AI ML Architecture: Modern Datalake Reference Guide

An abbreviated version of this post appeared on The New Stack on March 19th, 2024.
In enterprise artificial intelligence, there are two main types of models: discriminative and generative. Discriminative models are used to classify or predict data, while generative models are used to create new data. Even though Generative AI has dominated the news of late, organizations are still pursuing both types of AI. Discriminative AI still remains an important initiative for organizations that want to operate more efficiently and pursue additional revenue streams. These different types of AI have a lot in common, but at the same time, there are significant differences that must be taken into account when building your AI data infrastructure.
Organizations should not build an infrastructure dedicated to AI and AI only while leaving workloads like Business Intelligence, Data Analytics, and Data Science to fend for themselves. It is possible to build a complete data infrastructure that supports all the needs of the organization - Business Intelligence, Data Analytics, Data Science, discriminative AI and Generative AI.
In another post, we presented a reference architecture for a modern datalake capable of serving the needs of business intelligence, data analytics, data science, and AI/ML. Let’s review the Modern Datalake Reference Architecture and highlight the capabilities it has for supporting AI/ML workloads.
The Modern Datalake
Definition and First Principles
Let’s start by defining a Modern Datalake as that will serve as the foundation for our reference architecture. This architecture is not “re-cycled” rather it reflects engineering first principles that are broadly applicable. A Modern Datalake is one-half Data Warehouse and one-half Data Lake and uses object storage for everything. Using object storage for a Data Lake makes perfect sense as object storage is for unstructured data, which is what a Data Lake is meant to store. However, using object storage for a Data Warehouse may sound odd - but a Data Warehouse built this way represents the next generation of Data Warehouses. This is made possible by the Open Table Format Specifications (OTFs) authored by Netflix, Uber, and Databricks, which make it seamless to employ object storage within a data warehouse.
Open Table Formats (Iceberg, Hudi, Delta Lake)
The OTFs are Apache Iceberg, Apache Hudi, and Delta Lake. They were authored by Netflix, Uber, and Databricks, respectively - because there were no products on the market that could handle their data needs. Essentially, what they all do (in different ways) is define a Data Warehouse that can be built on top of object storage (MinIO). Object storage provides the combination of scalable capacity and high performance that other storage solutions cannot. Since these are modern specifications, they have advanced features that old-fashioned data warehouses do not have - such as partition evolution, schema evolution, and zero-copy branching. Finally, since the Data Warehouse is built with object storage, you can use this same object store for unstructured data like images, video files, audio files, and documents. Unstructured data is usually stored in what the industry calls a data lake. Using an object store as the foundation for both your data lake and your data warehouse results in a solution capable of holding all your data. Structured storage resides in the OTF-based Data Warehouse and unstructured storage lives in the Data Lake. The same instance of MinIO could be used for both.
Why Object Storage Unifies Lake and Warehouse
At MinIO, we call this combination of an OTF-based Data Warehouse and a Data Lake the Modern Datalake, and we see it as the foundation for all your AI/ML workloads. It's where data is collected, stored, processed, and transformed. Training models using discriminative AI (supervised, unsupervised, and reinforcement learning) often requires a storage solution that can handle structured data that can live in the Data Warehouse. On the other hand, if you are training Large Language Models (LLMs), you must manage unstructured data or documents in their raw and processed form in the Data Lake.
Reference Architecture and Highlighted Layers
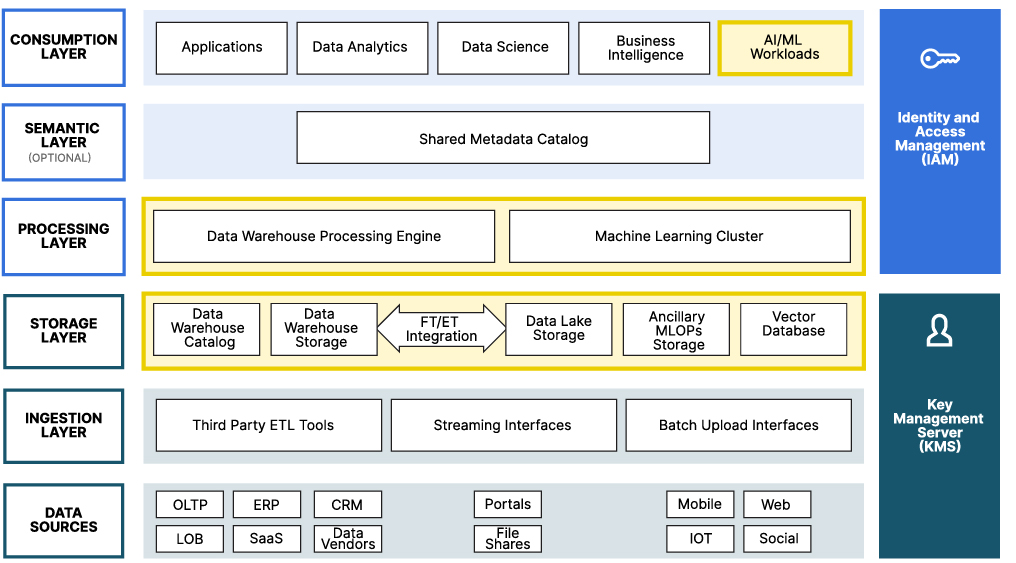
Source: Modern Datalake Reference Architecture
This post focuses on those areas of the Modern Datalake Reference Architecture for AI/ML that support the different AI/ML workloads. These functional areas are listed below. A visual depiction of the Modern Datalake is shown above. The layers in which these functional areas can be found have been highlighted.
AI/ML Functional Areas Covered
- Discriminative AI
- Storage for Unstructured Data
- Storage for Semi-structured Data
- Zero Copy Branching in the Data Warehouse
- Generative AI
- Building a Custom Corpus with a Vector Database
- Building a Document Pipeline
- Retrieval Augmented Generation (RAG)
- Fine-tuning Large Language Models
- Measuring LLM Accuracy
- Machine Learning Operations
This post also looks at the current state of GPUs and how they impact your AI data infrastructure. We will also look at a couple of scenarios that illustrate how to build your infrastructure and how not to build your infrastructure. Finally, this post presents a few recommendations for building an AI Data Infrastructure of your own.
Additional Topics in This Guide
- The Current State of GPUs
- The Hungry GPU Problem
- Supercharging Object Storage
- A Tale of Two Organizations
- A Plan for Building Your AI Data Infrastructure
Discriminative AI
Discriminative AI models require data of all types for training. Models for image classification and speech recognition will use unstructured data in the form of images and audio files. On the other hand, models for fraud detection and medical diagnosis make predictions based on structured data. Let’s look at options available within the Modern Datalake for storing and manipulating the data needed by discriminative AI.
Storage for Unstructured Data
Unstructured data will reside in the Data Lake, where it can be used for training and testing models. Training sets that can fit into memory can be loaded prior to training (before your epoch loop starts). However, if your training set is large and will not fit into memory, you will have to load a list of objects before training and retrieve the actual objects while processing each batch in your epoch loop. This could put a strain on your Data Lake if you do not build your Data Lake using a high-speed network and high-speed disk drives. If you are training models with data that cannot fit into memory, then consider building your Data Lake with a 100 GB network and NVMe drives.
Storage for Semi-structured Data
There are a few options available within the Modern Datalake for storing semi-structured files like Parquet files, AVRO files, JSON files, and even CSV files. The easiest thing to do is store them in your Data Lake and load them the same way you load unstructured objects. If the data in these semi-structured files is not needed by other workloads that the Modern Datalake supports (Business Intelligence, Data Analytics, and Data Science), then this is the best option.
Another option is to load these files into your Data Warehouse, where other workloads can use them. When data is loaded into your Data Warehouse, you can use Zero Copy Branching to perform experiments with your data.
Zero Copy Branching in the Data Warehouse
Feature engineering is a technique for improving datasets used to train a model. A very slick feature that OTF-based Data Warehouses possess is Zero-copy branching. This allows data to be branched the same way code can be branched within a Git repository. As the name suggests, this feature does not make a copy of the data - rather, it makes use of the metadata layer of the open table format used to implement the Data Warehouse to create the appearance of a unique copy of the data. Data scientists can experiment with a branch - if their experiments are successful, then they can merge their branch back into the main branch for other data scientists to use. If the experiment is not successful, then the branch can be deleted.
Generative AI
All models, whether they are small models built with Scikit-Learn, custom neural networks built with PyTorch or TensorFlow, or Large Language Models based on the Transformer architecture, require numbers as inputs and produce numbers as outputs. This simple fact places a few additional requirements on your AI/ML infrastructure if you are interested in Generative AI, where words have to be turned into numbers (or vectors, as we shall see). A generative AI solution gets even more complicated if you want to use private documents that contain your company's proprietary knowledge to enhance the answers produced by the LLMs. This enhancement could be in the form of Retrieval Augmented Generation or LLM Fine-tuning.
This section will discuss all these techniques (turning words into numbers, RAG, and Fine-tuning) and their impact on AI infrastructure. Let’s start by discussing how to build a Custom Corpus and where it should reside.
Creating a Custom Corpus with a Vector Database
If you are serious about Generative AI, then your custom corpus should define your organization. It should contain documents with knowledge that no one else has and only contain true and accurate information. Furthermore, your custom corpus should be built with a Vector Database. A vector database indexes, stores, and provides access to your documents alongside their vector embeddings, which are the numerical representations of your documents. (This solves the number problem described above.)
Vector Databases facilitate semantic search. How this is done requires a lot of mathematical background and is complicated. However, semantic search is conceptually easy to understand. Let’s say you want to find all documents that discuss anything related to “artificial intelligence”. To do this on a conventional database, you would need to search for every possible abbreviation, synonym, and related term of “artificial intelligence.” Your query would look something like this:
Not only is the manual similarity search arduous and prone to error but the search itself is very slow. A vector database can take a request like below and run the query faster and with greater accuracy. The ability to run semantic queries quickly and accurately is important if you wish to use Retrieval Augmented Generation.
Another important consideration for your custom corpus is security. Access to documents should honor access restrictions on the original documents. (It would be unfortunate if an intern could gain access to the CFO's financial results that have not been released to Wall Street yet.) Within your vector database, you should set up authorization to match the access levels of the original content. This can be done by integrating your Vector database with your organization's Identity and Access Management solution.
At their core, vector databases store unstructured data. Therefore, they should use your Data Lake as their storage solution.
Building a Document Pipeline
Unfortunately, most organizations do not have a single repository with clean and accurate documents. Rather, documents are spread across the organization in various team portals in many formats. Consequently, the first step in building a custom corpus is to build a pipeline that takes only documents that have been approved for use with Generative AI and place them in your vector database. For large global organizations, this could potentially be the hardest task of a Generative AI solution. It is common for teams to have documentation in draft format in their portals. There may also be documents that are random musings about what could be. These documents should not become a part of a custom corpus as they do not accurately represent the business. Unfortunately, filtering these documents will be a manual effort.
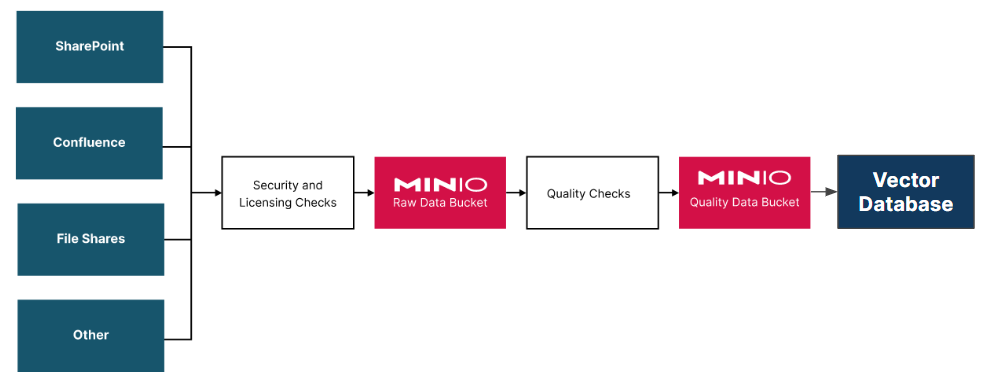
A document pipeline should also convert the documents to text. Fortunately, a few open-source libraries can do this for many of the common document formats. Additionally, a document pipeline must break documents into small segments before saving them in the vector database. This is due to limitations on prompt size when these documents are used for Retrieval Augmented Generation, which will be discussed in a later section.
Fine-tuning Large Language Models
When we fine-tune a large language model, we train it a little more with information in the custom corpus. This could be a good way to get a domain-specific LLM. While this option does require compute to perform the fine-tuning against your custom corpus, it is not as intensive as training a model from scratch and can be completed in a modest time frame.
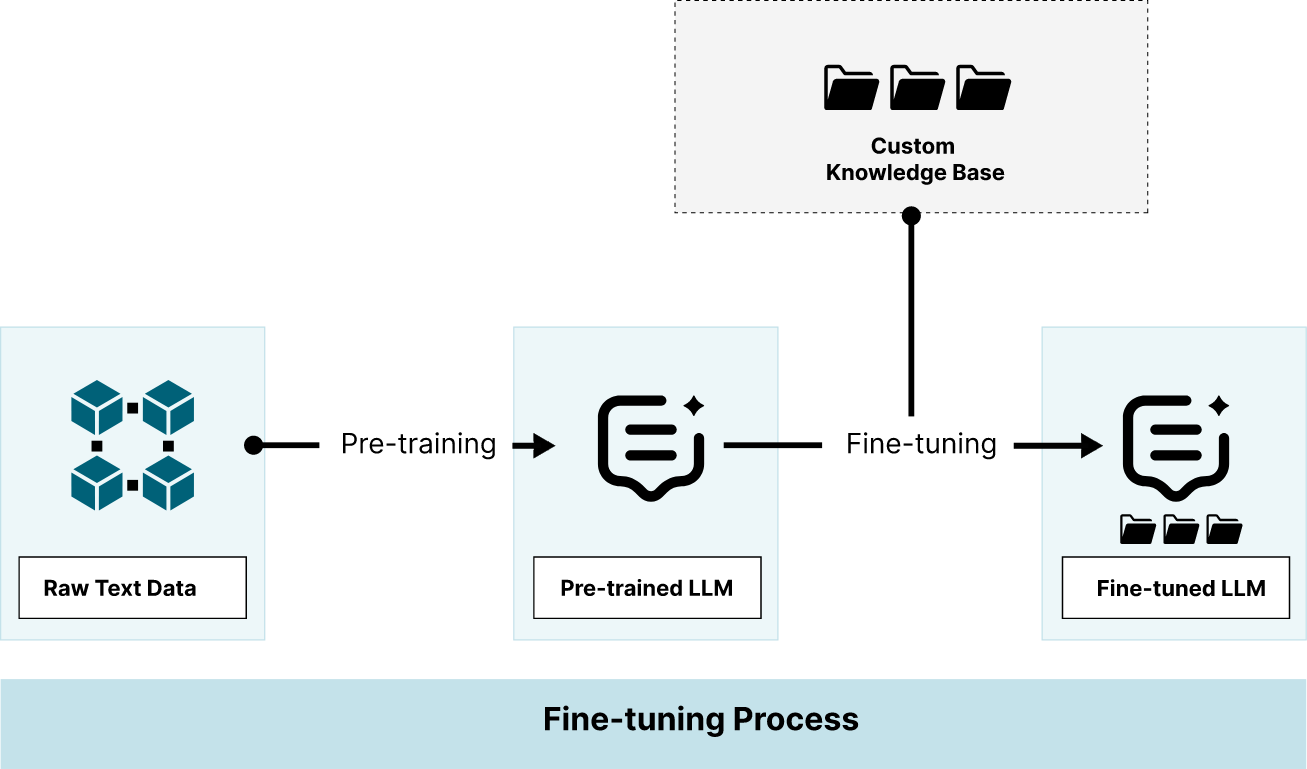
If your domain includes terms not found in everyday usage, fine-tuning may improve the quality of the LLM’s responses. For example, projects that use documents from medical research, environmental research, and anything related to the natural sciences may benefit from fine-tuning. Fine-tuning takes the highly specific vernacular found in your documents and bakes them into the parametric parameters of the model. The advantages and disadvantages of fine-tuning should be understood before deciding on this approach.
Disadvantages
- Fine-tuning will require compute resources.
- Explainability is not possible.
- You will periodically need to re-fine-tune with new data as your corpus evolves.
- Hallucinations are a concern.
- Document-level security is impossible.
Advantages
- The LLM has knowledge from your custom corpus via fine-tuning.
- The inference flow is less complicated than RAG.
While fine-tuning is a good way to teach an LLM about the language of your business, it dilutes the data since most LLMs contain billions of parameters, and your data will be spread across all these parameters. The biggest disadvantage of fine-tuning is that document-level authorization is impossible. Once a document is used for Fine-tuning, its information becomes a part of the model. It is not possible to restrict this information based on the user’s authorization levels.
Let’s look at a technique that combines your custom data and parametric data at inference time.
Retrieval Augmented Generation (RAG)
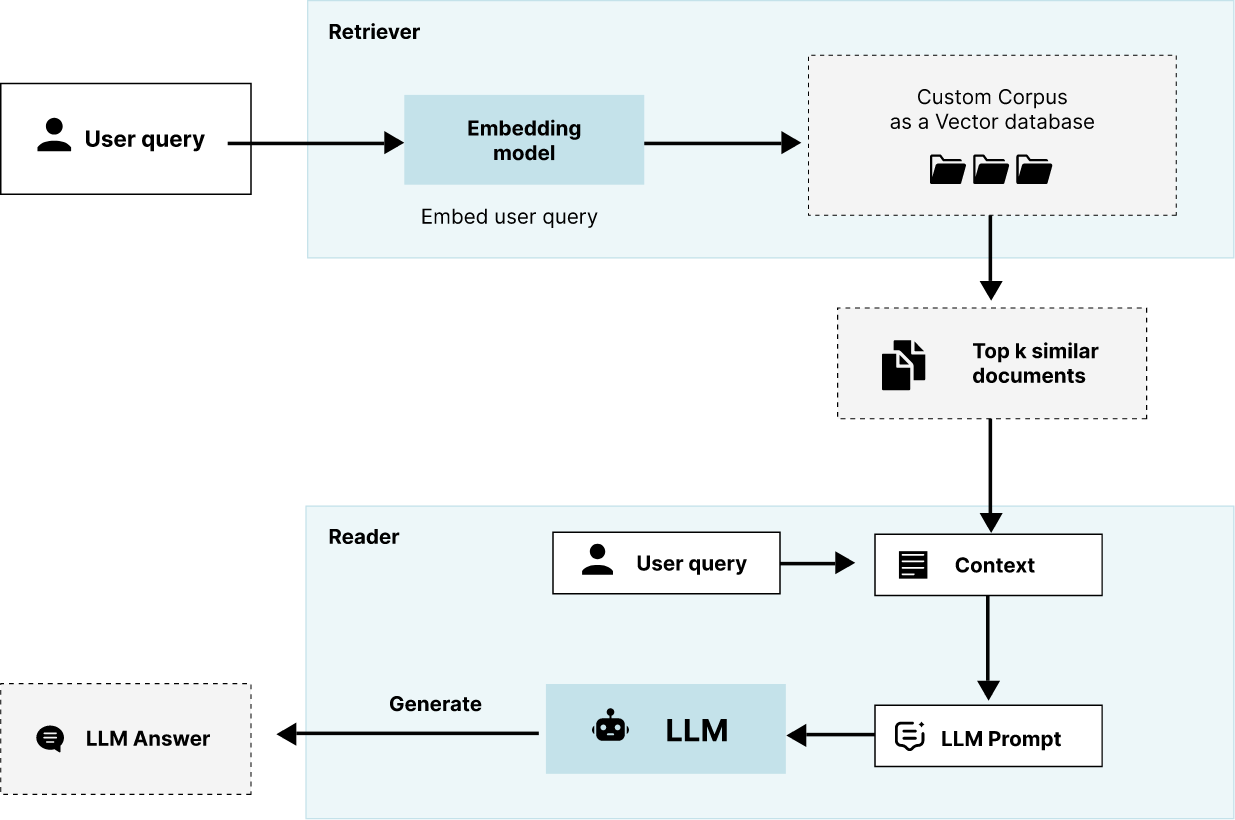
Retrieval Augmented Generation (RAG) is a technique that starts with the question being asked - uses a vector database to marry the questions with additional data, and then passes the question and data to an LLM for content creation. With RAG, no training is needed because we educate the LLM by sending it relevant text snippets from our corpus of quality documents.
It works like this using a question-answering task: A user asks a question in your application’s user interface. Your application will take the question - specifically the words in it - and, using a vector database, search your corpus of quality documents for text snippets that are contextually relevant. These snippets and the original question get sent to the LLM. This entire package - question plus snippets (context) is known as a prompt. The LLM will use this information to generate your answer. This may seem like a silly thing to do - if you already know the answer (the snippets), why bother with the LLM? Remember, this is happening in real-time, and the goal is to generate text - something you can copy and paste into your research. You need the LLM to create the text that incorporates the information from your custom corpus.
This is more complicated than fine-tuning. However, user authorization can be implemented since the documents (or document snippets) are selected from the vector database at inference time. The information in the documents never becomes a part of the model's parametric parameters. The advantages and disadvantages of RAG are listed below.
Disadvantages
- Inference flow is more complicated.
Advantages
- The LLM has direct knowledge from your custom corpus.
- Explainability is possible.
- No fine-tuning is needed.
- Hallucinations are significantly reduced and can be controlled by examining the results from the vector database queries.
- Authorization can be implemented.
Machine Learning Operations (MLOps)
Why ML Development Differs from App Development
To better understand the importance of MLOps, it is helpful to compare model creation to conventional application development. Conventional application development, like implementing a new microservice that adds a new feature to an application, starts with reviewing a specification. Any new data structures or any changes to existing data structures are designed first. The design of the data should not change once coding begins. The service is then implemented and coding is the main activity in this process. Unit tests and end-to-end tests are also coded. These tests prove that the code is not faulty and correctly implements the specification. They can be run automatically by a CI/CD pipeline before deploying the entire application.
Creating a model and training it is different. An understanding of the raw data and the needed prediction is the first step. ML engineers do have to write some code to implement their neural networks or set up an algorithm, but coding is not the dominant activity. Repeated experimentation is the main activity. During experimentation, the design of the data, the design of the model, and the parameters used will all change. After every experiment, metrics are created that show how the model performed as it was trained. Metrics are also generated for model performance against a validation set and a test set. These metrics are used to prove the quality of the model. Once a model is ready to be incorporated into an application, it needs to be packaged and deployed.
MLOps, short for Machine Learning Operations, is a set of practices and tools aimed at addressing these differences. Experiment tracking and collaboration are the features most associated with MLOPs, but the more modern MLOPs tools in the industry today can do much more. For example, they can provide a runtime environment for your experiments, and they can package and deploy models once they are ready to be integrated into an application. Below is a superset of features found in MLOps tools today. This list also includes other things to consider, such as support and data integration.
Key MLOps Capabilities
- Support from a major player - MLOps techniques and features are constantly evolving. You want a tool that is backed by a major player, ensuring that the tool is under constant development and improvement.
- Modern Datalake Integration - Experiments generate a lot of structured and unstructured data. Ideally, this could be stored in the Data Warehouse and the Data Lake. However, many MLOps tools were around before the Open Table Formats that gave rise to the Modern Datalake, so most will have a separate solution for their structured data.
- Experiment Tracking - Keep track of each experiment's datasets, models, hyperparameters, and metrics. Experiment tracking should also facilitate repeatability.
- Facilitate Collaboration - allow team members to view the results of all experiments run by all ML engineers.
- Model Packaging - Package the model such that it is accessible from other programming environments.
- Model Serving - Deploying models to an organization’s formal environments. You will not need this if you have found a way to incorporate your models into an existing CI/CD pipeline.
- Model Registry - Maintain all versions of all models.
- Serverless Functions - Some tools provide features that allow code to be annotated in such a way that a function or model can be deployed as a containerized service for running experiments in a cluster.
- Data Pipeline Capabilities - Some MLOps tools aim to provide complete end-to-end capabilities and have features that allow you to build pipelines for retrieving and storing your raw data. You will not need this if you already have a data pipeline.
- Training Pipeline Capabilities - The ability to orchestrate your serverless functions into a Directed Acyclic Graph. Also allows for the scheduling and running of training pipelines.
Related: MLOps Architecture Guide for AI Infrastructure
The Impact of GPUs on your AI Data Infrastructure
The Starving GPU Problem
A chain is as strong as its weakest link - and your AI/ML infrastructure is only as fast as your slowest component. If you train machine learning models with GPUs, then your weak link may be your storage solution. The result is what we call the “Starving GPU Problem.” The Starving GPU problem occurs when your network or your storage solution cannot serve training data to your training logic fast enough to fully utilize your GPUs. The symptoms are fairly obvious. If you monitor your GPUs, you will notice that they never get close to being fully utilized. If you have instrumented your training code, then you will notice that total training time is dominated by IO.
Unfortunately, there is bad news for those who are wrestling with this issue. GPUs are getting faster. Let’s look at the current state of GPUs and some advances being made with them to understand how this problem will only get worse in the coming years.
The Current State of GPUs
GPUs are getting faster. Not only is raw performance getting better, but memory and bandwidth are also increasing. Let’s take a look at these three characteristics of Nvidia’s most recent GPUs the A100, the H100 and the H200.
(Note: the table above uses the statistics that align with a PCIe (Peripheral Component Interconnect Express) socket solution for the A100 and the SXM (Server PCI Express Module) socket solution for the H100 and the H200. SXM statistics do not exist for the A100. With respect to performance, the Floating Point 16 Tensor Core statistic is used for the comparison.)
A few comparative observations on the statistics above are worth calling out. First, the H100 and the H200 have the same performance (1,979 TFLOPS), which is 3.17 times greater than the A100. The H100 has twice as much memory as the A100 and the memory bandwidth increased by a similar amount - which makes sense otherwise, the GPU would starve itself. The H200 can handle a whopping 141GB of memory and its memory bandwidth also increased proportionally with respect to the other GPUs.
Let’s look at each of these statistics in more detail and discuss what it means to machine learning.
Performance - A teraflop (TFLOP) is one trillion (10^12) floating-point operations per second. That is a 1 with 12 zeros after it (1,000,000,000,000). It is hard to equate TFLOPs to IO demand in gigabytes as the floating point operations that occur during model training involve simple tensor math as well as first derivatives against the loss function (a.k.a. gradients). However, relative comparisons are possible. Looking at the statistics above, we see that the H100 and the H200, which both perform at 1,979 TFLOPS, are three times faster - potentially consuming data 3 times faster if everything else can keep up.
GPU Memory - Also known as Video RAM or Graphics RAM. The GPU memory is separate from the system's main memory (RAM) and is specifically designed to handle the intensive graphical processing tasks performed by the graphics card. GPU memory dictates batch size when training models. In the past, batch size decreased when training logic moved from a CPU to a GPU. However, as GPU memory catches up with CPU memory in terms of capacity, the batch size used for GPU training will increase. When performance and memory capacity increase at the same time, the result is larger requests where each gigabyte of training data is getting processed faster.
Memory Bandwidth - Think of GPU memory bandwidth as the "highway" that connects the memory and computation cores. It determines how much data can be transferred per unit of time. Just like a wider highway allows more cars to pass in a given amount of time, a higher memory bandwidth allows more data to be moved between memory and the GPU. As you can see, the designers of these GPUs increased the memory bandwidth for each new version proportional to memory; therefore, the internal data bus of the chip will not be the bottleneck.
Supercharge Object Storage for Model Training
If you are experiencing the Starving GPU problem, then consider using a 100 GB network and NVMe drives. MinIO has created a comprehensive blueprint for data infrastructure to support exascale AI and other large scale data lake workloads. It is called the MinIO DataPod. Why? Because exascale data is the reality that is common today in today's enterprise.
As the computing world has evolved and the price of DRAM has plummeted we find that server configurations often come with 500GB or more of DRAM. When you are dealing with larger deployments, even those with ultra-dense NVMe drives, the number of servers, multiplied by the DRAM on those servers can quickly add up - often to many TBs per instance. That DRAM pool can be configured as a distributed shared pool of memory and is ideal for workloads that demand massive IOPS and throughput performance. As a result, we built MinIO Cache to enable our AIStor customers to configure their infrastructure to take advantage of this shared memory pool to further improve performance for core AI workloads - like GPU training - while simultaneously retaining full persistence.
A Tale of Two Organizations
Two Organizational Approaches
As a concluding thought experiment, let’s tell a tale of two organizations that take very different approaches on their AI/ML journey. Organization #1 has a culture of “Iterative Improvements.” They believe that all big initiatives can be broken down into smaller, more manageable projects. These smaller projects are then scheduled in such a way that each one builds on the results of the previous project to solve problems of greater and greater complexity. They also like these small projects organized in such a way that each one delivers value to the business. They have found that projects that are purely about improving infrastructure or modernizing software without any new features for the business are not very popular with the executives in control of budgets. Consequently, they have learned that requesting fancy storage appliances and compute clusters for a generative AI proof of concept is not the best way to orchestrate infrastructure improvements and new software capabilities. Rather, they will start small with infrastructure products that can scale as they grow - and they will start with simple AI models so they can get their MLOPs tooling in place and figure out how to work with existing DevOps teams and CI/CD pipelines.
Organization #2 has a “Shiny Objects” culture. When the newest idea enters the industry, it first tackles the highest-profile challenge to demonstrate its technical might. They have found these projects are highly visible both internally and externally. If something breaks, then smart people can always fix it.
Outcomes and Lessons
Organization #1 structured its first project by building out a portion of its AI data infrastructure while working on a recommendation model for its main e-commerce site. The recommendation model was relatively simple to train. It is a discriminative model that uses datasets that already exist on a file share. However, at the end of this project the team had also built out a small (but scalable) Modern Datalake, implemented MLOPs tooling, and had some best practices in place for training and deploying models. Even though the model is not complicated, it still added a lot of efficiencies to their site. They used these positive results to get funding for their next project, which will be a generative AI solution.
Organization #2 built a chatbot for their e-commerce site that answered customer questions about products. Large Language models are fairly complicated - the team was not familiar with Fine-tuning or Retrieval Augmented Generation - so all engineer cycles for this project were focused on moving quickly over a steep learning curve. When the model was complete, it produced OK results - nothing spectacular. Unfortunately, it had to be manually side-loaded into the pre-production and production environments because there was no MLOps tooling in place to deploy it. This caused a little friction with the DevOps team. The model itself also had a few stability issues in production. The cluster it was running in did not have enough compute for a generative AI workload. There were a few severity-one calls, which resulted in an emergency enhancement to the cluster so the LLM would not fail under heavy traffic conditions. After the project, a retrospective determined that they needed to augment their infrastructure if they were going to be successful with AI.
A Plan for Building Your AI/ML Data Infrastructure
The short story above is a simple narrative of two extreme circumstances. Building AI models (both discriminative and generative) is significantly different from conventional software development. This should be taken into account when queuing up an AI/ML effort. The graphic below is a visual depiction of the story told in the previous section. It is a side by side comparison of AI Data Infrastructure First vs. the Model First approach. As the story above showed - each of the bricks below for the infrastructure first approach does not have to be a standalone project. Organizations should look for creative ways to deliver on AI while their infrastructure is being built out - this can be done by understanding all the possibilities with AI, starting simple, and then picking AI projects of increasing complexity.
Infrastructure-First vs. Model-First

Related: The Full Stack AI Engineer Skills Guide
Conclusion
This post outlines our experience in working with enterprises to construct a Modern Datalake Reference Architecture for AI/ML. It identifies the core components, the key building blocks and the tradeoffs of different AI approaches. The foundational element is a modern data lake built on top of an object store. The object store must be capable of delivering performance at scale - where scale is hundreds of petabytes and often exabytes.
By following this reference architecture, we anticipate the user will be able to build a flexible, extensible data infrastructure which while targeted at AI and ML, will be equally performant on all OLAP workloads. To get specific recommendations on the component parts, please don’t hesitate to reach out to me at keith@min.io.






