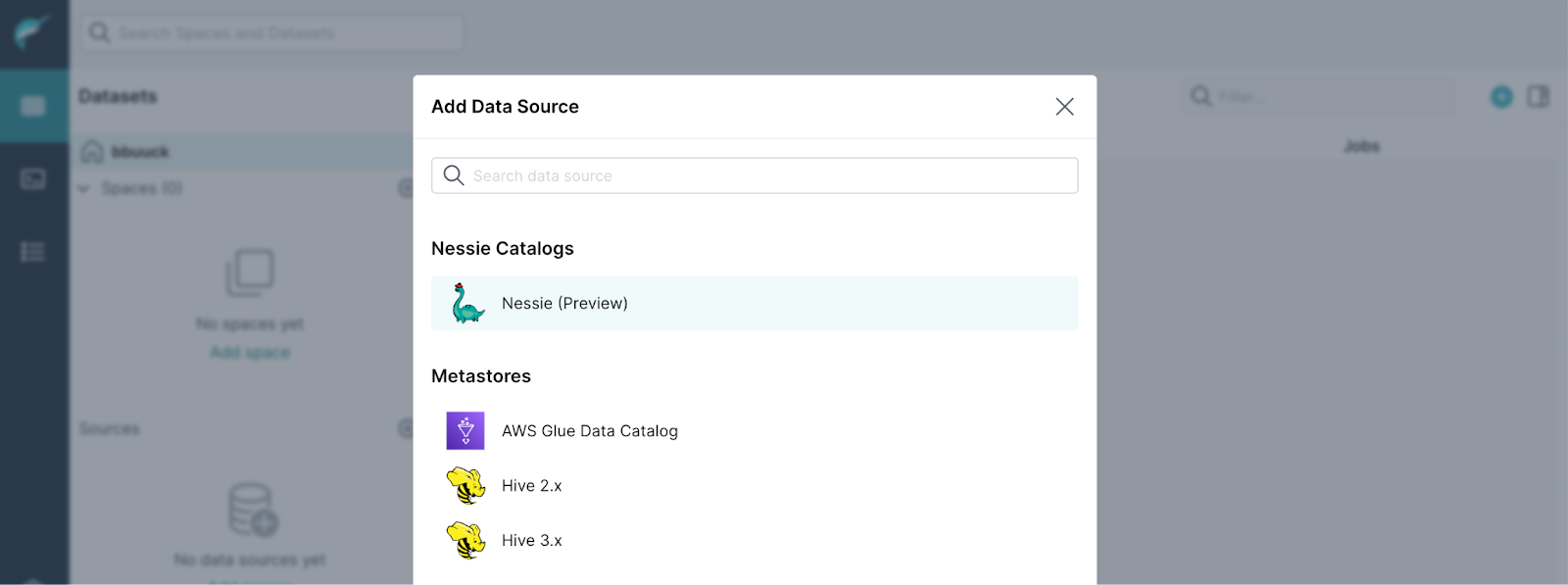
- Set the Name to
nessie - Set the endpoint URL to
http://nessie:19120/api/v2 - Set the authentication to
none
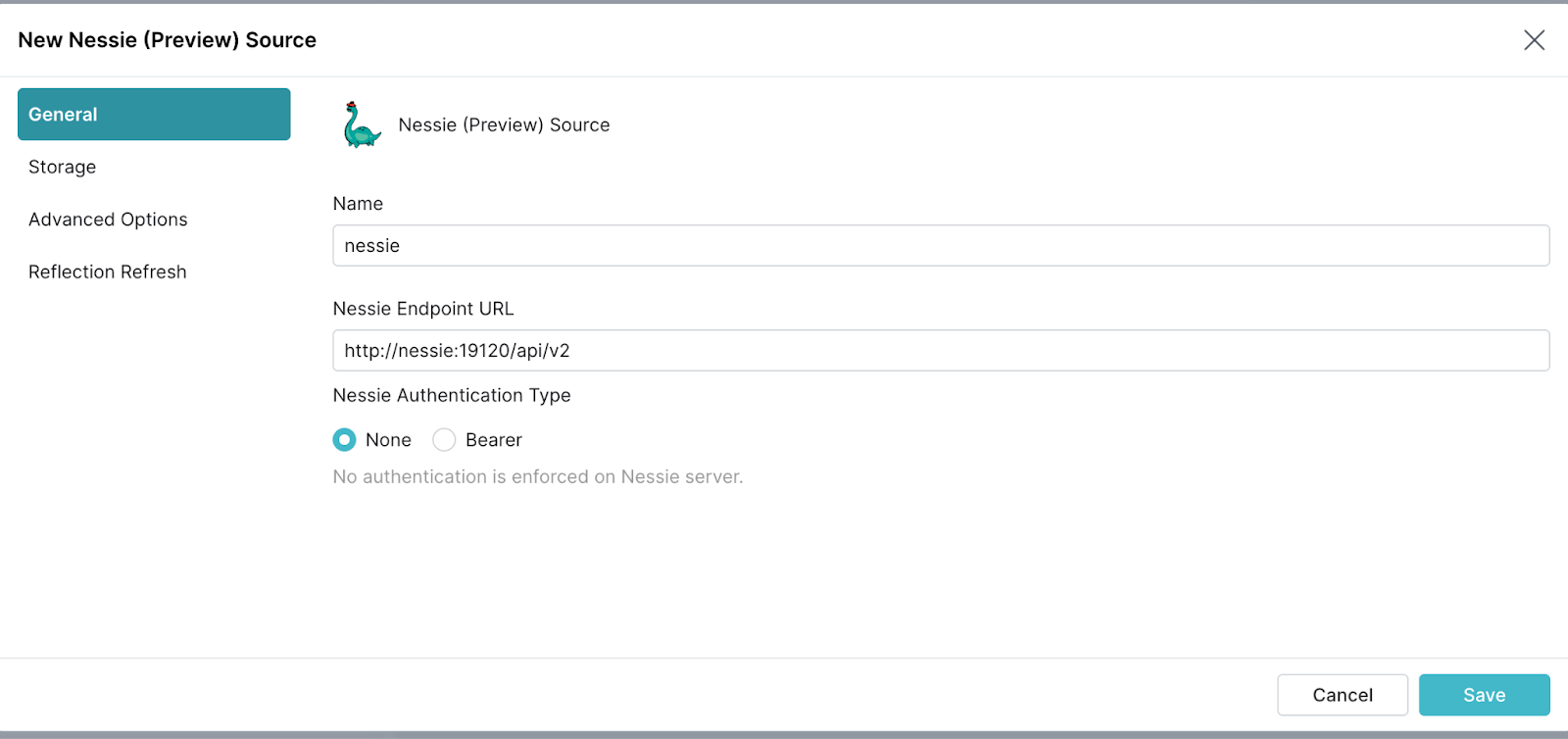
Don’t click Save yet. Instead, in the navigation panel on the left, click Storage. MinIO is S3-API compatible object storage and can use the same connection pathways as AWS S3.
- For your access key, set
minioadmin - For your secret key, set
minioadmin - Set root path to
/iceberg-datalake
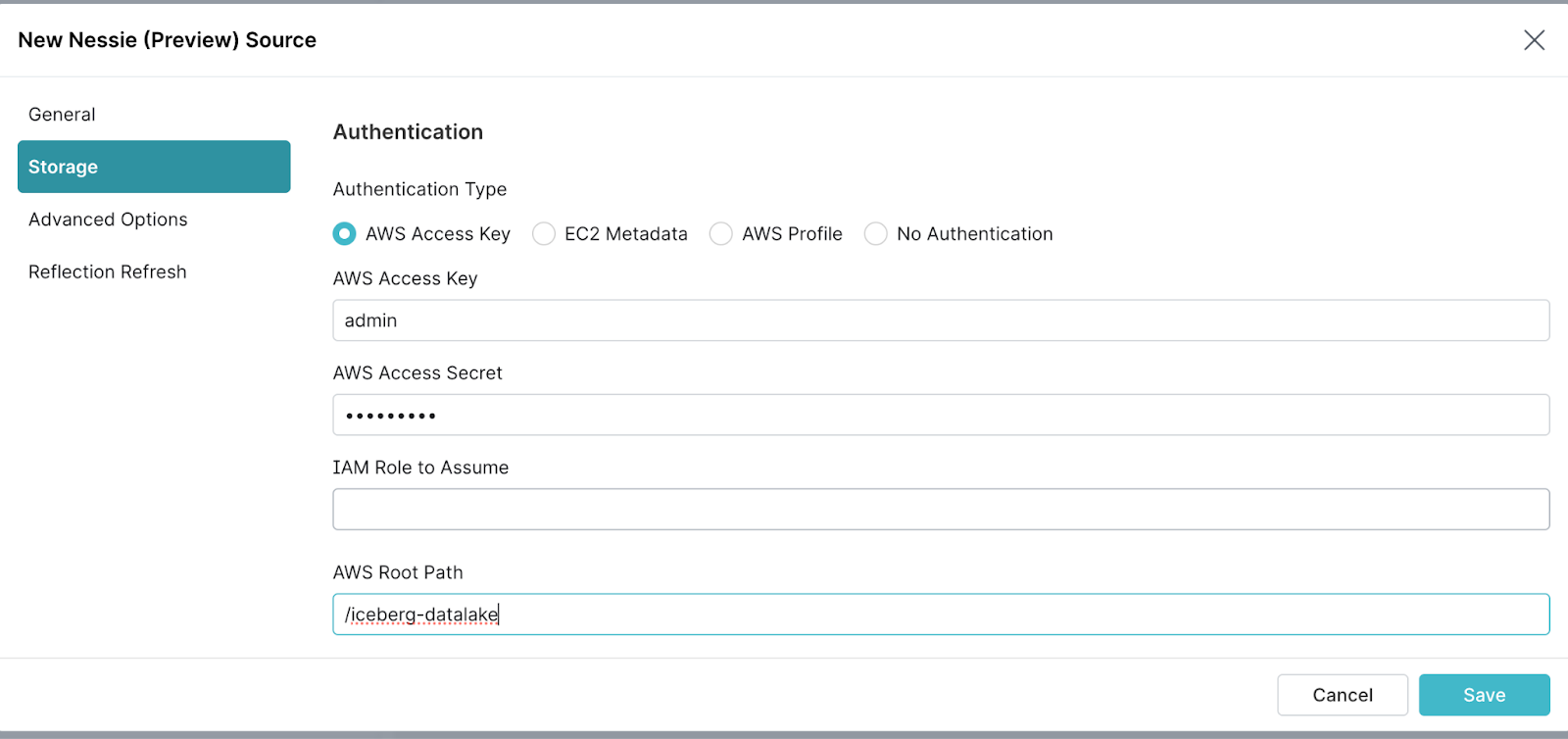
Scroll down for the next set of instructions.
- Click on the
Add Propertybutton underConnection Propertiesto create and configure the following properties.fs.s3a.path.style.accesstotruefs.s3a.endpointtominio:9000dremio.s3.compattotrue- Uncheck
Encrypt connection
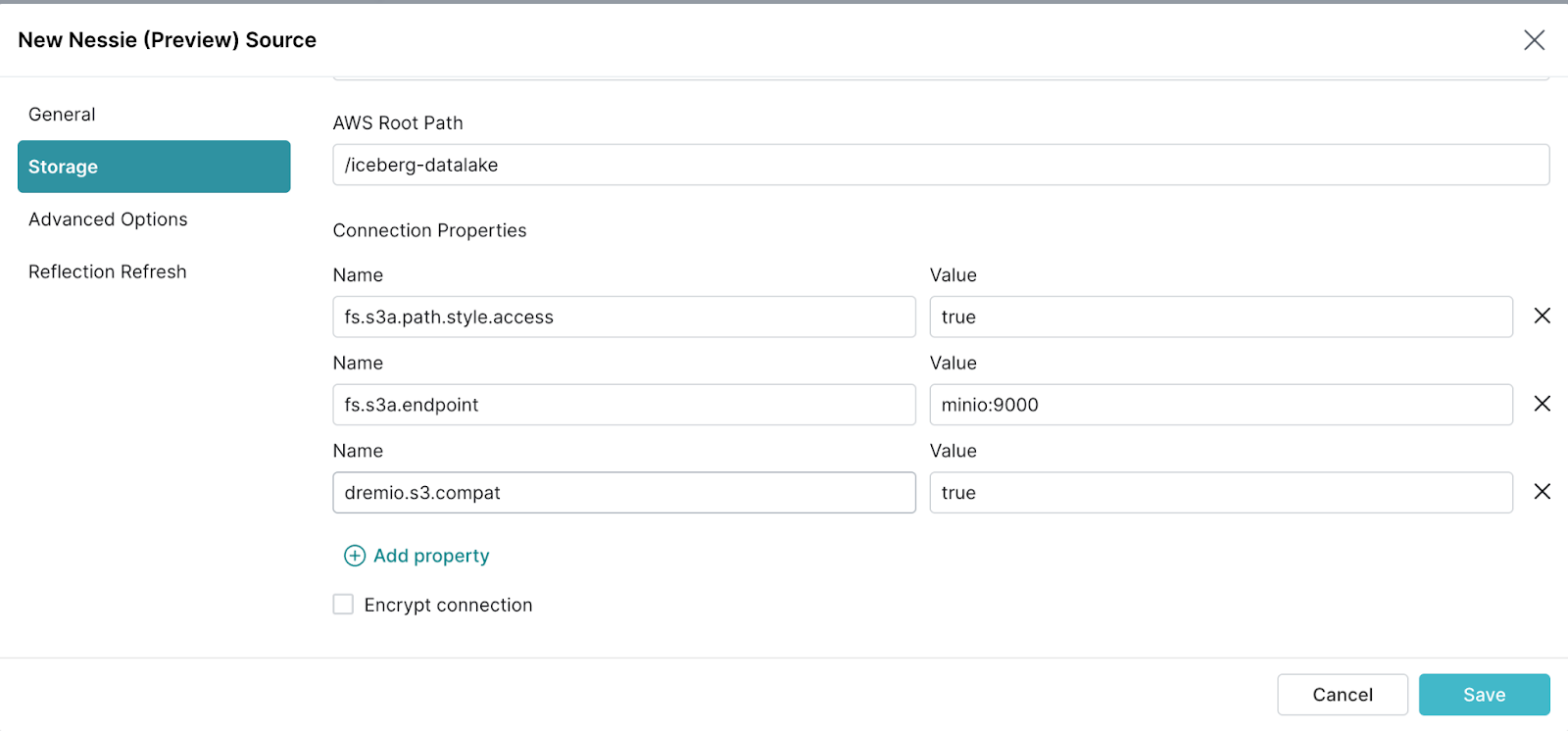
Then click Save. You should now see Nessie Catalogs in your data sources.
Create a Data Source
In Dremio navigate to SQL Runner on the left-hand side. Make sure that Context in the upper right area of the text editor is set to our Nessie source. Otherwise, you will have to reference the context like nessie.SalesData instead of just SalesData to run this query. Copy and paste the SQL below and run.
CREATE TABLE SalesData (
id INT,
product_name VARCHAR,
sales_amount DECIMAL,
transaction_date DATE
) PARTITION BY (transaction_date);
Run the query below to insert data into the table you just created.
INSERT INTO SalesData (id, product_name, sales_amount, transaction_date)
VALUES
(1, 'ProductA', 1500.00, '2023-10-15'),
(2, 'ProductB', 2000.00, '2023-10-15'),
(3, 'ProductA', 1200.00, '2023-10-16'),
(4, 'ProductC', 1800.00, '2023-10-16'),
(5, 'ProductB', 2200.00, '2023-10-17');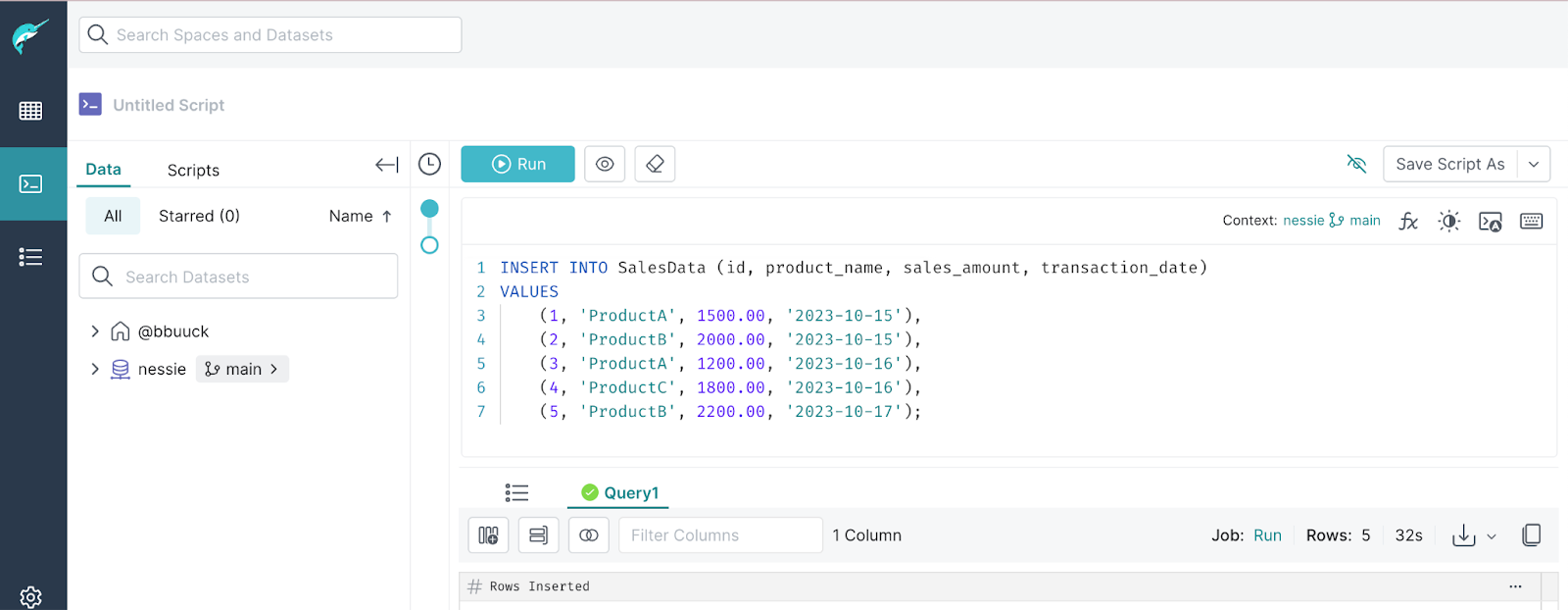
Navigate back to MinIO to see that your data lake has been populated with the Iceberg tables.
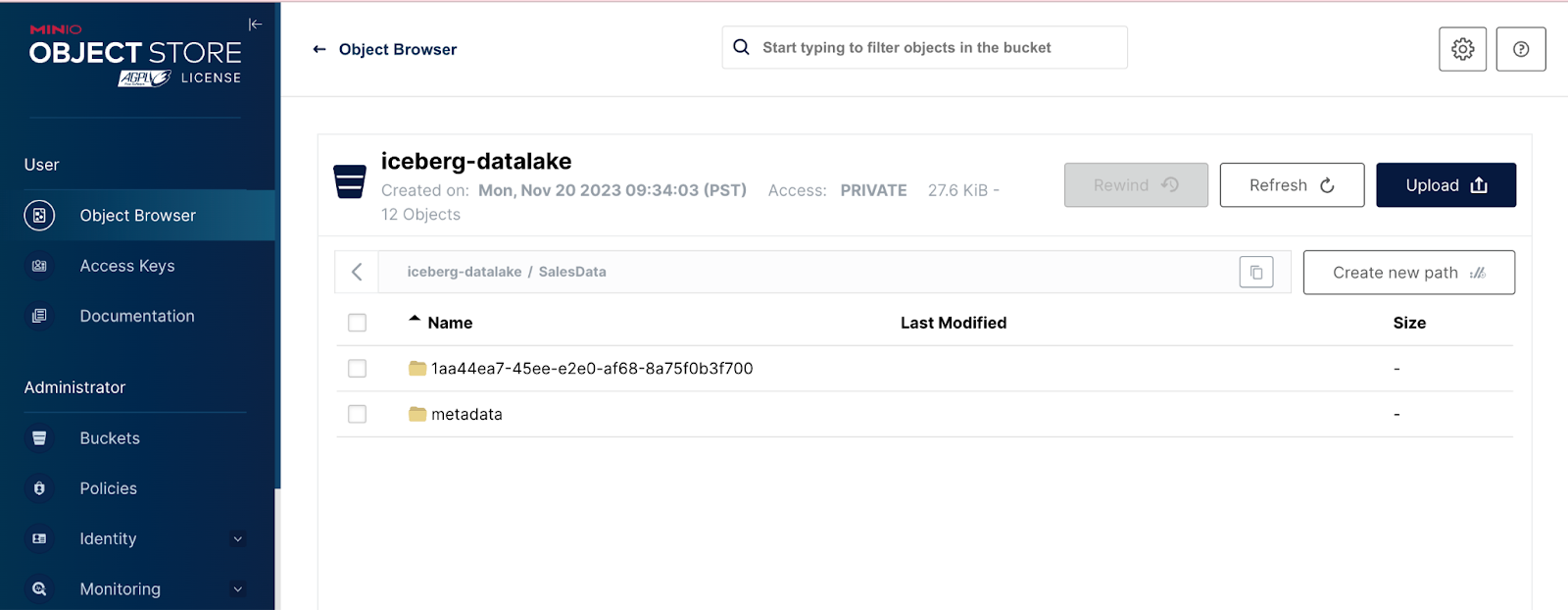
Branching and Merging with Nessie
Return to Dremio at http://localhost:9047. Begin by querying a table on the main branch using the AT BRANCH syntax:
SELECT * FROM nessie.SalesData AT BRANCH main;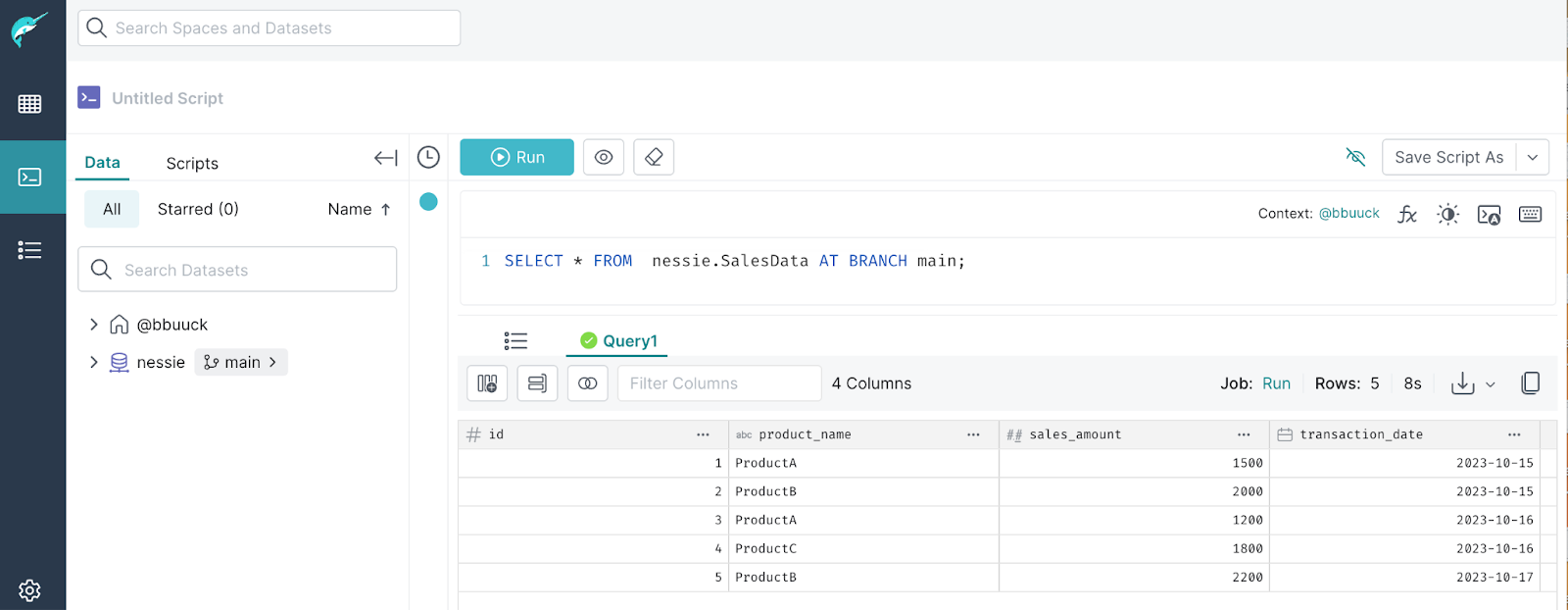
Create an ETL (Extract Transform and Load) branch to allow you to play around with and transform data without impacting production.
CREATE BRANCH etl_06092023 in nessieWithin the ETL branch, insert new data into the table:
USE BRANCH etl_06092023 in nessie;
INSERT INTO nessie.SalesData (id, product_name, sales_amount, transaction_date) VALUES
(6, 'ProductC', 1400.00, '2023-10-18');Confirm the immediate availability of the new data within the ETL branch:
SELECT * FROM nessie.SalesData AT BRANCH etl_06092023;Note the isolation of changes from users on the main branch:
SELECT * FROM nessie.SalesData AT BRANCH main;Merge the changes from the ETL branch back into the main branch:
MERGE BRANCH etl_06092023 INTO main in nessie;Select the main branch again to see that the changes have indeed been merged.
SELECT * FROM nessie.SalesData AT BRANCH mainThis branching strategy enables data engineers to independently handle numerous transactions across multiple tables. When they are ready, data engineers can merge these transactions into a single, comprehensive multi-table transaction within the main branch.
Conclusion
This blog post delved into the power of Git-like version control in data engineering, emphasizing how Nessie seamlessly manages data versions, branches and merges. This step-by-step guide demonstrates how Nessie, in collaboration with Dremio and MinIO, as the object storage foundation, enhances data quality and collaboration in data engineering workflows.
Let us know what your data lakehouse looks like at hello@minio.io or on our Slack channel.






