Bringing ARM into the AI Data Infrastructure Fold at MinIO Using SVE
One of the reasons that MinIO is so performant is that we do the granular work that others will not or cannot. From SIMD acceleration to the AVX-512 optimizations we have done the hard stuff. Recent developments for the ARM CPU architecture, in particular Scalable Vector Extensions (SVE), presented us with the opportunity to deliver significant performance and efficiency gains over previous generations and enable ARM to become a first class citizen in the AI data infrastructure ecosystem.
This blog post will give an overview of what ARM SVE is and why it is important for the MinIO server and generally, how we enabled it.
Fans of ARM
We have long been fans of the ARM CPU architecture and as such we have supported ARM since the early days of MinIO. As there were no cloud instances with ARM CPUs available at that time, the initial development was actually done on a Pine64 board. A large part of the work consisted of adding 128-bit NEON vector instructions in order to accelerate some of the core algorithms of MinIO, most notably the erasure coding part, bit-rot detection (Highway Hash) and various hashing techniques like Blake2b and SHA256.
We published some blog posts on these topics, for instance Accelerating SHA256 by 100x in Golang on ARM. In addition we did some benchmarking back in 2020 between the Intel (amd64) and ARM (arm64) platforms, see Impact of Intel vs ARM CPU Performance for Object Storage. We encourage you to take in that work as it is seminal in the space.
Developments in the cloud: from AWS to GCP and Azure
With the introduction of Graviton 1 in 2019, AWS was the first cloud vendor to start designing their own CPUs based on the ARM architecture. Since then, three more versions have been introduced with Graviton 4 being the latest incarnation and offering 96-cores.
More recently this year, both Google and Microsoft are following suit with the announcements of Google's Axion processor as well as the Azure Cobalt 100 processor. For both these vendors, the main drivers to do this are offering both better performance and more energy efficiency.
Last but not least, NVIDIA is working closely with ARM with first the GH200 Grace Hopper and now the GB200 Grace Blackwell superchips. Both of these superchips combine dual GPUs with a 72-core ARM CPU supporting SVE2.
Another area where NVIDIA is making investments is on the "smart" networking controllers or DPU (Data Processing Unit) side which is a critical component given the disaggregated nature of compute and storage. The latest generation of the BlueField3 NIC offers an integrated 16-core ARM CPU as part of the network controller card itself. This has the potential to lead to simpler server designs by interfacing the NVMe drives directly to the networking card and bypassing any (main server) CPUs altogether.
Brief primer on SVE
While NEON has been around for over 10 years and "just" supports 128-bit wide vector instructions (only 2x wider than regular 64-bits instructions), first SVE and more recently SVE2 offer a significantly broader range of capabilities.
Most interestingly (and differently as compared to the Intel/amd64 SIMD architecture), SVE/SVE2 is a length-agnostic SIMD architecture. This means that the same machine code instructions run on hardware implementations with different sizes of the vector units. For example, the Graviton 3 implementation on AWS is 256-bit wide whereas the Fujitsu A64FX processor is a 512-bit wide implementation.
In addition to this, SVE offers support for lane masking via predicated execution which allows for more efficient utilization of the vector units. Extensive support for scatter and gather instructions make it possible to efficiently access memory in a flexible manner.
SVE and now SVE2 have a significantly broader instruction set and type system as compared to NEON, opening it up to a wider array of applications. Also note that SVE is not a superset of NEON but a fully new ISA (Instruction Set Architecture).
ARM SVE support for MinIO
We are excited to announce that we have expanded our support for the ARM CPU architecture by adding SVE support for two key algorithms, namely erasure coding as well as bit-rot detection as discussed below.
Reed Solomon
For release v1.12.2, we have contributed extensive ARM SVE support for the erasure coding library that is used by the MinIO object storage server. By "mimicking" the AVX2 implementation, we are now able to leverage all the optimization work that has gone into this library for ARM SVE as well.
Generally speaking, the new SVE implementation is about 2x faster as compared to the previous implementation, as is shown in this graph:
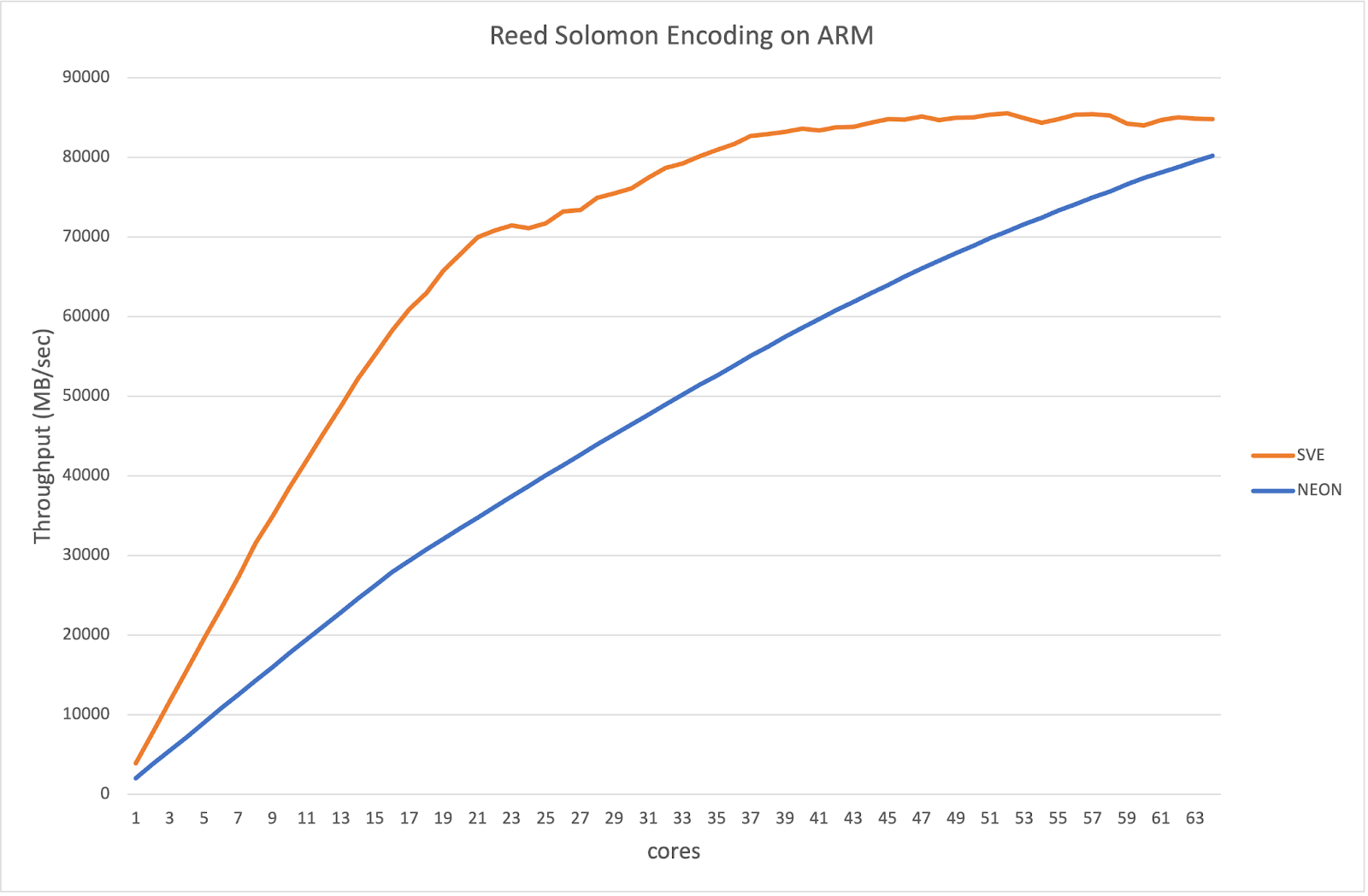
As can be seen, already at about using just a quarter of the available cores (around 16), half the memory bandwidth is consumed (which took roughly half the number of cores before). The performance continues to scale and starts to max out around using 32 out of the total of 64 cores.
Highway Hash
MinIO uses the Highway Hash algorithm for bit-rot detection which is very frequently run both during GET (read) as well as PUT (write) operations. Here too, we added SVE support for the core hashing update function with the following result:
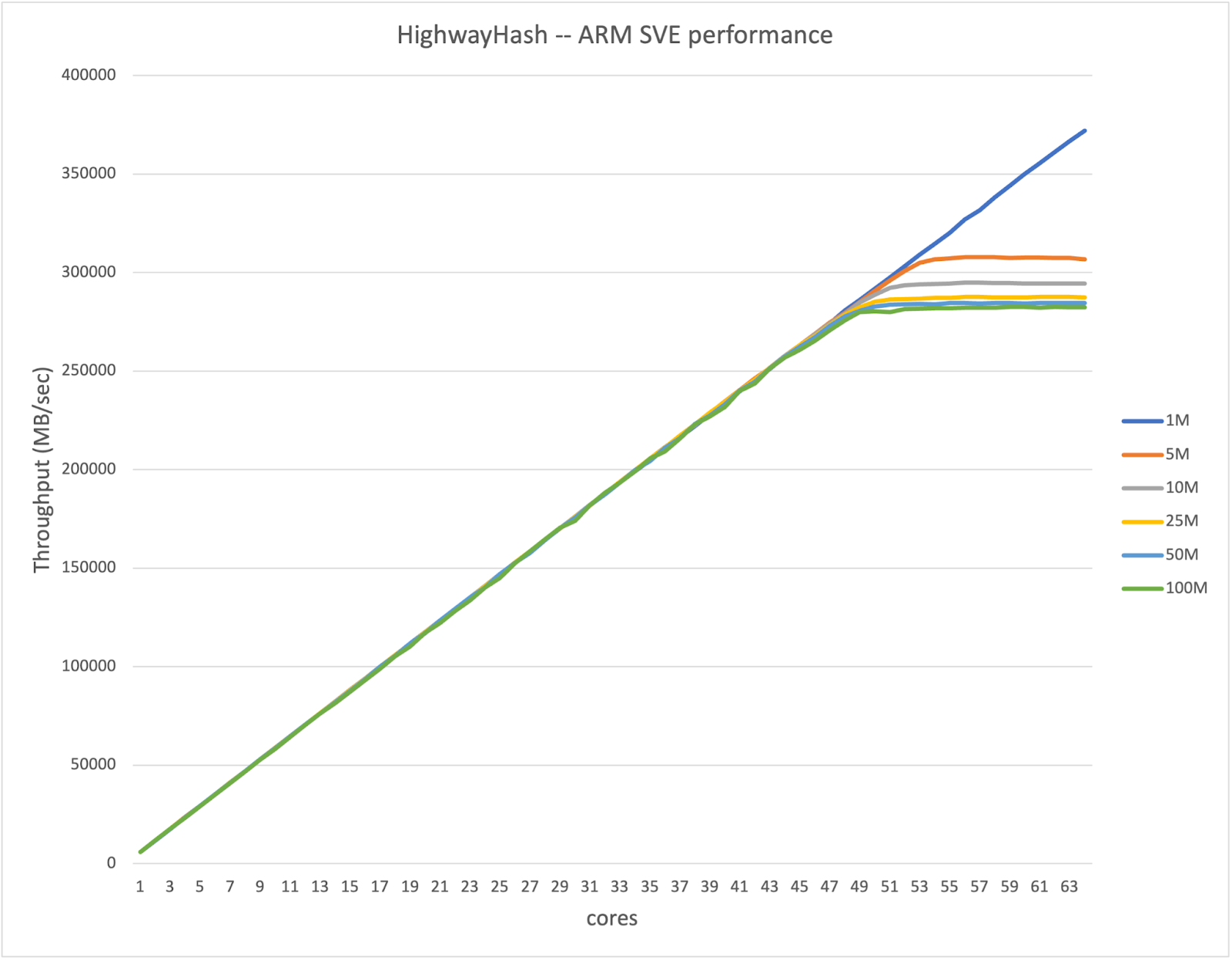
As is evident from the chart, the performance scales perfectly linearly as the core count goes up and starts to reach the memory bandwidth limit somewhere around the 50 to 52 cores for the larger block sizes.
Note that there is a slightly faster SVE2 algorithm that we haven't been able to test in hardware yet (only via the armie instruction emulator). So this should boost the performance by another 10% or so.
More to Come
We are investigating some further optimizations, for example some that have recently landed in the Linux kernel, so stay tuned for that.
Conclusion
ARM SVE marks a significant technological improvement that enables real-world performance gains for object storage and AI data infrastructure in particular. With ever more ARM SVE-based solutions coming to the market, we are excited to see how this technology will continue to evolve and improve.






