AI/ML Continuous Integration and Continuous Delivery Foundations

Have you ever wondered how the big dogs with hundreds of apps and millions of users manage their Continuous Integration (Builds) and Continuous Delivery (Deployments) workflows? We wrote a fair bit of code in some of our previous blogs while writing a kafka consumer, observing traces using Jaeger, and collecting metrics using OpenTelemetry. Wouldn’t it be cool if we could take one of these apps along with MinIO and bundle them together and deploy?
We’ll discuss how to deploy MinIO in a distributed setup that will allow us to test it in our local environment, further validate in a development environment, and add monitoring and altering before finally taking it to production cloud environments.
If you are an organization that deploys once a week, that means each deployment is probably a spectacle where you need to have deployment engineers whose sole purpose is to ensure deployments go smoothly. Think of deployment pipelines like mathematics; if you do not have daily practice even a teacher in the subject would forget how it works. This is because with infrequent deployments it’s difficult to predict and fix bugs. When deployments do not go as planned, every engineer on the team needs to know how to roll back the new version, and redeploy the old version.
On the other hand, organizations that deploy several times a day with multiple engineers’ commits in a single release do not feel the same ‘CI/CD fatigue’ as once-a-week pipelines do. They do not need deployment engineers because an existing engineer gets assigned this task when deployments happen, without assigning a whole role. But as I mentioned earlier, not all deployments will go as planned because there could be bugs or security vulnerabilities that might be caught after deployment which now any engineer on the team can roll back.
In this blog post we’ll go into some of the concepts around CI/CD and how you can apply it for deploying a MinIO cluster in a distributed setup along with your own applications by building them from upstream sources all the way to deploying applications on bare metal, GCP, AWS, and even Kubernetes in a standardized way to multiple clouds. With what you learn here your pipeline will have the potential to build thousands of artifacts. We’ll not only use open source tools wherever possible but also industry standard workflows to achieve this.
Related: What is a CI/CD pipeline?
Concepts
Before we dive into the workflows and pipelines let’s talk about some important concepts and terminology.
Artifact
An artifact is a versioned bundle of the code base that could take the form of a Docker image, Amazon Machine Image, VMDK or a simple ISO. In some cases it could also be RubyGems, Python PIP packages, and/or NVM packages, among many others. A bundle can be a version that is currently deployed, a deployment that was made in the past, or a future deployment that has yet to be released.
Artifact Repository
After the artifacts are built they need to be consumed in a way such that they are version-controlled. We want to be able to upload different versions of the same codebase because we don’t want to remove the artifact being used in production in case we need to redeploy or roll back after deploying a new version. MinIO can be a drop-in replacement for any repo that supports AWS S3 SDK and APIs This is also known as an Artifact Registry; the terms are interchangeable, as you’ll see below.
Continuous Integration
I like to think of continuous integration as ‘continuous build’. As you commit your code changes you want to build artifacts as quickly as you can so you can test and fix bugs in a timely manner before the code reaches production.
- Engineers commit code to a git repository.
- Automation tools pick the codebase and test it extensively.
- The artifacts are built, versioned, and uploaded to an artifact repository.
Continuous Delivery
Once the artifacts are built they need to be delivered or ‘continuously deployed’ to appropriate dev environments where they can be tested prior to getting ready to deploy to production. This is where the engineers get confidence in not just the code base but how the code behaves with the rest of the infrastructure.
- Deploy the build artifact to the dev environment.
- Do integration and stress testing against other components like databases and storage.
- Deploy the tested codebase to production.
Pipelines
From when they are built, tested, and deployed to various environments, artifacts need to be structured as reusable workflows that automate the workflow end to end. These CI/CD workflows are also called pipelines. Pipelines are usually divided into several steps so that engineers gain confidence in the CI/CD process as they go through each step. The more confidence they get in the process, the more testing they can do on the code base and the final deployment into production will be that much smoother. Some of the tools that are available in the space are:
- GitHub Actions
- GitLab CI/CD
- Jenkins (OG)
- AWS CodePipeline
- GCP Cloud Build
- CircleCI
SLA Inversion
The build and deploy pipelines are dependent on various pieces of infrastructure that would in turn determine the SLA of the pipeline. For example when building an artifact, the availability of code repositories, upstream repos, and/or DNS determines SLA for the build pipeline while GCP, AWS, and/or VMware availability give us SLA for deployment pipeline. You can read more about SLA inversion here.
Infrastructure as Code
Infrastructure as Code (IaC) is an executable documentation. It lays out instructions which are read by an app to bring up a resource (bare metal, AWS, GCP) without actually using any GUI or CLI. Any change in the infrastructure needs to be codified and tested. Unit, integration, and acceptance tests are paramount when writing code for infrastructure. You can read more about IaC here.
Provisioners
Provisioners pull artifacts from the Registry and use the metadata to provision resources. Using infrastructure as code will allow you to codify and version control the code base.
Bake N’ Fry
- Baking is an artifact purpose-built for a specific application.
- Frying is a generic artifact that could be used across many applications.
This is best illustrated using an example. An engineer had to test MinIO locally on a machine. Every time they were spinning up the VM it would install MinIO packages and pull dependencies on the fly. This is Frying. It used to take around seven minutes for every new VM to spin up and this was getting quite tedious. To get around this we “baked” a new VM image with all the dependencies pulled and installed MinIO dependencies during the build time. After baking the new VM which now has all the dependencies preinstalled had MinIO cluster spun up in about seven seconds. As an added benefit it was stable and reusable. If you notice we said Baking and Frying, not versus. You don’t have to choose between one or the other because an image can be partially baked and fried the rest, pick what works best for the application and tune accordingly. Generally the more deeply you bake images the more stable they are compared to their fried counterparts.
Twelve-Factor App
There are many different ways an app can be designed to work with various parts of the CI/CD pipeline. One of them is Twelve Factor App design. Some of the key things to consider are:
- Use declarative formats for setup automation, to minimize time and cost for new developers joining the project
- Have a clean contract with the underlying operating system, offering maximum portability between execution environments
- App is suitable for deployment on modern cloud platforms, obviating the need for servers and systems administration
- Minimize divergence between development and production, enabling continuous deployment for maximum agility
- And can scale up without significant changes to tooling, architecture, or development practices.
Related: What is Infrastructure as Code (IaC)?
Tools
So far we’ve discussed a bunch of concepts but how does the rubber meet the road? Let's talk briefly about some of the tools that you can use to power your pipelines. There are tools ranging from the Open Source that you can install on-prem to SaaS that you can use with minimal overhead. The goal of this pipeline is to use as few wrapper scripts as possible to glue them together so there is no homegrown solution to maintain or onboard people on.
Packer
Packer lets you define the steps for building the artifact in the form of version-controlled infrastructure as code. Packer pulls the Docker image, AWS machine image, or ISO directly from upstream and builds a custom artifact which can then be uploaded to various artifact repositories.
Vagrant
Once you build the artifact you need a way to test it locally on your laptop. Vagrant allows you to deploy your custom artifacts from the registry either as a virtual machine or as a Docker image. This way you prevent using resources in the cloud and keep development locally on your laptop.
Provisioners
Provisioners are basically API-driven cloud agnostic tools that can generally only interact with resources which have APIs to launch infrastructure. The provisioners are written in a declarative manner in either JSON or YAML that allows us to provision resources on AWS, GCP, or bare metal as long as there are APIs to handle the requests. It's declarative because the code defines the end result of the infrastructure. You don’t necessarily care how it gets to that state nor should you need to. Some of the common provisioning tools are:
- Terraform
- Pulumi
- AWS Cloudformation
- GCP Deployment Manager
Service Discovery and KV Store
While most of the settings can be configured during the build process, some things like hostnames or database settings based on data center or region can only be configured after the artifact has been built during the deployment phase. We also need these services to be discoverable so configuration generation and service dependencies can be automatically generated. Some of the tools available in this space are
- etcd
- Consul
Vault
Vault uses the Consul key/value store as a backend to store secrets. These cannot be hardcoded during the build process for security and other reasons. In fact both Consul and Vault servers can run on the same instance.
Artifact Repositories
There are many more out there but the below are some of the most popular ones
- Docker Hub
- Jfrog Artifactory
- Harbor
- Quay
- AWS Elastic Container Registry (ECR)
- GCP Container Registry (GCR)
MinIO
MinIO is very versatile when it comes to being integrated with the rest of the pipeline. MinIO can act as the S3 backend for Harbor to store the artifacts, and in fact MinIO can act as the S3 backend for Artifactory as well.
Moreover when you use Terraform instead of storing the state on a local disk you can provision a MinIO cluster in a snap with Vagrant and store Terraform state data in there which allows for Terraform state to be accessed by multiple users. Of course in production please make sure you run this in a distributed setup using Terraform.
Pipeline
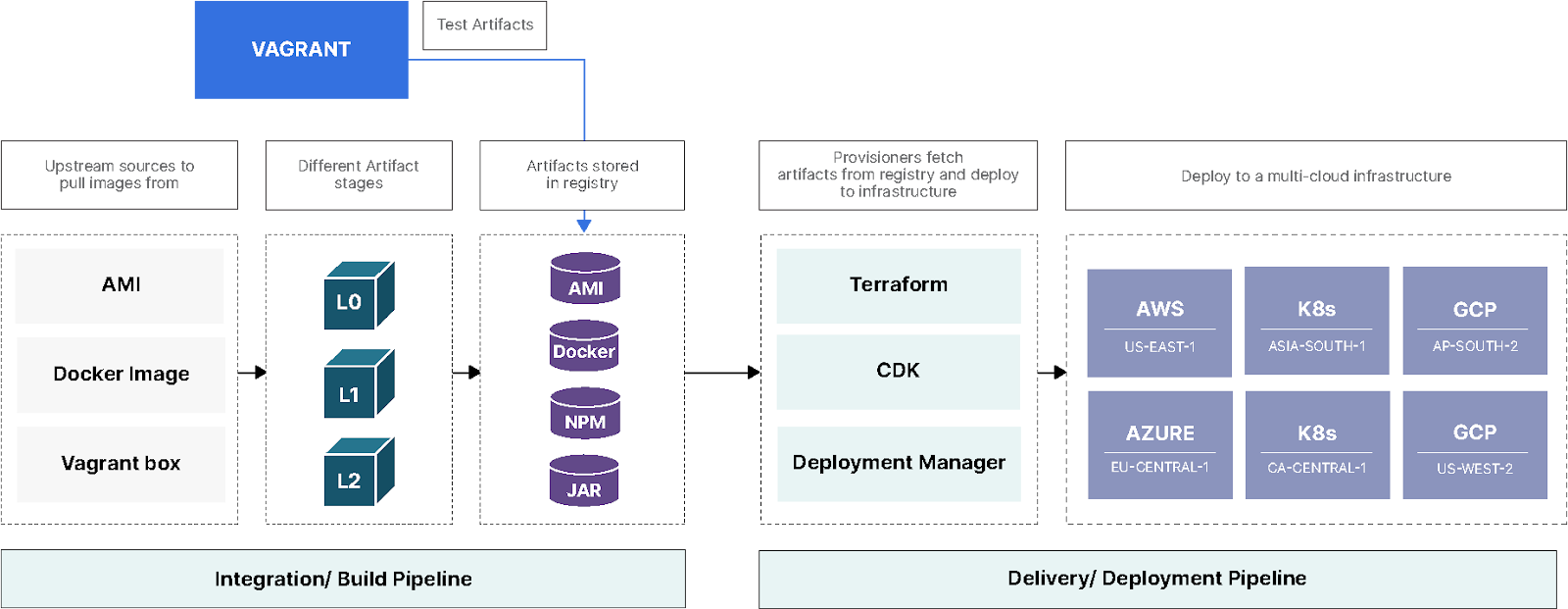
The workflow below highlights the build pipeline portion of the process. As you can see Base/L1 can be reused to create App/L2 artifacts. Other than the initial source, Upstream vs Registry, the workflow remains the same.
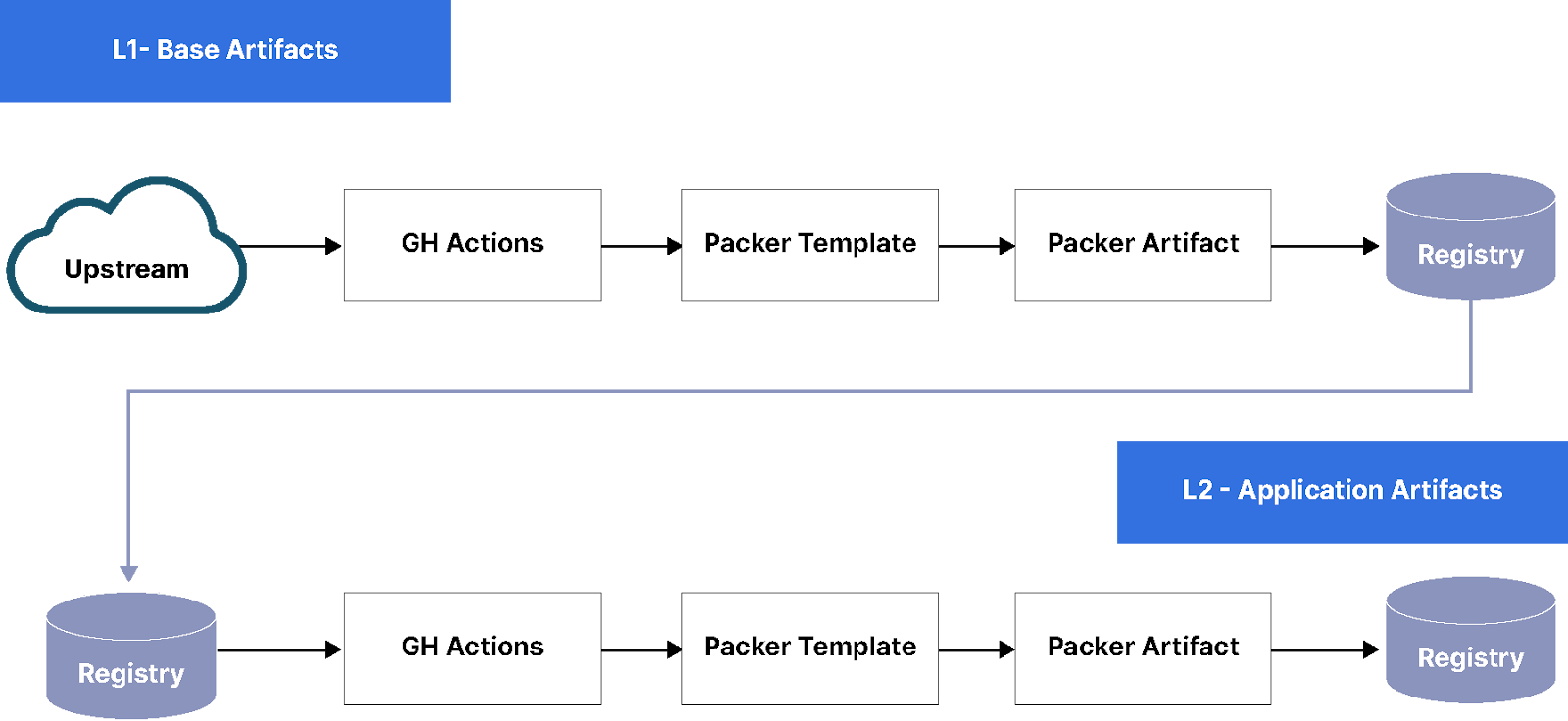
Layer 0 (L0), Foundation Artifact: The Foundation is ISOs, Docker images, AMIs released by Canonical, RedHat, Docker, and even AWS and GCP. These are bare bones standard Linux distributions that can be pulled from any public repo. Examples would be Ubuntu 20.04 and 22.04 or base minimal Python Docker image.
Layer 1 (L1), Base Artifact: This is where the org-specific operating system with base packages, monitoring, and security best practices installed. These are shared across all the apps. Examples would be Metrics, Monitoring, and Logging. We should not have more than a handful of these; these artifacts are usually built and maintained by the Infrastructure team.
Layer 2 (L2), Application Artifact: Configuration, Packages, GPU drivers specific to an app. Examples could be data science, web, redis, MinIO, Memcache, or similar which are app specific . Base artifacts (L1) can be reused to generate new MinIO server artifacts. Don’t be too surprised if you end up with a lot of L2 artifacts. These artifacts could potentially be created by developers as well so they can test out their Docker container with Vagrant before being used in production.
Note: Generally the ratio between L0 and L1 should be 1:1 and app artifacts (L2) should not be reused to bake newer artifacts (L3 or higher) since the dependency chain would become unwieldy.
For another example, let’s assume in one of the MinIO releases there is a security vulnerability. If an L1 artifact is vulnerable to an exploit, any L2 artifact created from that is vulnerable as well. Assume you have an L3 artifact, that’s another layer that also has to be patched. This might not be a problem if you have only a handful of artifacts but this pipeline has the potential to generate thousands of artifacts: try figuring out that dependency chain! Another example would be kernel security patches. If L1 is vulnerable, any L2 artifact built from that is vulnerable as well and requires patching.
Infrastructure goals are different from application goals. From an infrastructure perspective, all environments, even development, are considered “production.” Why? Well I’m glad you asked. If MinIO in development or stage environments goes down, it ultimately affects developers so they are considered “production” as far as devops is concerned. At the same time MinIO needs to be tested before being deployed into production and we cannot directly deploy to an environment used by developers either.
We achieve this by separating our MinIO clusters into distinct environments.
Infrastructure environments
- Sandbox
- Canary
- Live
Application environments
- Development
- Staging
- QA
- Production
- Ops (common services used by all app environments)
Each infrastructure environment could have all (or some) application environments; the hierarchy would be as follows:
Sandbox
- Development
- Staging
Canary
- Development
- Staging
- QA
- Production
- Ops
Live
- Development
- Staging
- QA
- Production
- Ops
This way we can actually apply production changes in a canary environment before applying to the live environment.
Cattle vs Unicorns
Resources should be named and designed more for cattle than unicorns. If we want to start treating resources like cattle the name should give just enough info so you know where MinIO is running but at the same time as random as possible so there are no conflicts. The advantage of doing this is you avoid having snowflakes that are unique and that makes automation difficult because there is no pattern.
One suggestion would be to use the following format:
ROLE-UUID.APP-ENV.INFRA-ENV.REGION.fqdn.com
Examples:
minio-storage-f9o4hs83.dev.canary.ap-south-1.fqdn.combase-web-l0df54h7.prd.live.us-east-1.fqdn.com
Final Thoughts
Let’s recap what we discussed in this post. We dove deep into some CI/CD concepts, the workflows involved, and some of the tools we could use to power the pipelines. We showed you the different ways MinIO can integrate in both the build process and also the deployment process.
What we discussed here is just the tip of the iceberg and we would encourage you to implement your own version of this. In future blogs we’ll show you how this looks when you implement with the tools we discussed to give you a holistic end-to-end view of the pipeline.
In fact if you do end up implementing your own version send us a note on Slack!






