How to Backup and Restore 100PB of Data with Zero RPO and RTO

There is an interesting dynamic emerging in the world of backup and restore. As data grows - it effectively outstrips the ability of even the most sophisticated backup vendor to deliver an acceptable Recovery Time Objective (RTO) and Recovery Point Objective (RPO).
Where that problem begins to emerge depends on a number of different factors - but it starts to get funky around 10PB. At that point traversing the data for a backup becomes infeasible and restore times are beyond what is reasonable to return a system to a running state. You are forced to deal in smaller increments.
Still - you have to protect your data, it is after all the heartbeat of the modern enterprise. So what is the strategy?
The strategy is a combination of versioning and replication on your object store. Implemented correctly it takes your RPO and RTO times to zero.
That’s right zero for RTO. Zero for RPO.
More importantly - it doesn’t matter if it is 1PB, 10PB or 100PB. It is still zero.
Here is how it works. We will start with continuous data protection through versioning and then replicate that data across regions/data centers/zones such that if anything goes down it fails over to the second site (or third, fourth in the case of multi-site).
Immutability and Versioning
Immutability is a core principle in object storage - once written, objects cannot be changed. With MinIO, all operations on an object are atomic, and when versioning is enabled, no object can be lost.
A typical workflow involves a user or application GET-ting the object from a MinIO server, modifying it locally, and then uploading the new version back to the server. The original object becomes part of the system of record as it cannot be modified, and as each new version is saved it’s possible to roll back changes to work with previous versions. This leaves the newer version intact as well, as even newer versions are added.
MinIO refers to this as continuous data protection.
MinIO follows Amazon’s S3 structure/implementation for API consistency. When each new version of an object is written, it is assigned a unique version ID. Applications can specify a version ID to access a specific version of that object at a specific time. MinIO retains multiple variants of an object in the same bucket and provides a mechanism to preserve, retrieve and simultaneously restore every version of every object stored in a bucket.
MinIO versioning does not rely on volume-level snapshots. Snapshots simply don’t scale. When you make complete point-in-time copies of entire volumes, rolling back to a previous version of an object requires reading in an entire volume’s snapshot just to get to a specific object. Some storage vendors “chain” snapshots together so they have to be restored sequentially. This process is akin to searching through multiple versions of an entire library just to find a single article - it’s slow and painful.
MinIO protects against accidental deletion by using a delete marker. When a versioned object is deleted it is not removed from the system. Instead, a delete marker is created and becomes the current version of the object. When that object is requested, MinIO returns a 404 Not Found message. Removing the delete marker undeletes the object. Similarly, if a new version of the object is written, both the old and new versions of the object exist, each with its own unique identifier. Old versions of individual objects can be exposed quickly and easily as required simply by removing their delete flags.
When versioning is enabled, MinIO tracks every single operation and never overwrites any object. You can use the MinIO Console, MinIO Client (mc), SDK or the command line to apply versioning and work with different versions of objects.
Protecting Live Data Against Bitrot
Having bitrot in the live data is a problem - and even worse you can back up bitrotted data - and then your backup is useless as well. MinIO ensures that bitrot does not occur in live data. This means that in case of bitrot happening on primary storage, the corrupted data will not be "backed up", preventing a situation that would have made recovery impossible.
MinIO can detect and correct bitrot on the fly with its sophisticated erasure coding. Therefore there is no risk of ever receiving bitrotted data and all replicas will always be clean.
MC Rewind - No Object Left Behind
MinIO includes a rewind feature that enables you to list, examine, retrieve or roll back objects as they were previously. It recovers every single change, across the entire namespace, at any point in time without restoring it.
MC Rewind is a higher level function that can be applied to most of the MC command set to work with different versions of an object. The --rewind option is available for list, tree, du, cat, head, cp, rm, tag and stat so you can work with buckets and objects at different points in time without overwriting anything.
The --rewind flag can be invoked in a number of different ways so you can find the previous versions of an object that you’re looking for. The --rewind flag can be followed by a time interval (for example 3d) or a specific time (for example 2020.03.24T10:00) to work with the version of an object that was active at that time.
If you really want to be sure that no version is removed or tampered with, then you can create the bucket with object locking enabled with ./mc mb -l or add it later using ./mc retention.
Retention and locking are important concepts if you’re ever faced with an audit after an attack. Let’s say that one day you notice unauthorized access to your bucket. With object locking enabled, no version of an object is ever deleted. They’re immutable and read-only so they can’t be damaged or deleted in an attack. Once you know the auditor’s legal requirements, you can use the retention command to set governance on a bucket so it cannot be modified until the audit has completed.
Alternatively, if you want to save storage space, you can purge object versions based on date and time. For example, the command ./mc rm play/iceberg/ --recursive --versions --rewind 365d will remove all versions of all objects older than 365 days.
Active Active Replication
Synchronizing data between multiple data centers should be a core competency of any object store. They should be able to support:
- Same-DC Replication
- Cross-DC Replication
- Same-Region Replication
- Cross-Region Replication
Active-Active Replication enables organizations to protect their data - particularly at scale. It is the cornerstone for multi-primary storage topologies, fast hot-hot failover, and multi-geographic resiliency.
MinIO not only supports the scenarios above, it also supports multi-site, active-active replication for synchronization of objects between an arbitrary number of MinIO deployments. Think of multi-site replication like a mesh network - each bucket synchronized across multiple mesh nodes. This further improves the flexibility of MinIO replication for organizations with more complex requirements around multi-DC or multi-region synchronization. There is a full post here so we will not delve into the technical details - but we will say that we are not aware of anyone else with this capability.
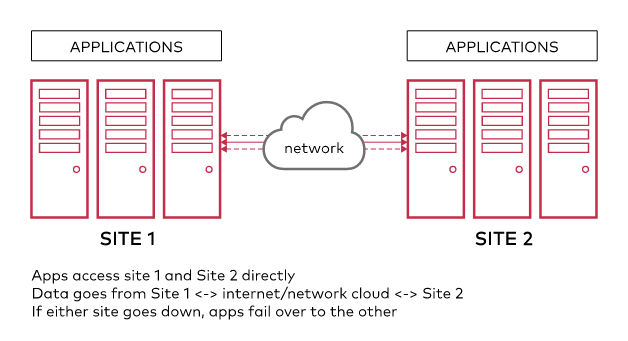
MinIO can replicate:
- Buckets and bucket metadata, such as policies (access, lifecycle…)
- Objects and their metadata (which is written atomically with the object in MinIO). Those objects can either be encrypted or unencrypted. This is subject to the constraints outlined above regarding older objects. The owner will need the appropriate permissions.
- Object versions.
- Object tags, if there are any.
- S3 Object Lock retention information, if there is any. It should be noted that the retention information of the source will override anything on the replication side. If no retention information is in place, the object will take on the retention period on the destination bucket. For more information on object locking, look at this blog post or the documentation.
- Identity and access management policies and tokens
MinIO offers three ways of replicating data.
The first is site to site, the second is bucket to bucket and the third is bucket to others (other S3 compatible object stores and/or POSIX file systems).
Multi-site replication is a site-level setting that needs to be configured only once. It supports existing and future buckets. All the linked sites are always kept in sync automatically and the applications are free to load balance across MinIO deployments.
Bucket replication is explicitly configured at the bucket level, giving the flexibility to create advanced replication topologies. Each bucket can replicate to one or more remote buckets. Remote buckets may be of the same name or different names, unidirectional or bidirectional. Each bucket can choose a different set of targets in different sites. Bucket replication may be used as simply as a single bucket getting replicated as opposed to an entire site.
Both site and bucket replication features are server-side replication. This means once enabled, the servers keep track of the changes and push them to remote targets efficiently using the server side resources. Even reboots and restarts are immaterial.
Bucket-to-other replication is achieved by client-side replication using a rsync-like utility called ‘mc mirror’. Client side replication has to download the object(s) to a single client node where the tool is running and then re-upload them to the destination site. In case of reboots you have to relaunch the utility to continue the synchronization process. We only recommend this process to replicate objects to a third party object store or legacy (POSIX) file system.
Source and destination buckets can have the same name. This is particularly important for the applications to transparently failover to the remote site without any disruption. The load balancer or the DNS simply directs the application traffic to the new site. If the remote bucket is in a different name, it is not possible to establish transparent failover capability.
In all three cases, there are some considerations. While heterogeneous hardware is supported, both sides need similar capacity and performance characteristics (disaster recovery will be an obvious exception).
The next consideration is bandwidth and is the most important factor by far. First, spend the time to calculate the appropriate bandwidth required based on change rates and burstiness. To keep multiple sites synchronized you need to have your replication bandwidth match the rate at which your data arrives. If this is not done, the changes will be queued and eventually synchronized. MinIO also supports synchronous replication but will only be able to operate at the speed of the replication link.
Your investment in higher bandwidth is more important than the investment in lower latency as it will have superior returns on your investment. MinIO can tolerate long distance (100+ millisecond latency) because of its architecture. This is a huge plus for geo-replication.
As noted in the versioning section, MinIO also supports automatic object locking/retention replication across the source and destination buckets natively out of the box.
MinIO does not require configurations/permission for AccessControlTranslation, Metrics and SourceSelectionCriteria - significantly simplifying the operation and reducing the opportunity for error.
MinIO uses near-synchronous replication to update objects immediately after any mutation on the bucket. MinIO follows strict consistency within the data center and eventual-consistency across data centers to protect the data.
But What About Snapshots?
Snapshots are the core component of the traditional backup strategy. This proved to be highly effective, provided of course that your snapshots were small in nature. Snapshots made at the SAN or NAS level were read only, so the backup systems could take their time as nothing was changing. Even with many volumes, since each volume was small, this was manageable. When databases went scale out - things began to change. A scale out database writes to multiple drives. How do you atomically snapshot all the drives atomically? You can’t.
This has led to the database vendors developing direct online backup for themselves. We are working with one such enterprise and their database, MariaDB. MariaDB has its own backup capability. Working with the customer and MariaDB we were able to increase the performance by 10x. It now backs up directly to MinIO and in turn is replicated for business continuity.
But What About Mistakes?
The only thing worse than a mistake is propagating that mistake. It happens. It is inevitable. Someone will delete data. Someone will overwrite data. MinIO will have a bug. These are reasonable things to plan for - and you can.
Some customers upgrade independently, leaving one side untouched until they are comfortable with the changes. Others just have two sites and one of them is the DR site with one way propagation.
Resiliency is a choice and a tradeoff between budget and SLAs. Customers have a range of choices that protect against accidents.
The Dirty Secret….
Every enterprise talks a big game around disaster recovery and business continuity. It is a C-suite priority, yet very few actually understand the “real world” RTO and RPO metrics. They don’t have the capacity to test at scale. So they protect what they can test. Needless to say - this doesn’t go well in an actual disaster, malware or ransomware attack.
With site replication, disaster recovery testing is not only straightforward, it can be done in a live environment without major impact. Disaster recovery testing can be done with a DNS redirect and taking the primary servers offline. This will allow the enterprise to accurately test whether a switchover can happen seamlessly.
We see the lack of real testing first-hand in conjunction with our partners in the backup space. These businesses are prepared to protect data at scale because the existing solutions can’t protect data at scale. Nonetheless, it can be easy to wrap yourself in the comfort blanket of a well known brand. And we want to be clear - the leading backup vendors are absolutely excellent at protecting your data at scales under 10PB. They have great features and functionality and are priced right. Having said that, we work with businesses for whom it took months to return to normal after they were compromised - and they are only dealing with low single digit PBs.
At scale - protecting data is an end-to-end job for object storage. There is no other solution.
To learn more about how MinIO can help you to protect your data, reach out to us on hello@min.io and we can talk through what the right answer might be - from 1PB to 1,000.






