Building an S3 Compliant Stock Market Data Lake with MinIO
In all my previous posts on MinIO, where I had to write code, I used MinIO’s Python SDK, which is documented here. I prefer this SDK because it is easy to use and it provides programmatic access to MinIO’s enterprise features, such as Lifecycle Management, Object Locking, Bucket Notifications, and Site Replication. (I showed how to set up Lifecycle Management and Object Locking using code in my post, Object Management for AI/ML.) If your application is setting up buckets programmatically and you need these features, then the MinIO SDK is a good choice. However, MinIO is S3 compliant, and you can connect to MinIO using any SDK that implements S3.
Another popular SDK for S3 access is Amazon’s S3 Client, which is a part of their botocore library - a low-level interface to many services on AWS. This library also works with MinIO and it provides access to all the enterprise features I previously mentioned. If you are considering repatriating an application and its data from AWS to MinIO in your on-prem data center, then you will not have to change any code. Change the URL, access key and secret key in your configuration, and you are good to go.
Yet a third option is the S3fs library. It does not provide access to enterprise features like the MinIO SDK and the S3 Client, but it is easy to use, and many other libraries and tools, like PyArrow and MLFlow, use its classes to set up an S3 data source.
In this post, I’ll use the S3fs Python library to interact with MinIO. To make things interesting, I’ll create a mini Data Lake, populate it with market data and create a ticker plot for those who wish to analyze stock market trends.
All the code shown in this post can be found here.
Installing the Needed Libraries
In addition to the s3fs library, we will need the Yahoo Finance library for downloading historical market data. I am also going to use Seaborn and Matplotlib for the ticker chart. These four libraries can be installed using the commands below.
Downloading Market Data
Over the past decade, market watchers have gotten into the habit of inventing new terms to refer to the hottest stocks. In 2013 Jim Cramer coined the term FANG - an acronym that refers to Facebook, Amazon, Netflix and Google. In 2017, investors started including Apple in this group, and the acronym became FAANG. When Facebook changed its name to Meta and Google rebranded to Alphabet, the acronym further evolved to MAMAA.
Now, in the year 2024, we have a new label: The Magnificent Seven. The Magnificent Seven are composed of Apple, Amazon, Alphabet, Meta, Microsoft, Nvidia, and Tesla. Let’s use the Yahoo Finance library to download market data for the Magnificent Seven for the entire year of 2023.
If successful, the output will be:
Setting up an S3 Connection
The first thing we need to do is create an S3FileSystem object. All the methods we need to interact with an S3 data source are hanging off of this object. The code below will get MinIO’s endpoint, access key and secret key from environment variables and create an S3FileSystem object.
Creating a Bucket
Once we have an S3FileSystem object, we can use it to create a bucket. The makedir() function will do just that. The code below first checks to see if a bucket exists before creating it. The makedir() function has an exist_ok parameter which you would think would allow the makedir to complete successfully if the bucket already exists. Unfortunately, I have found this not to be the case. This function will throw an exception if the bucket already exists, regardless of how this parameter is set. For this reason, it is better to explicitly check for the existence of buckets and only call makedir() if the bucket does not exist.
Uploading Market Data
To upload objects to our newly created bucket, we will use s3fs’ put_file() function. This function will upload a single file to a destination within your S3 object store, which in this case is MinIO. It takes a local source file and a remote path as parameters.
S3fs also provides a put() function which will upload the entire contents of a local directly to a specified path. It even has a recursive switch if your local directory has subfolders.
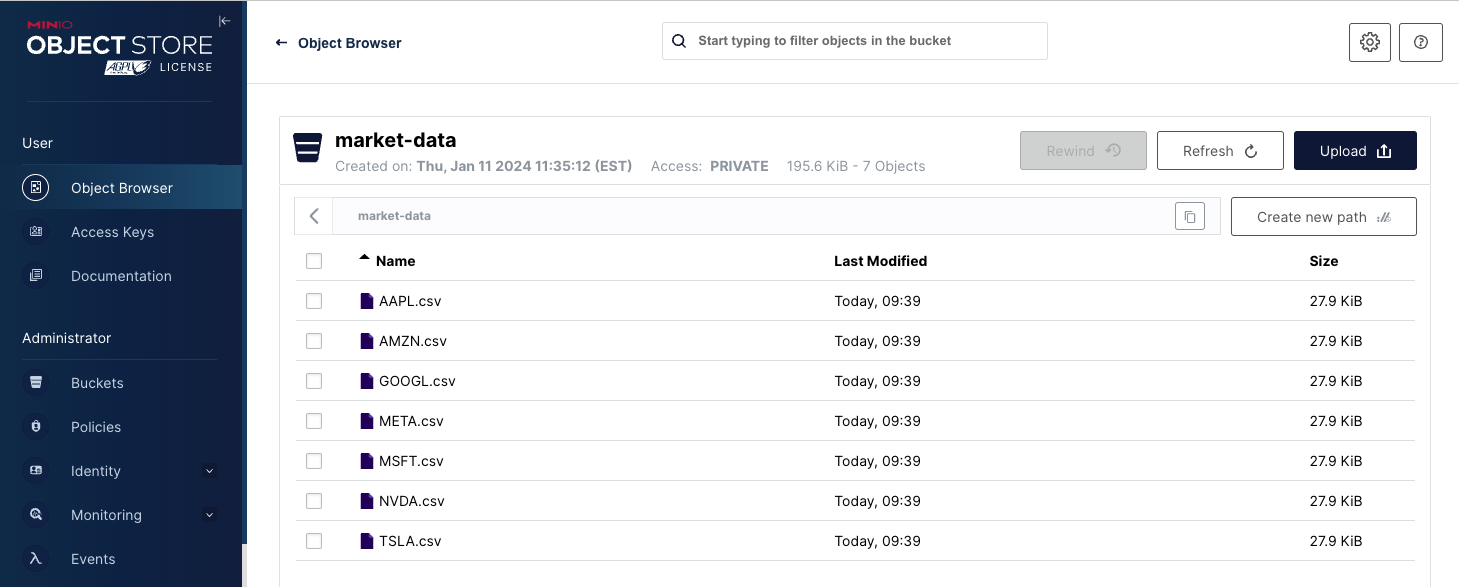
Once the code above completes your MinIO bucket will look like the screenshot below.
Listing Objects
Listing objects in a bucket is straightforward. The s3fs object has an ls() method that takes a remote location as a parameter. This is shown below.
When you call the ls() method with the detail parameter set to False then the return value will be a simple Python list with full path references for all objects in the path. Use this flavor of ls() when you need a list to loop through. A list of the Magnificent Seven objects is shown below.
If you need more details returned from this function, then set the detail parameter to True. Sample output showing details is shown below. (Truncated for brevity.)
Pandas Integration
As stated previously, many third-party libraries use s3fs’ S3FileSystem class to interact with an S3-compliant object store. The code below shows how to use Pandas to read an object from MinIO into a Pandas DataFrame.
The output:
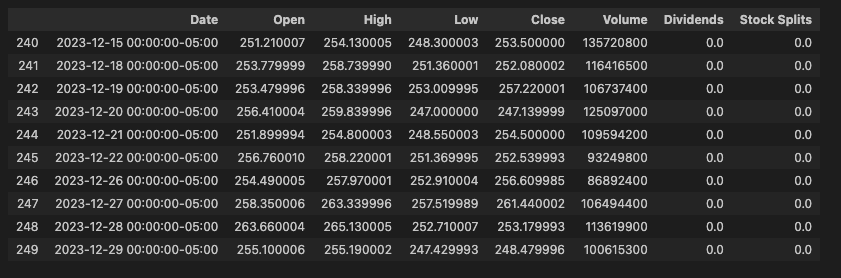
The code above did not need the file system at all to get data from MinIO into a Pandas DataFrame. This is a non-trivial feature for data scientists who need to create datasets from raw data. It is also a powerful feature in the hands of Quants, as Pandas is built on NumPy, which allows for the creation of mathematical algorithms to identify trading opportunities.
PyArrow is another popular library that utilizes s3fs for S3 access to object stores. Consider using PyArrow’s S3 interface if you are dealing with large objects.
Plot Market Data
Let’s have one last bit of fun before wrapping up. What I want to do now is pull all our market data from MinIO and load it into one DataFrame. This is done below using Panda’s concat function. Notice that I also have to add a ticker column.
Output:
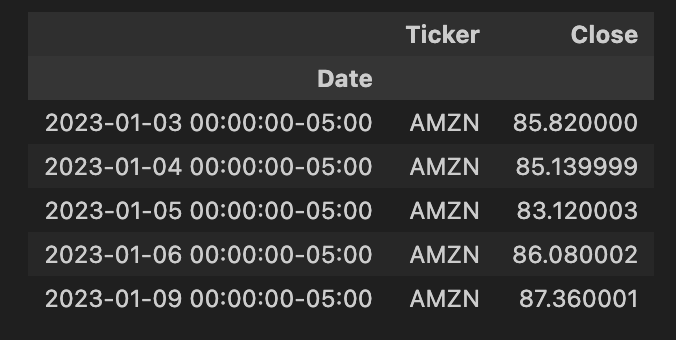
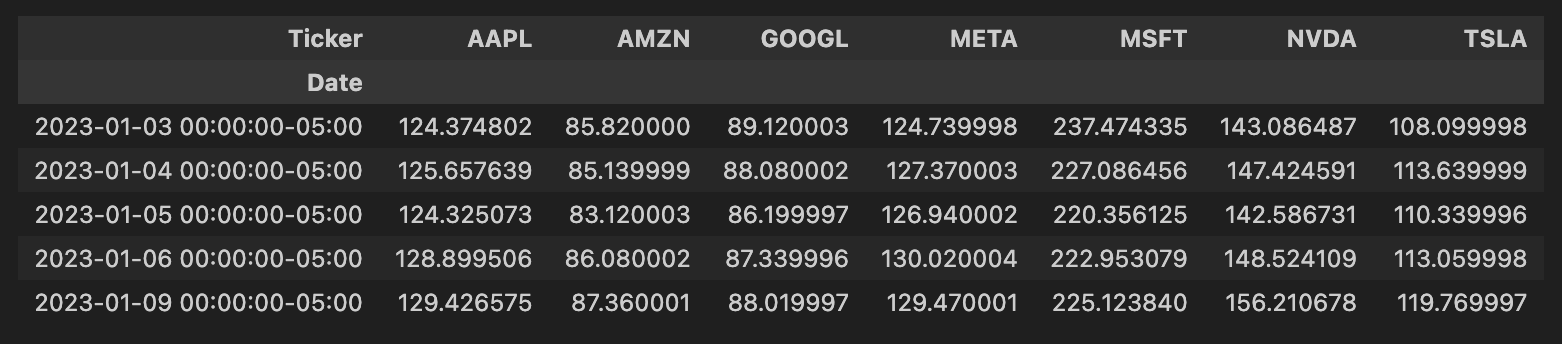
Next, we need to pivot the data on the ticker value.
Our pivoted data now looks like the screenshot below.
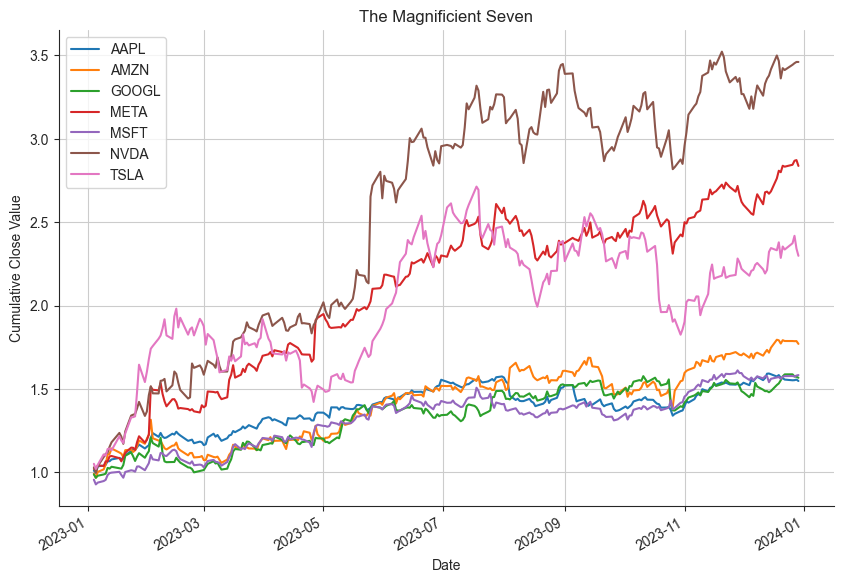
Now we can plot the Magnificient Seven using the code below.
Summary
In this post, we had a little fun with MinIO and the s3fs library. We downloaded some market data, uploaded it to MinIO using the s3fs library, and then integrated the data into Pandas - again using MinIO’s S3 interface. Finally, we visualized our data using Matplotlib and Seaborn.
Next Steps
If you have been following our blog, then you know that we like Modern Datalakes (also known as Data Lakehouses) as much as we like Data Lakes. A Modern Datalake is a Data Warehouse and a Data Lake in one offering. This is made possible by Open Table Formats (OTFs) such as Iceberg, Hudi and Deltalake. A Modern Datalake is built upon object storage and allows for direct integration with a Data Lake while at the same time providing a processing engine capable of advanced data manipulation via SQL. If you liked what you read in this post and want to take it a step further, then consider building a Modern Data Lake. A couple of months ago, I showed how in this post: Building a Data Lakehouse using Apache Iceberg and MinIO.
Download MinIO today and learn just how easy it is to build a data lakehouse. If you have any questions be sure to reach out to us on Slack!






