AIHub: A Private Cloud Repository for Models and Datasets

One of the newest features of the AIStor is a private cloud version of the highly popular, open-source project, Hugging Face. This post details how AIStor’s AIHub effectively creates an API compatible, private cloud version of Hugging Face that is fully under the enterprise's control.
Before we get started, it makes sense to introduce Hugging Face.
Hugging Face is the leading open platform for AI Engineers. With a mission to democratize machine learning, it has successfully created a cloud platform for sharing models and datasets. Many big technology companies leading the charge in model research and development - especially in the area of Large Language Models (LLMs) - have contributed to Hugging Face. This is a big deal as LLMs are costly to train in terms of time and money. When models as complex as LLMs are shared, organizations that do not have the resources to build LLMs from scratch can use AI to move forward in ways that would not be possible without the sharing provided by Hugging Face.
Furthermore, technology leaders interested in truly open AI will also open source the data used to train the models they are open-sourcing. Models are only as good as the data used to train them. Allowing the training data to be shared means it can be reviewed by the community for potential bias and other shortcomings. If an issue is discovered, new data can be found to correct the issue, and the new data can also be shared. Hugging Face also has an offering for sharing datasets.
Hugging Face’s efforts to further AI did not stop with model and data sharing. They also created libraries that are used to reduce the amount of code needed to manipulate models and data. You can think of these libraries as abstraction layers that encapsulate the complexity of models and data. These libraries have been heavily used by the community directly. Below is a list and short description of the more popular Hugging Libraries.
Transformers - Transformers provides APIs and tools to download and train state-of-the-art pre-trained models. Pre-trained models can reduce your compute costs and carbon footprint and save you the time and resources required to train a model from scratch.
Datasets - Datasets is a library for easily accessing and sharing datasets for tabular, audio, computer vision, and natural language processing (NLP) tasks.
Diffusers - The diffusers library is a Python library developed by Hugging Face for working with diffusion models, a type of generative model that can create high-quality images, audio, and other data.
Sentence Transformers - is the go-to Python module for accessing, using, and training state-of-the-art text and image embedding models. It can be used to compute embeddings using Sentence Transformer models or to calculate similarity scores using Cross-Encoder models.
An Ecosystem Built with Hugging Face Libraries
What is especially interesting is that other AI tools have taken a dependency on Hugging Face’s libraries and used them to deliver their capabilities. For example, many inference servers use Hugging Face as a hub to find and deploy models. Below is a short list of common inference servers, orchestration libraries, and fine-tuning libraries that use Hugging Face APIs.
vLLM - The vLLM inference server is a high-performance, specialized inference solution for large language models (LLMs). It optimizes memory usage and parallelization to achieve fast response times and high throughput. It is designed to support Transformer-based models, including Hugging Face models.
Nvidia Triton Inference Server - NVIDIA Triton Inference Server, part of the NVIDIA AI platform and available with NVIDIA AI Enterprise, is open-source software that standardizes AI model deployment and execution across every workload.
Ollama - Ollama is a lightweight, extensible framework for building and running language models on the local machine. It supports macOS, Linux, and Windows.
LangChain - LangChain is a framework for building applications that are powered by LLMs. It is designed to help developers orchestrate workflows that include tasks like data ingestion, data retrieval, prompt creation and inference.
The Privacy and Control Problem
In a perfect world, all models improved via fine-tuning would also be shared along with the data used to improve them. Unfortunately, this is not always the case. For some organizations, privacy and control take precedence over sharing. This is especially true of organizations operating in heavily regulated industries and organizations responsible for personally identifiable information (PII). Below is a typical workflow for organizations that want to use a public AIHub as a starting point but require privacy and control once datasets are augmented with sensitive information and the models have been fine-tune on this new data.
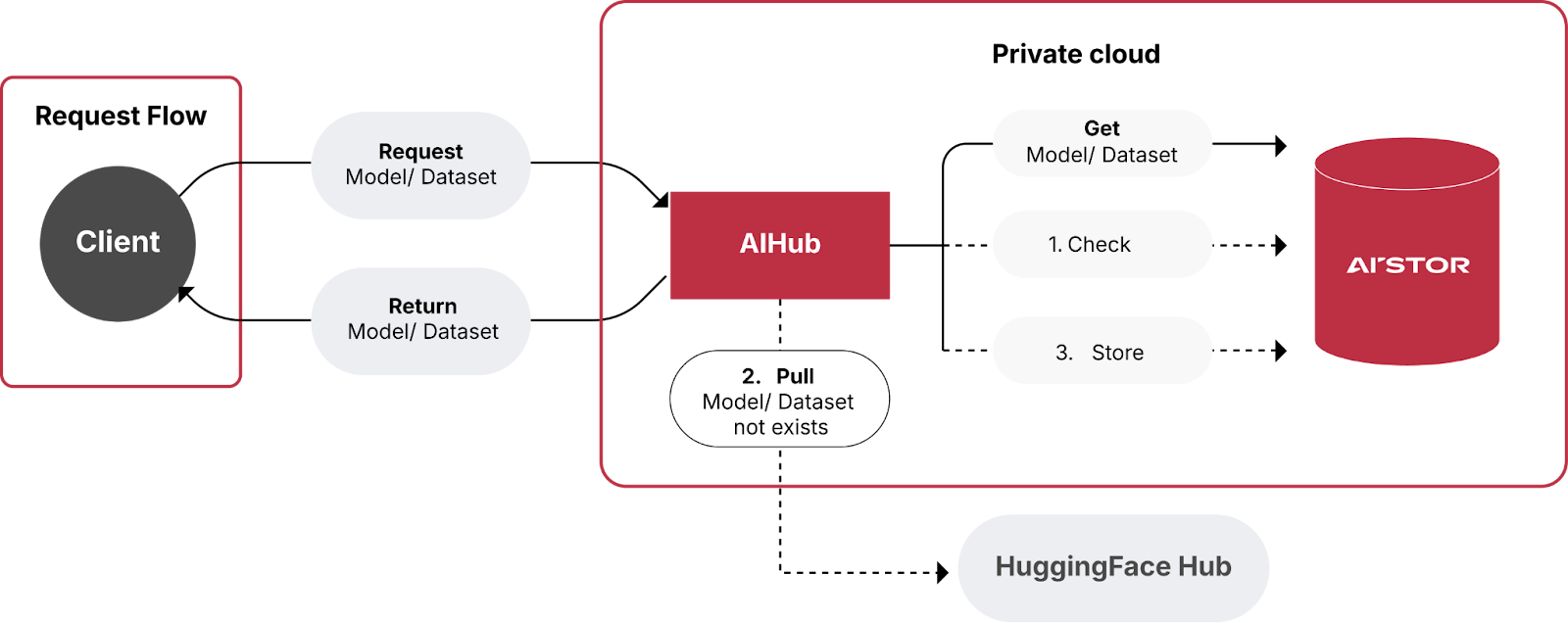
Many organizations that want to use Hugging Face models and datasets as a starting point for their AI initiatives may have implemented the logic above using brute force. This is often done using network shares as a pseudo hub. Unfortunately, using network shares as a hub is not a scalable or performant solution. Also, the Hugging Face APIs do not contain logic to look within a local hub for a version of a requested model (or dataset) before downloading. This requires a manual override to all download functions which is prone to error. The final concern with a brute force approach is that all the upload functions and methods within the Hugging Face APIs are, by default, configured to send models and datasets back to Hugging Face. It is easy to accidentally send private data or models that were trained on private data back to the public Hugging Face Hub.
What is needed is a simple way, using configuration, to loop in the logic shown above while allowing developers to use Hugging Face APIs - or any other library built on top of the Hugging Face APIs.
Introducing AIHub
AIHub targets the Hugging Face APIs and implements a proxy server that is fully compatible with these APIs. With zero code changes, application developers can use the existing Hugging Face libraries to download an existing model from Hugging Face and save it to a MinIO bucket. Subsequent requests for the same model will result in the Hugging Face libraries pulling the model from MinIO. If the model is augmented or fine-tuned, the new version will be pushed to MinIO and saved alongside the original version. Datasets work the same way. The bottom line, engineers can use AIHub to save models and data locally using familiar tools.
Let’s examine the relationship between a Python client, the Hugging Face Hub, and the AIHub, as depicted in the graphic below to get a better understanding how AIHub works. Note that AIHub comprises the AIHub Server and an AIStor Bucket, both shown in the graphic.
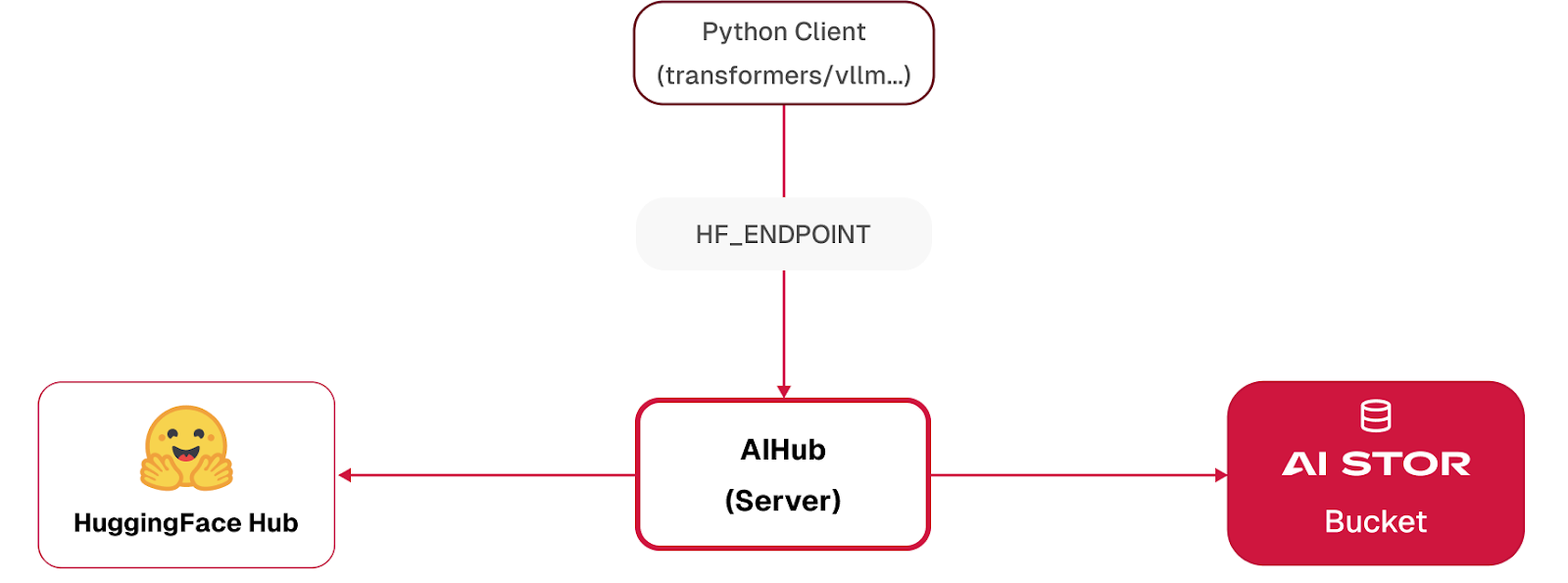
The AIHub server is a proxy server that intercepts all requests from Hugging Face APIs. It also contains the logic shown in the workflow shown in the previous section. That is, if a model or dataset already exists within the AIStor bucket, then that is the model that will be returned from the Hugging Face download APIs. If it does not exist in the AIStor bucket then it will be download from Hugging Face and automatically saved in the bucket. The AIStor bucket is a bucket within MinIO, which is a scalable and performant object-store. Finally, the AIHub server sends all save and push requests to the AIStor bucket. Models and datasets are never sent back to Hugging Face.
Setting Up and Using AIHub
Since the AIHub server needs to connect to a bucket within an instance of AIStor, its configuration requires all the necessary information to connect to AIStor and locate the desired bucket. Below is the AIStor UI showing the six environment variables needed for the AIHub server to connect to AIstor and locate the bucket that will act as a local hub.

Multiple AIHubs can be hosted within a single AIStor tenant. Admins can configure them using the AIStor Console user interface. AIHub instances can also be declaratively specified using YAML and then uploaded to an AIStor tenant via the AIStor Console.
ML engineers who want to use AIHub only need to set one environment variable at the start of their workflows. Below is a code snippet showing the environment variable that must be set. This is all that needs to be done to use AIHub. If ML engineers use Jupyter Notebooks, this variable should be set as part of the setup of the Jupyter Notebook environment.
Conclusion
Organizations in the early phases of AI can go to Hugging Face and find models to bootstrap their initiatives. Hugging Face makes it easy for organizations to build AI with open models and datasets. However, everything on Hugging Face is open and many organizations need to save models that they initially downloaded from Hugging Face to a local secure hub. They also need to fine-tune these models using data that is private and entirely under their control.
AIHub is a turnkey solution designed to address these challenges. Using AIHub, customers can securely store their models and datasets in an AIStor tenant fully under their control. This all happens while letting engineers start their ML pipelines with an initial version of a model or dataset from Hugging Face. Also, no new libraries are needed. The existing Hugging Face libraries and any other libraries that have taken a dependency on Hugging Face will work as is.






