Build a Streaming CDC Pipeline with MinIO and Redpanda into Snowflake

Data-driven organizations often need to migrate data from traditional relational database management systems (RDMS) into modern datalakes for analytical workloads, repatriation from the cloud, as part of a centralized data strategy and other reasons. Change data capture (CDC) is a key pattern for achieving this by replicating changes from the RDMS into the data lakehouse where they are fed into cloud-native analytics and AI/ML applications.
Undoubtedly, Apache Kafka was groundbreaking at the time of its release ten years ago. Kafka remains embedded in both the data architectures and collective consciousness of many. However, wrangling with the realities of Zookeeper and JVM can be tedious and difficult. Over time, new players have emerged that do away with this additional complexity, with Redpanda being a standout alternative.
In this blog post, we will demonstrate the setup of a streaming CDC pipeline using Redpanda and MinIO, where MinIO becomes the datalake storage for Snowflake via external tables. This tutorial is based on Redpanda’s GitHub project. Clone this repository to follow along.
Related: AI Data Workflows with Kafka and MinIO
Introducing Our CDC Architecture
Let's start thinking about the components of this CDC pattern at a high level to gain an understanding of the components and how they fit together before we dive into coding.
- PostgreSQL as a stand-in for your source database.
- Redpanda as the streaming data platform.
- Debezium as the change data capture (CDC) agent.
- MinIO as object storage.
- Snowflake as the cloud-native analytics engine.
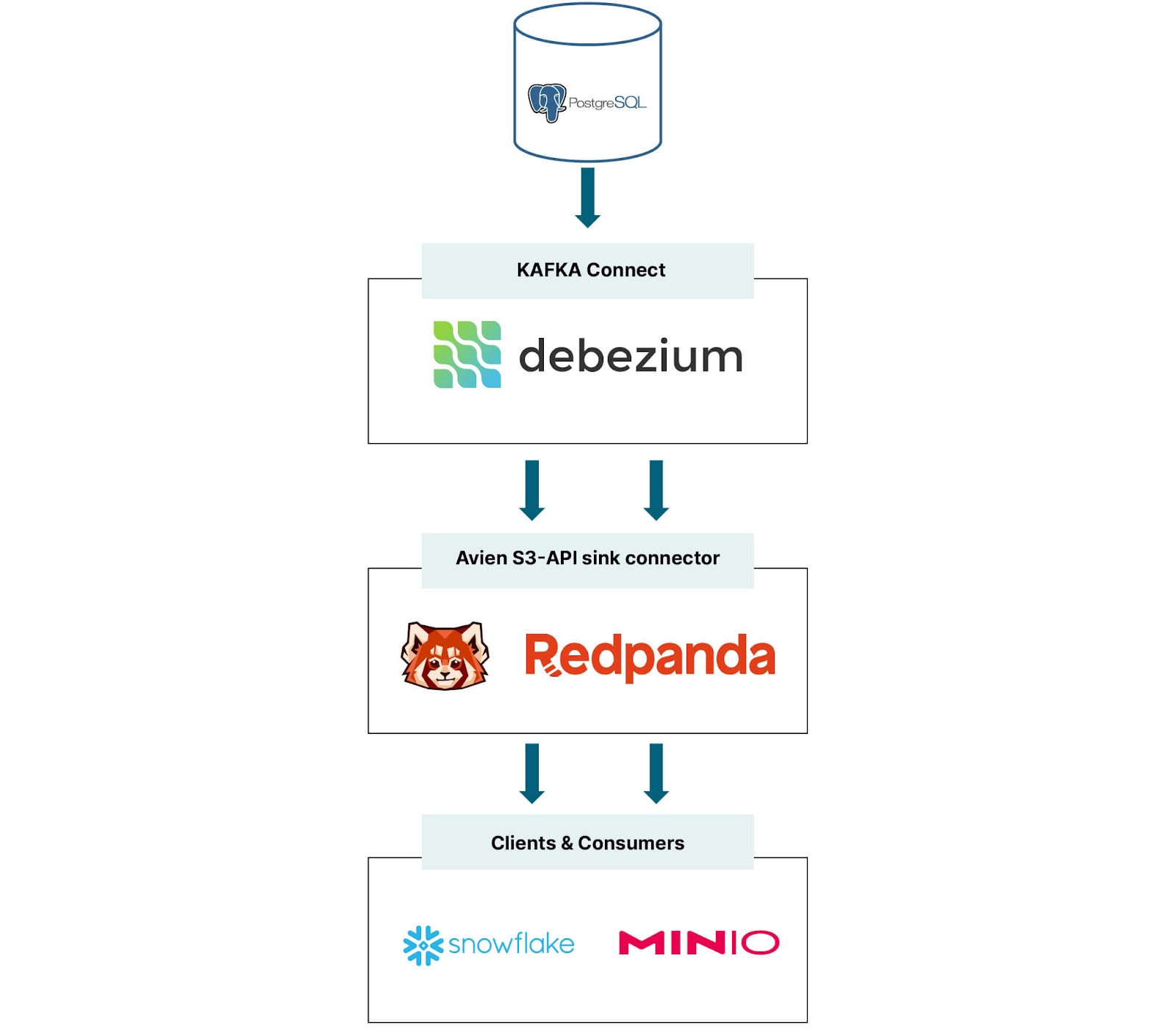
Redpanda is a lightweight, single binary, Kafka API-compatible, streaming platform. Redpanda is a uniquely good fit for CDC from RDMS for a few other reasons. First, Redpanda (unlike Kafka) adopted a columnar data storage format, a choice that enhanced storage efficiency and enabled quicker query response times and allowed them to support SQL-like queries on streaming data. These features should make users comfortable with SQL right at home in Redpanda. Secondly, Redpanda excels in scalability, accommodating both horizontal and vertical scaling, guaranteeing that your infrastructure can grow with the size of your data and your team.
Debezium fulfills its role by maintaining a transaction log that diligently tracks every alteration made to each table within your database. This enables applications such as Redpanda to efficiently access and read the necessary transaction logs, ensuring that they receive events in the exact sequence in which they transpire.
MinIO aligns with Redpanda in its architectural and operational simplicity, performance and scalability. Leveraging MinIO as storage for change data from a mission-critical RDMS aligns seamlessly with the modern datalake structure that allows for data to be accessed without ingestion wherever it resides; whether that is on-prem, in the private or public cloud, at the edge or on bare metal.
Snowflake functions as our analytics engine, perched atop MinIO, reaching into S3 API-compatible storage to retrieve data for analytics without direct ingestion. Cloud-native and secure, MinIO forms the foundation of a potent cloud strategy that keeps data under your control.
Prerequisites
You’ll need Docker Compose. You can either install the binaries for the Docker Engine and Docker Compose separately, or together in Docker Desktop.
Check to see if you have docker compose installed by running:
docker compose versionData Generation
For the purposes of this tutorial, we will assume that you have a functional relational database with CRUD operations (INSERTS, UPDATES, or DELETES) that you would like to capture. In this tutorial, we will use PostgreSQL as a substitute for your system
When using PostgreSQL for CDC, configure the 'wal_level' parameter to 'logical'. This adjustment enables you to utilize PostgreSQL's logical replication feature. It's important to note that this setting is what empowers Debezium to access and interpret the database's transaction log, thus enabling the generation of change events.
If you’d rather use your own database instead of PostgreSQL, you don’t have to run this next section, but you will have to make edits to the connection details hardcoded in the pg-src.json file.
To use the stand-in database, begin by running this command in the directory you cloned the tutorial files into.
docker-compose up -d postgres datagenThis command will start up a Postgres container, create two test tables called ‘user’ and ‘payment’ and execute a Python script that will begin to populate these tables with random data every few seconds.
SELECT * FROM public.user LIMIT 3;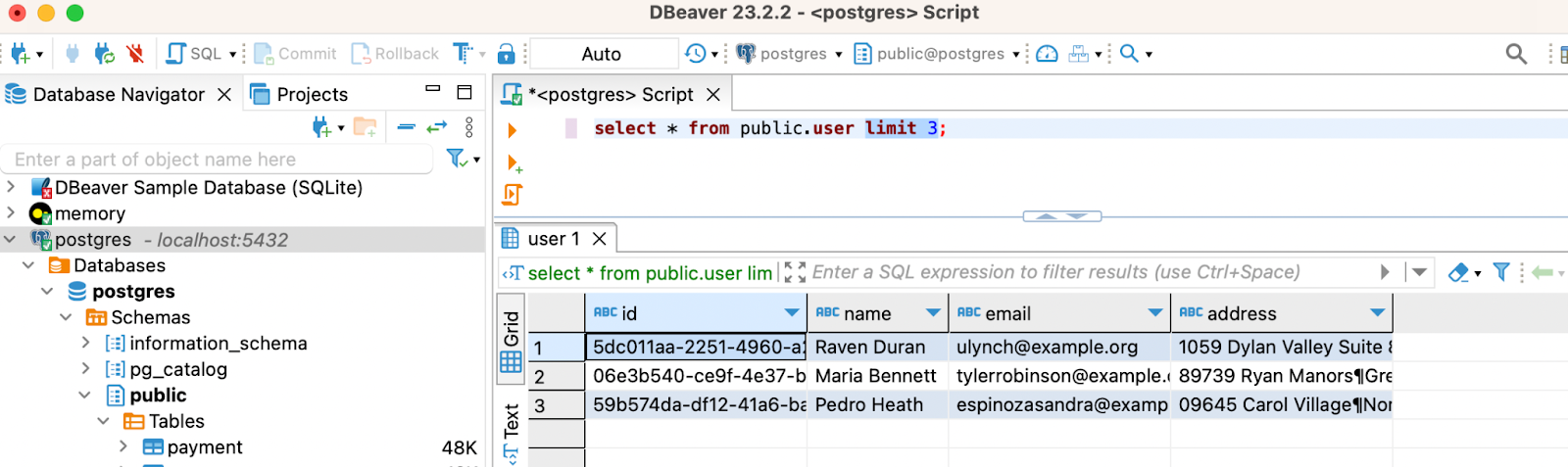
You should see the tables populate with data.
Setting up Redpanda and Debezium
Redpanda, Debezium and all their dependencies are combined in docker-compose.yml. Start up Redpanda and the Redpanda Console together in the tutorial directory with this command:
docker-compose up -d redpanda redpanda-console connectYou can check to make sure your Kafka Connect cluster is running by navigating to the Console at http://localhost:8080.
Once you’ve verified that Redpanda is up and running, exec into the connect container.
docker exec -it connect /bin/bashThen run the following commands to create the Debezium PostgreSQL connector and the Avien (explained below) connector.
curl -X PUT -H "Content-Type:application/json" localhost:8083/connectors/pg-src/config -d '@/connectors/pg-src.json'
curl -X PUT -H "Content-Type:application/json" localhost:8083/connectors/s3-sink/config -d '@/connectors/s3-sink.json'Refresh and navigate to the Connectors panel to see your new Connectors.
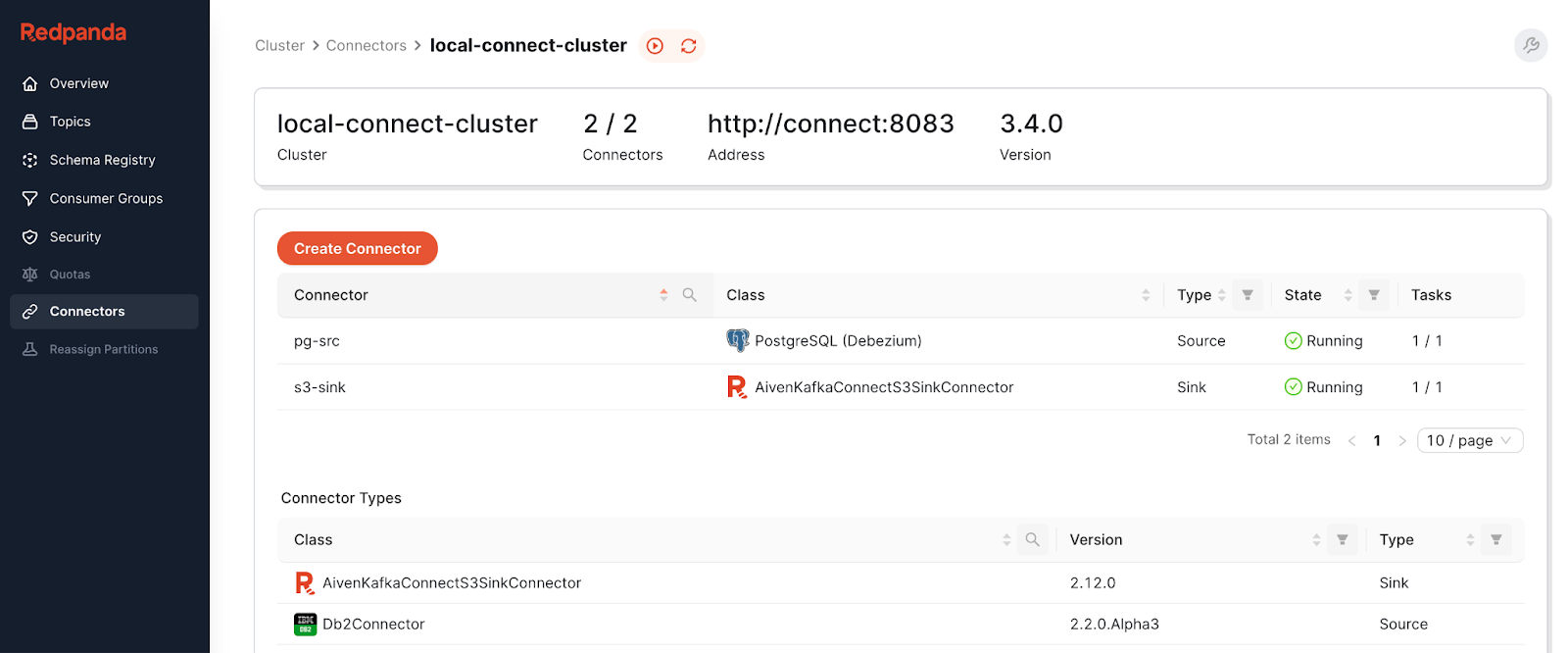
We’ve already explored the function of Debezium in this pattern, but Avien has gone unmentioned so far. Avien has created an S3-API sink connector that allows you to move data from Kafka clusters (such as Redpanda) into S3-compatible storage, like MinIO.
Setting up MinIO
You might already have a MinIO Server up and running. If this is the case, and you’d like to use this server instead, make sure that it is available to the Redpanda containers you’ve created, edit the connection details in s3-sink.json and skip the steps below.
If you want to use the tutorial’s container, run the following to start up a single-node MinIO server:
docker-compose up -d minio mcNavigate to ‘localhost:9000’ and log in. The default credentials in the .yml for this project are username: minio, password: minio123. You’ll begin to see objects populating your bucket.
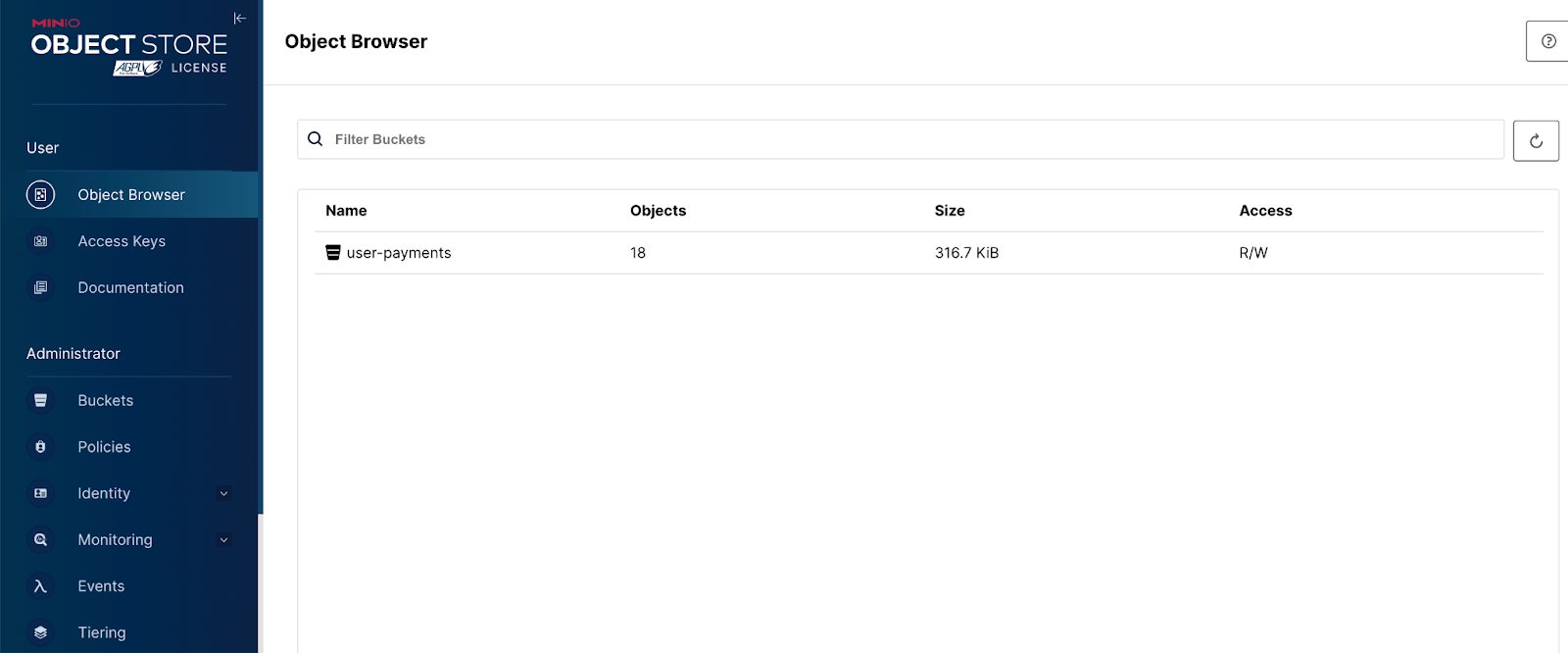
Querying Data with Snowflake
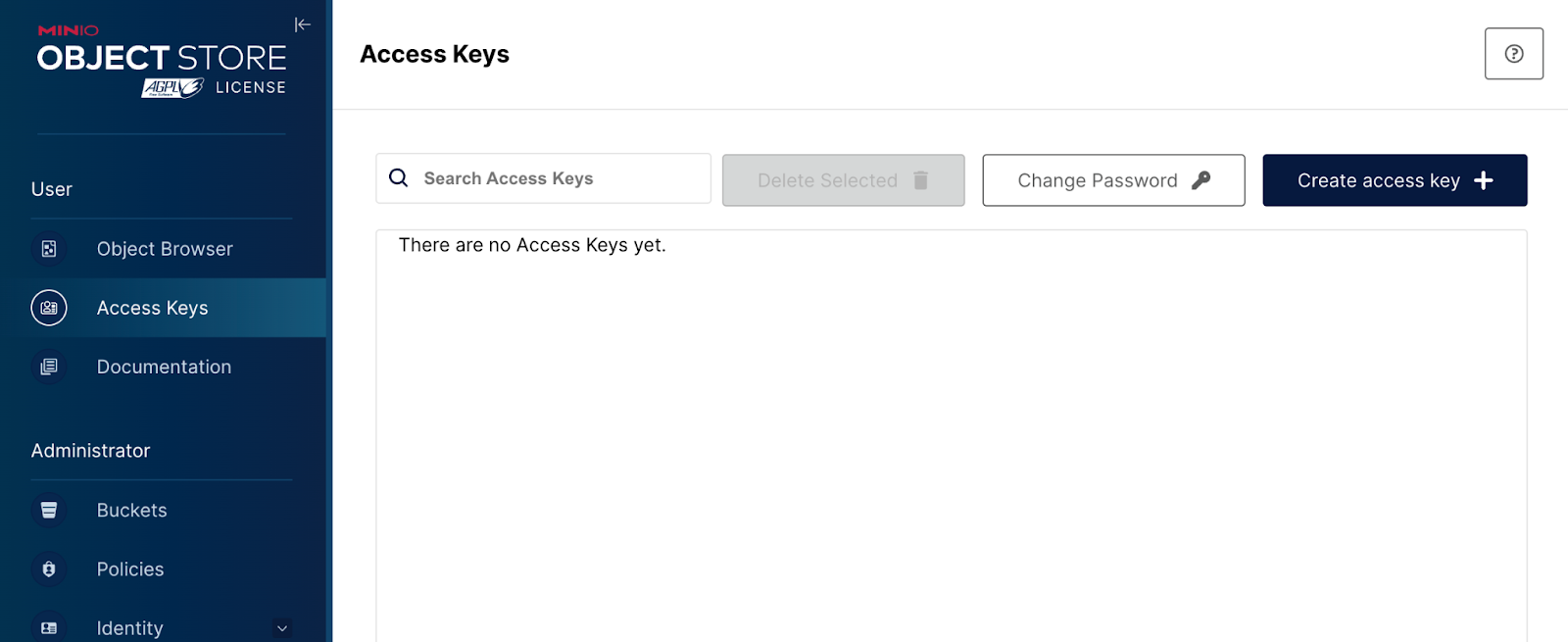
We now diverge from the original Redpanda tutorial to explore external tables with Snowflake. First, we will need to create Access Keys in MinIO for Snowflake. In production, it’s best practice to have a different bucket and credentials for each service.
To create Access Keys, navigate to the Access Keys panel and then click on the Create Access Key.
Some words of caution: MinIO has to be set up to allow for DNS-style access and the bucket has to be made public. Additionally, the region setting has to be either set to "NULL" or matched to the region of your Snowflake instance. Refer to this blog post for further tips and tricks using MinIO with Snowflake.
You can run the following in the Snowflake Console or Snowflake CLI to set up an external table from files in MinIO.
create database minio;
use database minio;
use warehouse compute_wh;
create or replace stage minio_stage
url = 's3compat://<your-bucket-name>'
endpoint = '<your-minio-endpoint>'
credentials=(
AWS_KEY_ID='<your-access-key>',
AWS_SECRET_KEY='<your-secret-key');
create or replace external table user_payments
with location = @minio_stage
file_format = (type = parquet)
auto_refresh=false
refresh_on_create=false;
You can now query your external table just the same as you would any other table without ever having to load data directly into Snowflake.
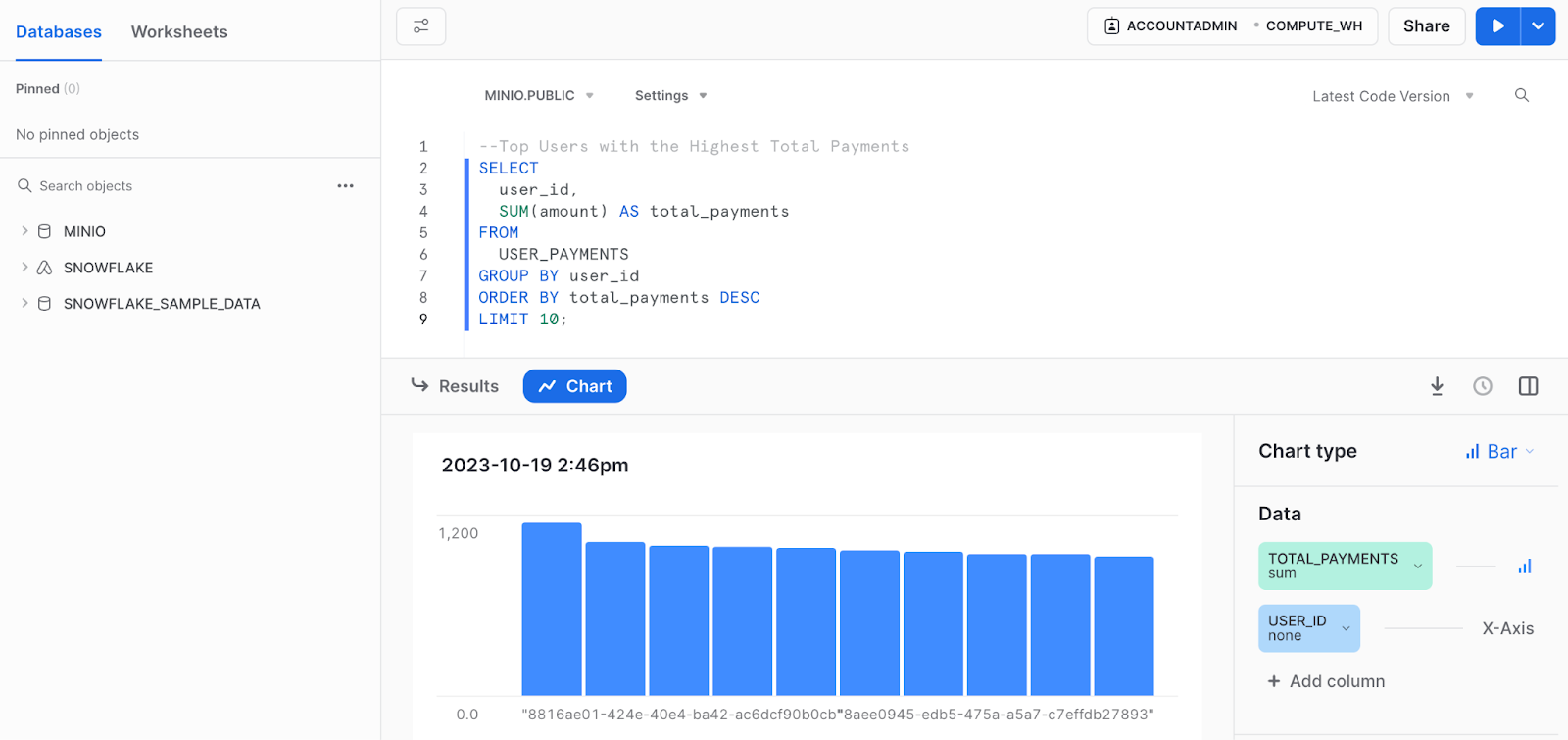
Conclusion
This blog post explored the implementation of a streaming Change Data Capture (CDC) pattern using Redpanda and MinIO, ending with integration with Snowflake. In the evolving landscape of data-driven organizations, this solution offers a robust, efficient, and scalable approach to data synchronization and analytics.
If you have any questions about your implementation of this design, ping us at hello@min.io or join the Slack community.






