The Real Reasons Why AI is Built on Object Storage
tl;dr:
In this post, we will explore four technical reasons why AI workloads rely on high performance object store.
1. No Limits on Unstructured Data
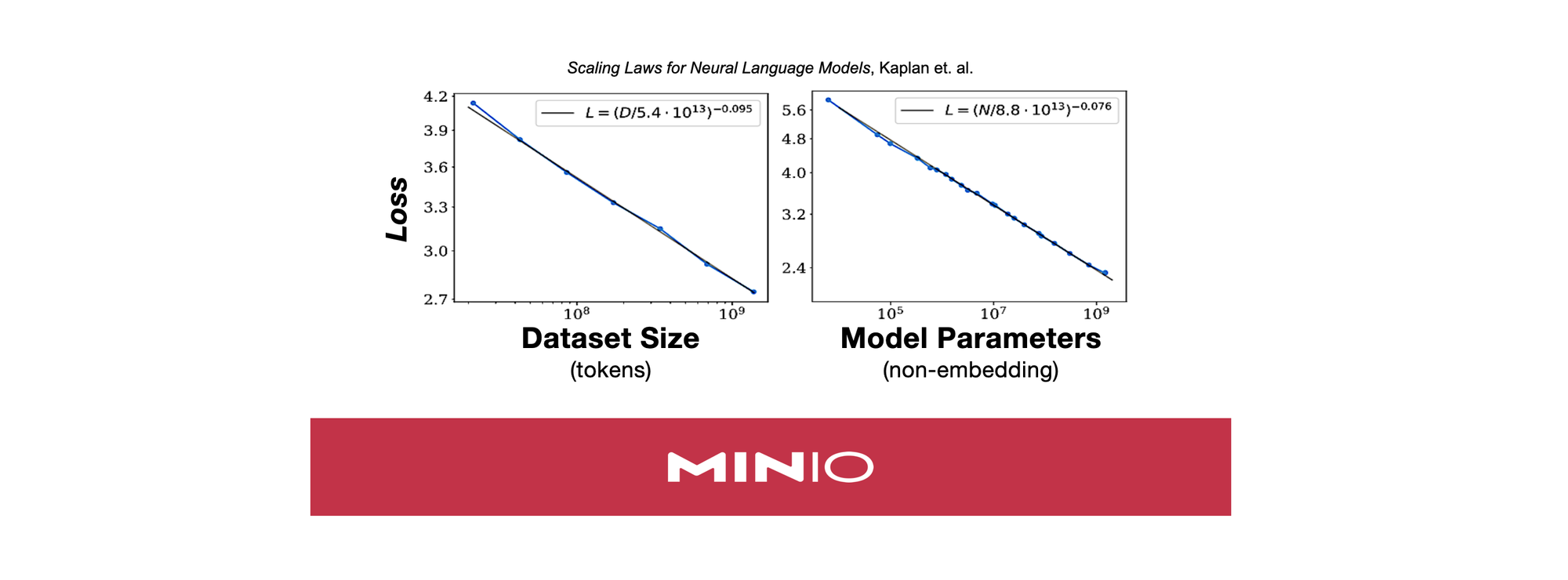
In the current paradigm of machine learning, performance and ability scales with compute, which is really a proxy for dataset size and model size (Scaling Laws for Neural Language Models, Kaplan et. al.). Over the past few years, this has brought on sweeping changes to how machine learning and data infrastructure is built – namely: the separation of storage and compute, the construction of massive cloud-native data lakes filled with unstructured data, and specialized hardware that can do matrix multiplication really fast.
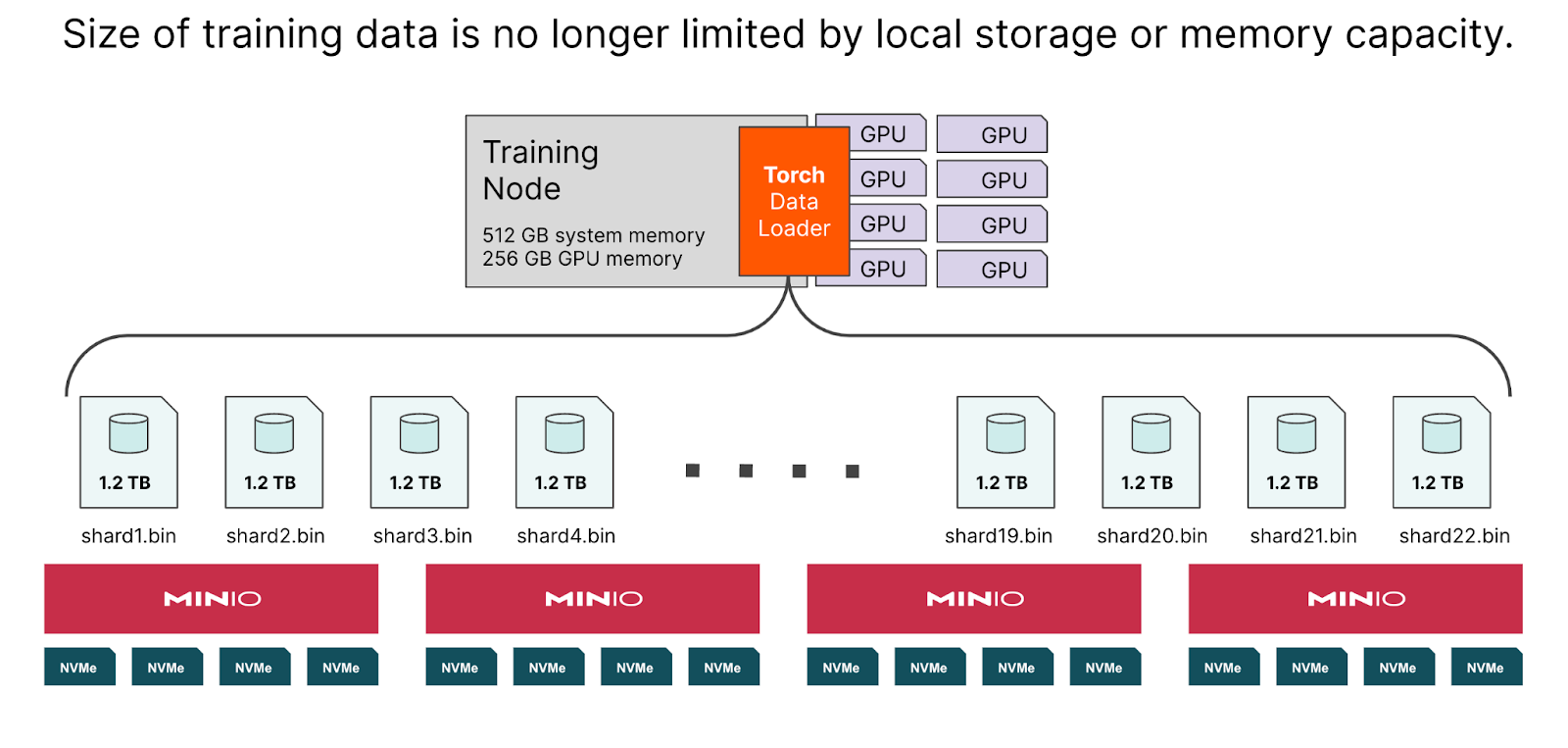
When a training dataset, or even an individual shard of a dataset, requires more space than is available in system memory and/or local storage, the importance of decoupling storage from compute becomes glaringly evident. When training on data that resides on the MinIO Object Store, there are no limits to your training data size. Due to MinIO’s focus on simplicity and I/O throughput, it is the network that becomes the sole limiting factor for training speed and GPU utilization.
In addition to affording the best performance of any object store, MinIO is compatible with all the modern machine learning frameworks. The MinIO Object Store is also 100% S3 API-compatible, so you can perform ML workloads against your on-premise or on-device object store using familiar dataset utilities like the TorchData S3 Datapipe. In the event where file-system-like capabilities are required by your consuming application, you can even use MinIO with object store file interfaces like Mountpoint S3 or S3FS. In a future blog post, we will use the MinIO Python SDK in custom implementations of some common PyTorch and FairSeq interfaces (like Dataset and Task, respectively) in order to enable ‘no limits’ training data and high GPU utilization for model training.
Beyond performance and compatibility with the modern ML stack, the design choices of object storage, namely (1) a flat namespace, (2) the encapsulation of the whole object (and its metadata) as the lowest logical entity, and (3) simple HTTP verbs APIs, are what have led to object storage becoming the de facto standard for massive unstructured data lakes. A look at the recent history of machine learning shows that training data (and in a sense, model architectures themselves) has become less structured and more general. It used to be the case that models were predominantly trained on tabular data. Nowadays, there is a much broader range, from paragraphs of plain text to hours of video. As model architectures and ML applications evolve, object store’s stateless, schema-less, and consequently, scalable nature only becomes more critical.
2. Rich Metadata for Models and Datasets
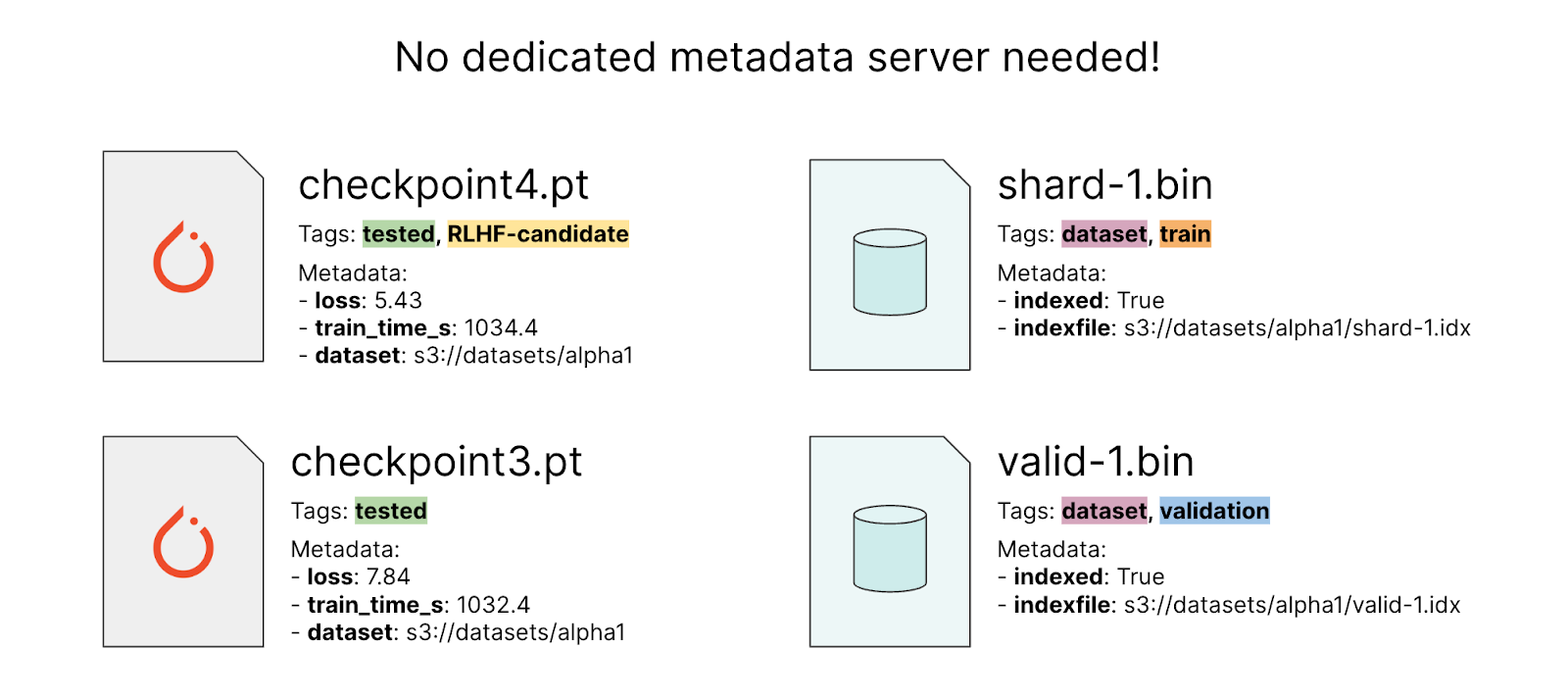
Due to the design choices of the MinIO Object Store, every object can contain rich, schema-less metadata without sacrificing performance or requiring the use of a dedicated metadata server. Imagination is really the only limit when it comes to what kind of metadata you want to add to your objects. However, here are some ideas that could be particularly useful for ML-related objects:
For model checkpoints: loss function value, time taken for training, dataset used for training.
For datasets: name of paired index files (if applicable), dataset category (train, validation, test), information about the dataset’s format.
Highly descriptive metadata like this can be particularly powerful when paired with the ability to efficiently index and query this metadata, even across billions of objects, something that MinIO Catalog affords. For example, you could query for model checkpoints that are tagged as “tested” or checkpoints that have been trained on a particular dataset.
3. Models and Datasets are Available, Auditable, & Versionable

As machine learning models and their datasets become increasingly critical assets, it has become just as important to store and manage these assets in a way that is fault-tolerant, auditable, and versionable.
Datasets and the models that train on them are valuable assets that are the hard-earned products of time, engineering effort, and money. Accordingly, they should be protected in a way that doesn’t encumber access by applications. MinIO’s inline operations like bitrot checking and erasure coding, along with features like multi-site, active-active replication ensure resilience of these objects at scale.
With generative AI in particular, knowing which version of which dataset was used to train a particular model that is being served is helpful when debugging hallucinations and other model misbehavior. If model checkpoints are properly versioned, it becomes easier to trust a quick rollback to a previously served version of the checkpoint. With the MinIO Object Store, you get these benefits for your objects right out of the box.
4. Owned Serving Infrastructure

The MinIO Object Store is, fundamentally, an object store that you, or your organization, controls. Whether the use-case is for prototyping, security, regulatory, or economic purposes, control is the common thread. Accordingly, if trained model checkpoints reside on the object store, it affords you greater control over the task of serving models for inference, or consumption.
In a previous post, we explored the benefits of storing model files on object store and how to serve them directly with the TorchServe inference framework from PyTorch. However, this is an entirely model and framework-agnostic strategy.
But why does this matter? Network lag or outages on third-party model repositories could make models slow to get served for inference, or entirely unavailable. Furthermore, in a production environment where inference servers are scaling and need to pull model checkpoints routinely, this problem can be exacerbated. In the most secure and/or critical of circumstances, it’s best to avoid third-party dependency over the internet where you can. With MinIO as a private or hybrid cloud object store, it is possible to avoid these problems entirely.
Closing Thoughts

These four reasons are by no means an exhaustive list. Developers and organizations use MinIO Object Storage for their AI workloads for a whole variety of reasons, ranging from ease of development to its super light footprint.
In the beginning of this post, we covered the driving forces behind the adoption of high performance object store for AI. Whether or not the scaling laws hold, what’s certainly going to be true is that organizations and their AI workloads will always benefit from the best I/O throughput capability available. In addition to that, we can be fairly confident that developers will never ask for APIs that are harder to use and software that does not ‘just work.’ In any future where these assumptions hold, high performance object store is the way.
For any architects and engineering decision makers reading this, many of the best practices mentioned here can be automated to ensure object storage is leveraged in a way that makes your AI/ML workflows simpler and more scalable. This can be done through the use of any of the modern MLOps tool sets. AI/ML SME Keith Pijanowski has explored many of these tools - search our blog site for Kubeflow, MLflow, and MLRun for more information on MLOps tooling. However, if these MLOps tools are not an option for your organization and you need to get going quickly, then the techniques shown in this post are the best way to get started managing your AI/ML workflows with MinIO.
For developers (or anybody who’s curious 🙂), in a future blog post, we will do an end-to-end walkthrough of adapting a ML framework to leverage object store with the goal of ‘no limits’ training data and proper GPU utilization.
Thanks for reading, I hope it was informative! As always, if you have any questions join our Slack Channel or drop us a note at hello@min.io.






