Building a Data Lakehouse using Apache Iceberg and MinIO

Introduction
In a previous post, I provided an introduction to Apache Iceberg and showed how it uses MinIO for storage. I also showed how to set up a development machine. To do this, I used Docker Compose to install an Apache Spark container as the processing engine, a REST catalog, and MinIO for storage. I concluded with a very simple example that used Apache Spark to ingest data and PyIceberg to query the data. If you are new to Apache Iceberg or if you need to get Apache Iceberg set up on your development machine, then give this introductory post a read.
In this post, I’ll pick up where my previous post left off and investigate a common big data problem – the need for a single solution to provide storage for raw data, unstructured data, and structured data (data that has been curated from raw data). Additionally, the same solution should provide a processing engine that allows for efficient reporting against the curated data. This is the promise of Data Lakehouse solutions - the capabilities of Data Warehouses for structured data and the capabilities of Data Lakes for unstructured data - all in a centralized solution.
Let’s look at our big data scenario in more detail.
A Common Problem
The diagram below depicts a common problem and a hypothetical solution. Data is coming into a data center from multiple locations and in multiple formats. What is needed is a centralized solution that allows raw data to be transformed such that a processing engine can efficiently support business intelligence, data analytics, and machine learning. At the same time, this solution must also be capable of storing unstructured data (text, images, audio, and video) for data exploration and machine learning. It should also keep any data that was transformed in its original format in case a transformation needs to be replayed or a data integrity issue needs to be investigated.
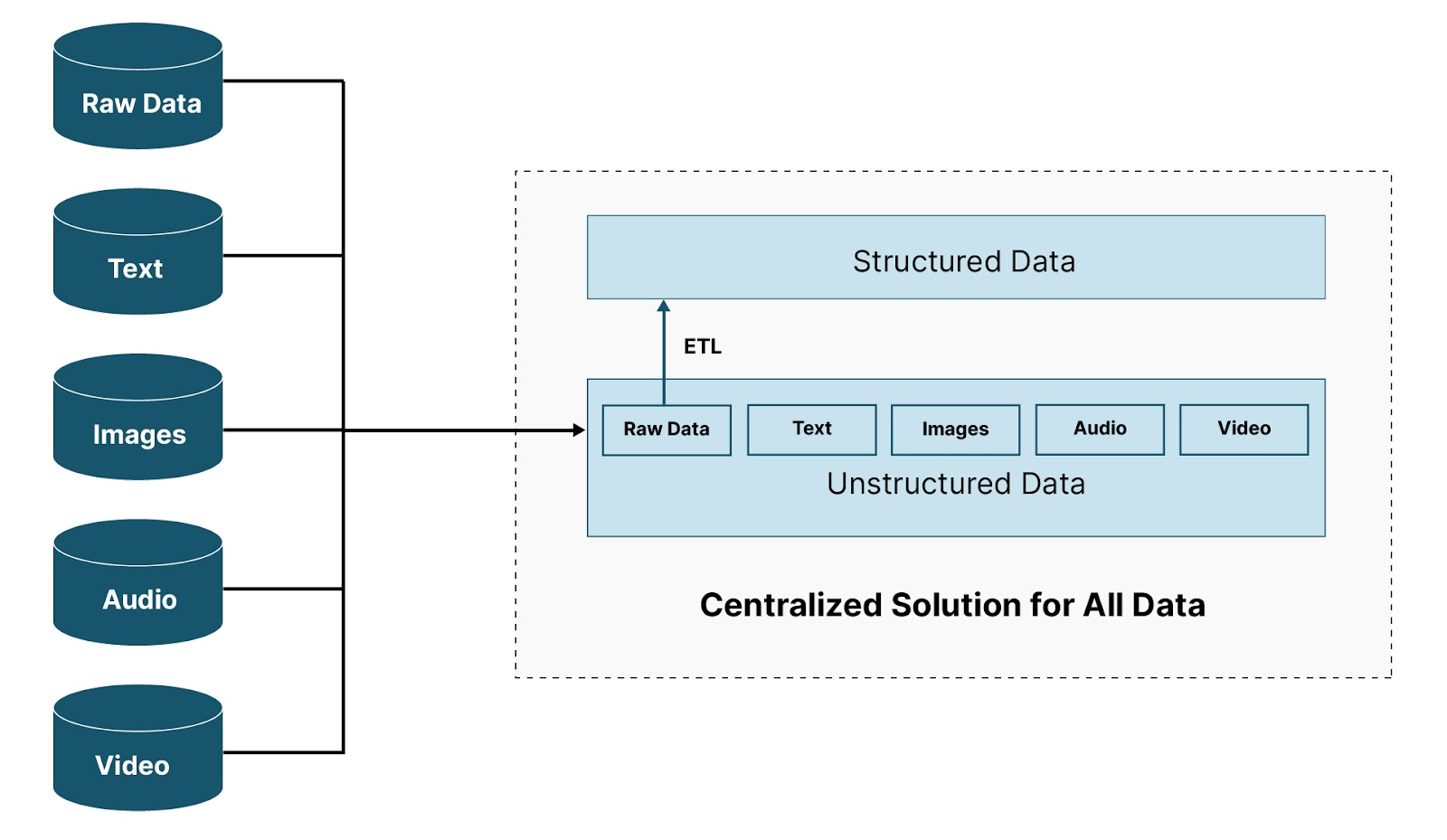
As a concrete example, imagine a global custodial bank that is managing mutual funds for its clients. Data representing the accounting book of records and the investment book of records for each fund for each client is streaming into the Data Lakehouse constantly from geographies around the world. From there, safe passage checks need to occur (was everything sent received), and data quality checks need to run. Finally, the data can be partitioned and loaded into another store that will support start-of-day and end-of-day reporting.
Alternately, maybe this diagram represents an IOT scenario where weather stations are sending temperature and other weather-related data. Regardless of the scenario, what is needed is a way to store the data safely in its original format and then transform and process any data that needs to be stored in a more structured fashion - all in one centralized solution. This is the promise of a Data Lakehouse - the best of a Data Warehouse and a Data Lake combined into one centralized solution.
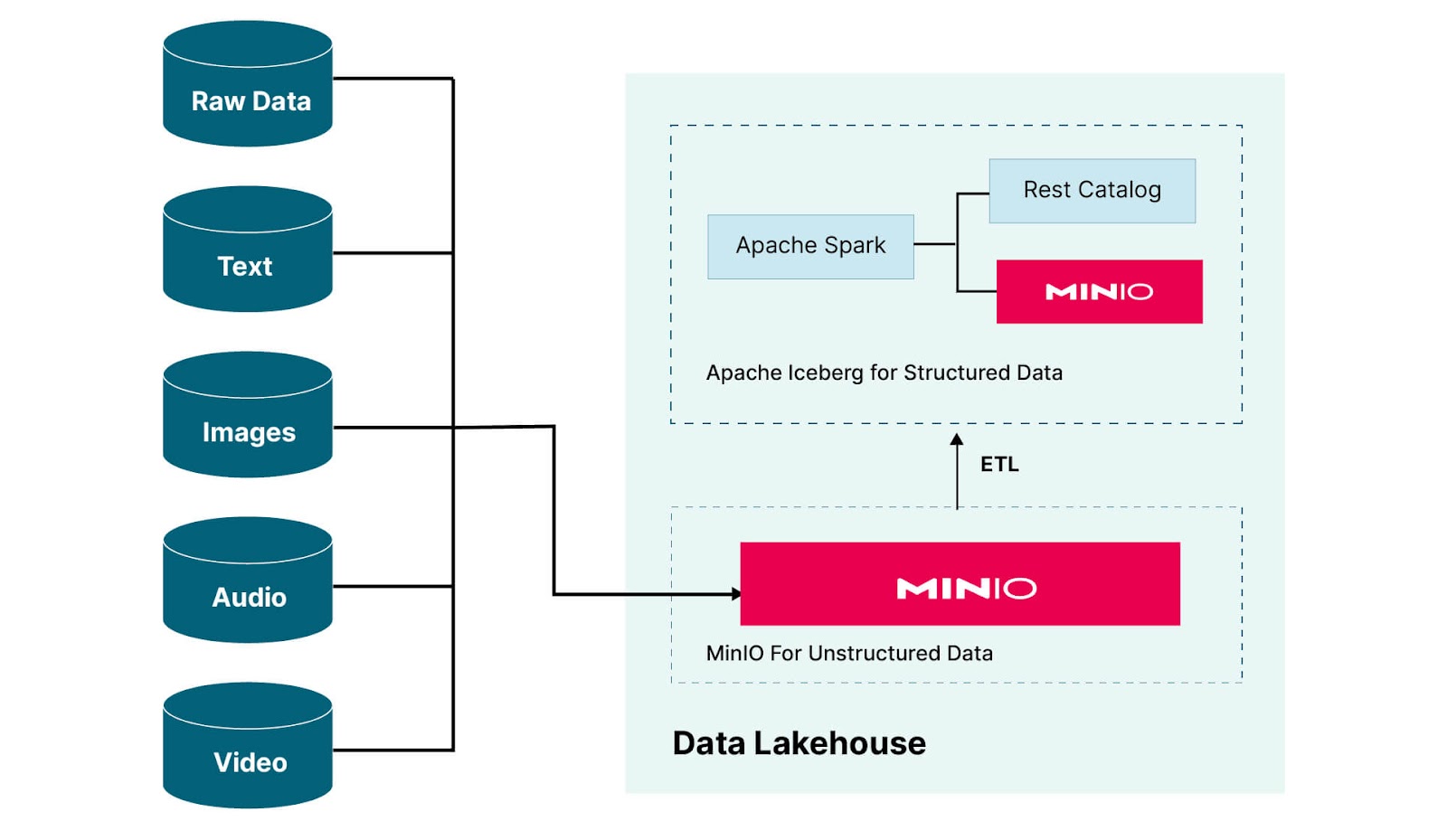
Let’s make the hypothetical solution described above real. This is depicted in the diagram below.
Related: Data Lakehouse Examples in Action
There are two logical components to our Data Lakehouse. The first is an implementation of Apache Iceberg for structured data - the equivalent of a Data Warehouse. (This is what I built out in my previous post - so I will not go into detail here.) The second logical component is MinIO for unstructured data - the Data Lake side of our Data Lakehouse. All data coming into the Lakehouse is delivered to this logical instance of MinIO. In reality, the two logical instances of MinIO shown above could be the same instance of MinIO in your data center. If the cluster you are running MinIO in can handle the ingestion of all incoming data and the processing requirements of Apache Iceberg, then such a deployment will save money. This is, in fact, what I will do in this post. I’ll use a bucket within Apache Iceberg’s instance of MinIO to hold all unstructured and raw data.
Let’s start playing with data by introducing the dataset I will use for this exercise and ingesting it into MinIO.
The Global Summary of the Day Dataset
The dataset we will experiment with in this post is a public dataset known as the Global Surface Summary of the Day (GSOD), which is managed by the National Oceanic and Atmospheric Administration (NOAA). NOAA currently maintains data from over 9000 stations around the world and the GSOD dataset contains summary information per day from these stations. You can download the data here. There is one gzip file per year. It starts in 1929 and ends in 2022 (at the time of this writing). To build our Data Lakehouse, I downloaded every year’s file and put it in the MinIO instance being used for our Data Lakehouse. I put all files in a bucket named `lake.` The two buckets within our instance of MinIO are shown below. The `warehouse` bucket was created when we installed Apache Iceberg.

I used the MinIO console to ingest the raw data manually. In a professional pipeline, you will want to do this in an automated fashion. Check out How to Set up Kafka and Stream Data to MinIO in Kubernetes to see how to use Kafka and Kubernetes to get data into MinIO.
These files are packaged for downloading convenience – if you try to use them directly to create a report or a graph, then that would be a very IO-intensive operation (and potentially CPU-intensive). Imagine that you want to chart the average temperature per year from a specified station. To do this, you have to open every file and search through every row, looking for the entries that match your station on the day of interest. A better option is to use our Data Lakehouses capabilities for curating the data and reporting on the curated data. The first step is to set up a new Jupyter notebook.
Set up a Jupyter Notebook
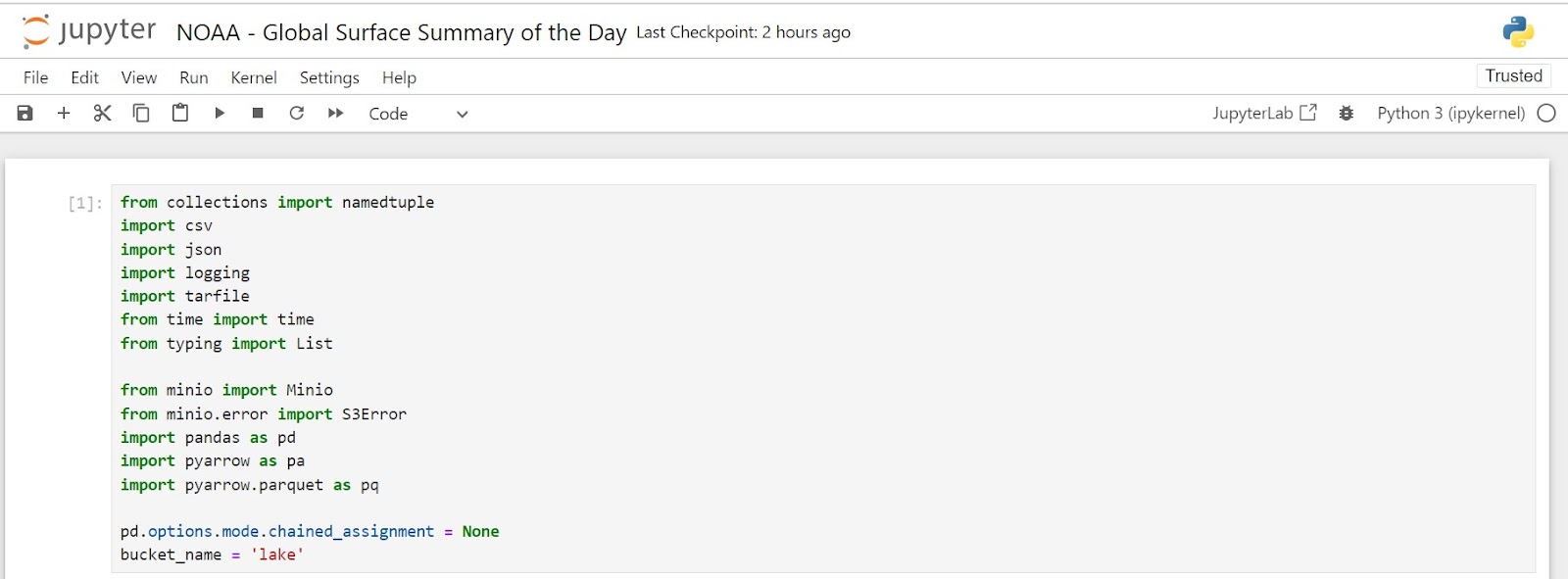
First, navigate to the Jupyter Notebook server that is installed in the Apache Spark processing engine. It can be found at http://localhost:8888. Create a new notebook and in the first cell, add the imports shown below. (All the completed notebooks created in this post can be found here.)
Notice that we are importing the MinIO library. The notebook we are building is an ETL pipeline from unstructured storage (MinIO Data Lake) to structured storage (Apache Iceberg, which uses MinIO under the hood.) The start of your notebook should look like this.
Now, we can create an Iceberg database and table for our data.
Creating an Iceberg Database and Table
Creating the database and table for the GSOD dataset is straightforward. The script below will create the database which we will name `noaa`. Add this in a cell after the imports.
The script below will create the `gsod` table.
As you play around with Apache Iceberg, you will often want to drop a table so you can start an experiment over. The script below will drop the `gsod` table should you wish to change anything about its setup.
Ingesting Data from MinIO to Iceberg
Now that we have the raw year-based zip files in our Lakehouse, we can extract, transform and load them into our Data Lakehouse. Let’s introduce some helper functions first. The function below will return a list of MinIO objects in a specified bucket that matches a prefix.
Note that in the code above, a MinIO credentials file is needed. This can be obtained from the MinIO console. If you do not know how to get MinIO credentials, then there is a section of this post that shows how to generate and download them.
Next, we need a function to get an object from MinIO. Since the objects are tar files we also need this function to extract data out of the tar archive and transform it into a Pandas DataFrame. This is done using the function below.
Both of these functions are generic utilities that can be reused regardless of what you are doing with MinIO. Consider putting them in your personal collection of code snippets or your organization's Github Gist.
Now, we are ready to send data to the warehouse side of our Lakehouse. This can be done with the code below, which starts a Spark session, loops through all the GSOD tar files, extracts, transforms and sends it to our Iceberg table.
The code in this section manually loaded data from a MinIO bucket. In a production environment, you will want to deploy this code in a service and use MinIO Bucket Events for automated ingestion.
Querying the Iceberg Data Lakehouse using PyIceberg
Let’s start a new notebook for reporting. The cell below imports the utilities we will need. Specifically, we will be using PyIceberg for data retrieval, Pandas for data wrangling, and Seaborn for visualizing data.
What we want to do is calculate the average temperature per year for a given weather station. This gives us one number per year and takes into account all the seasons of the year. The first step is to query Iceberg for all data for a given station. This is done below using PyIceberg.
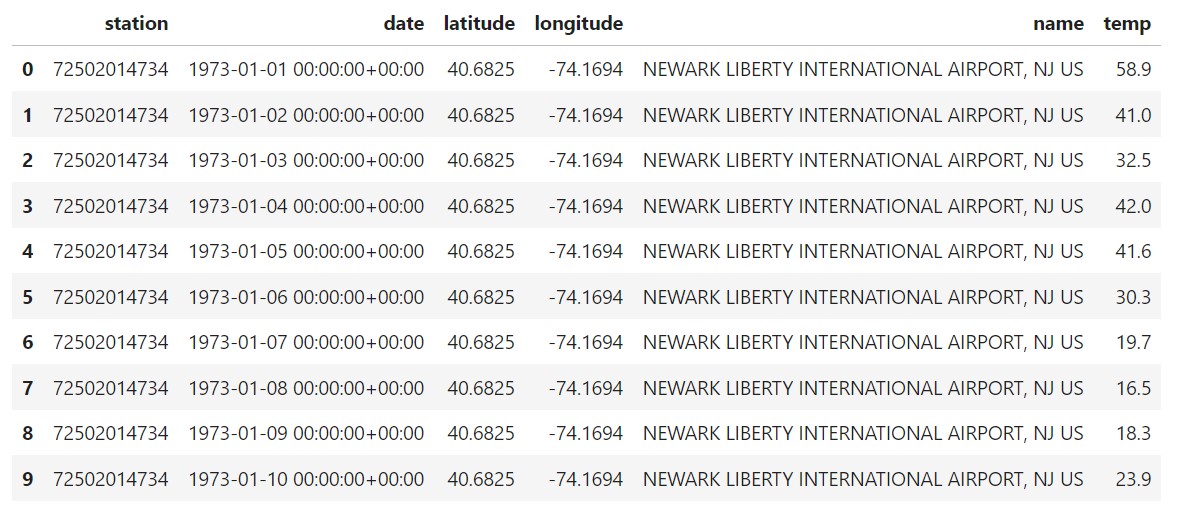
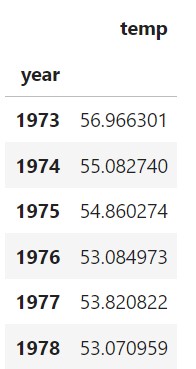
The station id used in the code above is for a station located at Newark Liberty International Airport, NJ, US. It has been operational since 1973 (almost 50 years of data). When the code runs, you will get the output below. (I am using the DataFrame head() function to get a sample.)
Next, we need to group by year and calculate the mean. Using Pandas, this is a few lines of code. No looping is needed.
Once this cell runs, you will see a single value for each year. The top few years are shown below.
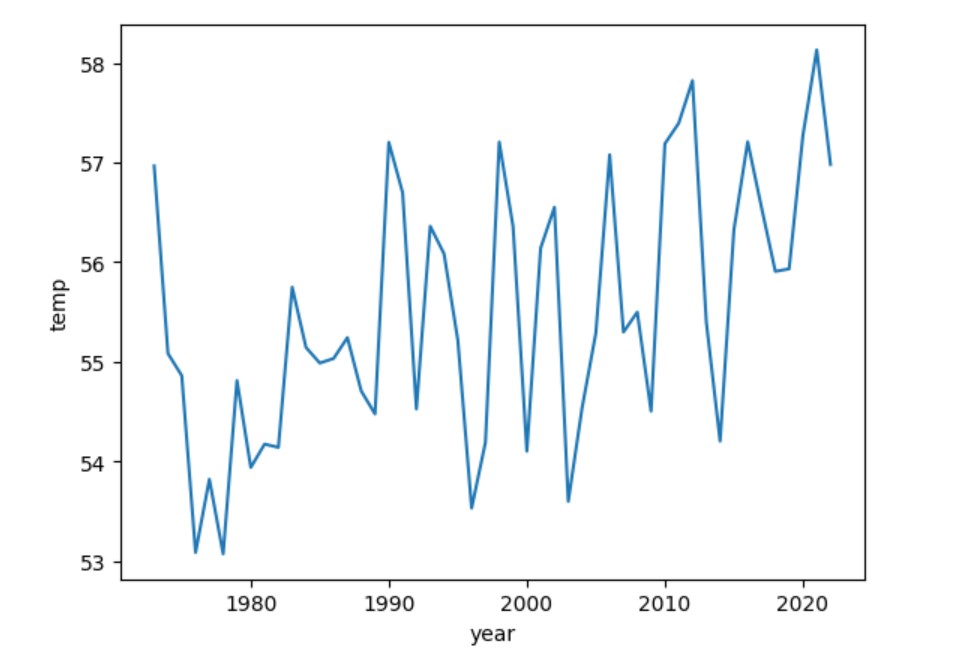
Finally, we can visualize our yearly averages. We will use Seaborn to create a line plot. This takes just one line of code.
The line plot is shown below.
Another command you should always run after running a report for the first time is below.
This is a list comprehension that will give you a list of all the data files in Apache Iceberg that have data matching your query. There will be a lot, even though Iceberg’s metadata can filter out many. Seeing all the files involved drives home the fact that high-speed object storage is an important part of a Lakehouse.
Summary
In this post, we built a Data Lakehouse using MinIO and Apache Iceberg. We did this using the GSOD dataset. First, raw data was uploaded to the Lake side of our Data Lakehouse (MinIO). From there, we created a database and a table in Apache Iceberg (the Data Warehouse side of our Data Lakehouse). Then we built a simple ETL pipeline to move data from the Lake to the Warehouse within the Data Lakehouse.
Once we had Apache Iceberg fully populated with data, we were able to create an average yearly temperature report and visualize it.
Keep in mind that if you want to build a Data Lakehouse in production, then you will need MinIO’s enterprise features. Consider looking at Object Lifecycle Management, Security Best Practices, Kafka Streaming and Bucket Events.






