Distributed Data Processing with Ray Data and MinIO

Introduction
Distributed data processing is a key component of an efficient end-to-end distributed machine-learning training pipeline. This is true if you are building a basic neural network for statistical predictions where distributed training could mean each experiment runs in 10 minutes vs. an hour. It is also true if you are training or fine-tuning a Large Language Model (LLM) where distributed training will save you days. In this post, I will show you how to use Ray Data to distribute the data processing within your machine learning pipeline. Distributing data processing will not only improve performance, but it is also a good option when you are training a model with data that cannot fit into the memory of a single machine.
Most engineers (like myself) foray into distributed training by first distributing the compute needed to train the model itself. This is a perfectly fine way to start - especially if you have existing data access and processing code that you would like to reuse as is. With this approach, the machine-learning pipeline, with distributed training only, will look like the diagram below.
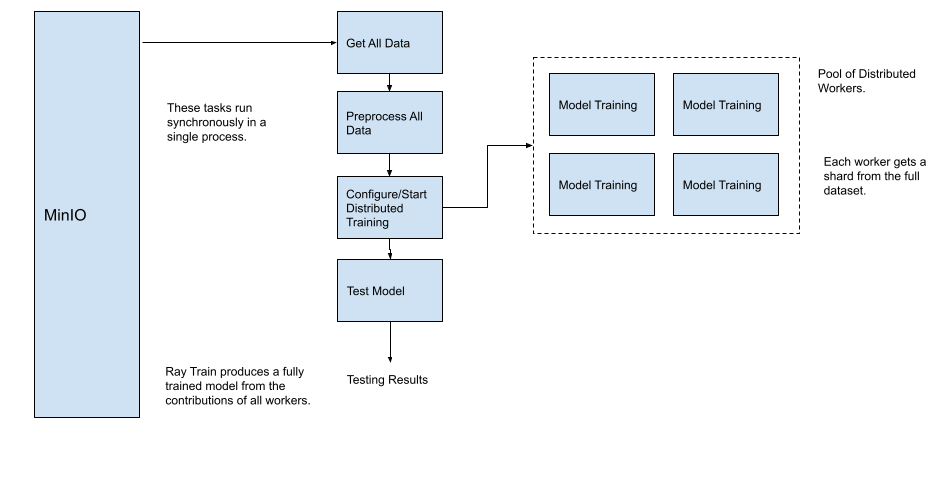
However, what if the data you want to train your model with cannot fit into memory? Even if all your data can fit into memory, there are efficiencies to be gained by distributing the loading and processing of the data. For example, in the diagram above, it could take a significant amount of time for all the data to get loaded into memory and then preprocessed by a single thread of execution. A better approach would be to find a way to have each worker load and preprocess their share (shard) of the data. The controller node would only have to retrieve a list of objects to be shared and sent to the worker nodes. This approach is illustrated below.
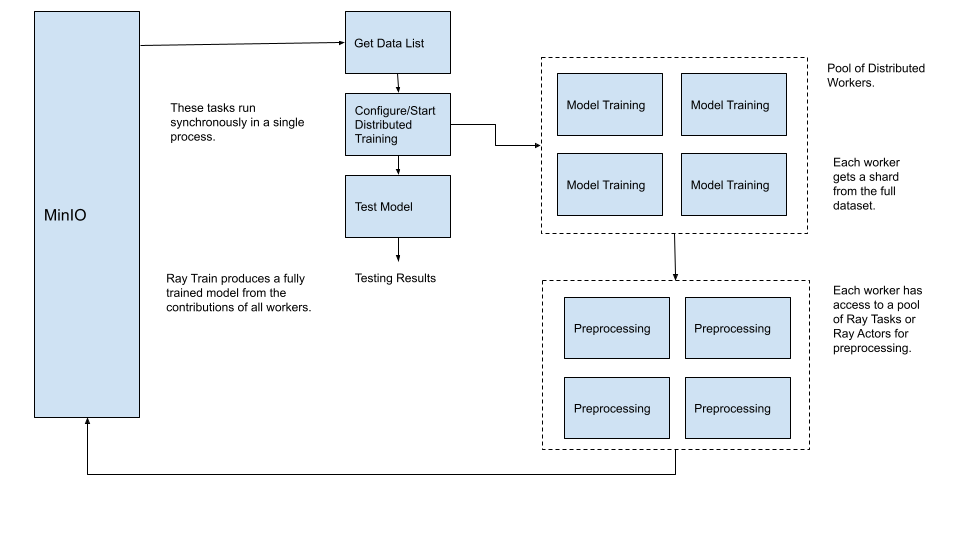
It is important to note in the diagram above that the controller node only retrieves a list of pointers into an object store, not the actual data in all the objects. When each worker receives their list of object pointers, they will have to retrieve and preprocess the object. With a setup like this, the heavy lifting done within the pipeline is moved to scalable resources. MinIO is also a scalable resource since it is a distributed object store that processes object requests in parallel at high speed. In the diagram above, I show only four worker processes, but there could be hundreds. Using a low-end storage solution in this pipeline would be a mistake.
Let’s dig into what we will build in this post.
What We Will Build
In this post, I will show how to build and test the distributed data processing shown in the diagram from the previous section. Specifically, I’ll show how to get a list of object pointers from MinIO and set up the data for distributed processing. To do this, I will use Ray Data and MinIO. Ray Data is a data processing library for distributed machine learning workloads. In my next post, I will show how to use what we built in this post to complete the implementation of our fully distributed diagram by using Ray Train with MinIO.
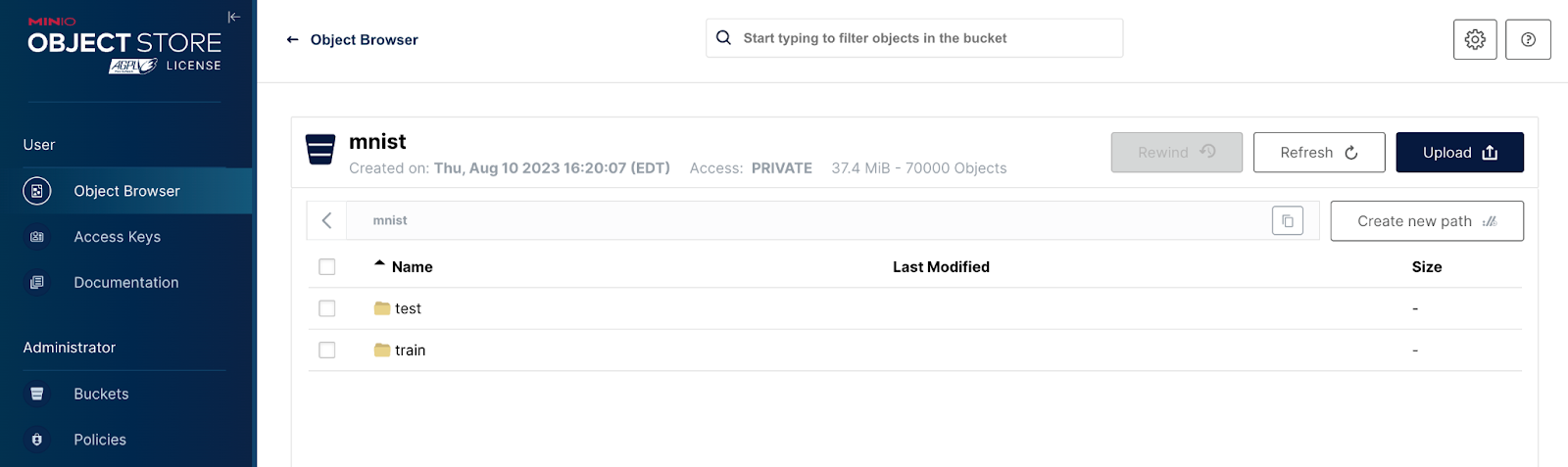
The dataset I will use for this post is the Modified National Institute of Standards and Technology (MNIST) dataset. It is a collection of handwritten digits. It is one of the most well-known datasets in the ML community, and it is commonly used as an introduction to building neural networks. Each image is a 28 x 28 pixel image of a handwritten number between 0 and 9. There are 60,000 images for training and 10,000 for testing. The code download for this post contains a script that can be used to upload these images to MinIO. Once uploaded, there will be an ‘mnist’ bucket with test images and training images as shown below.
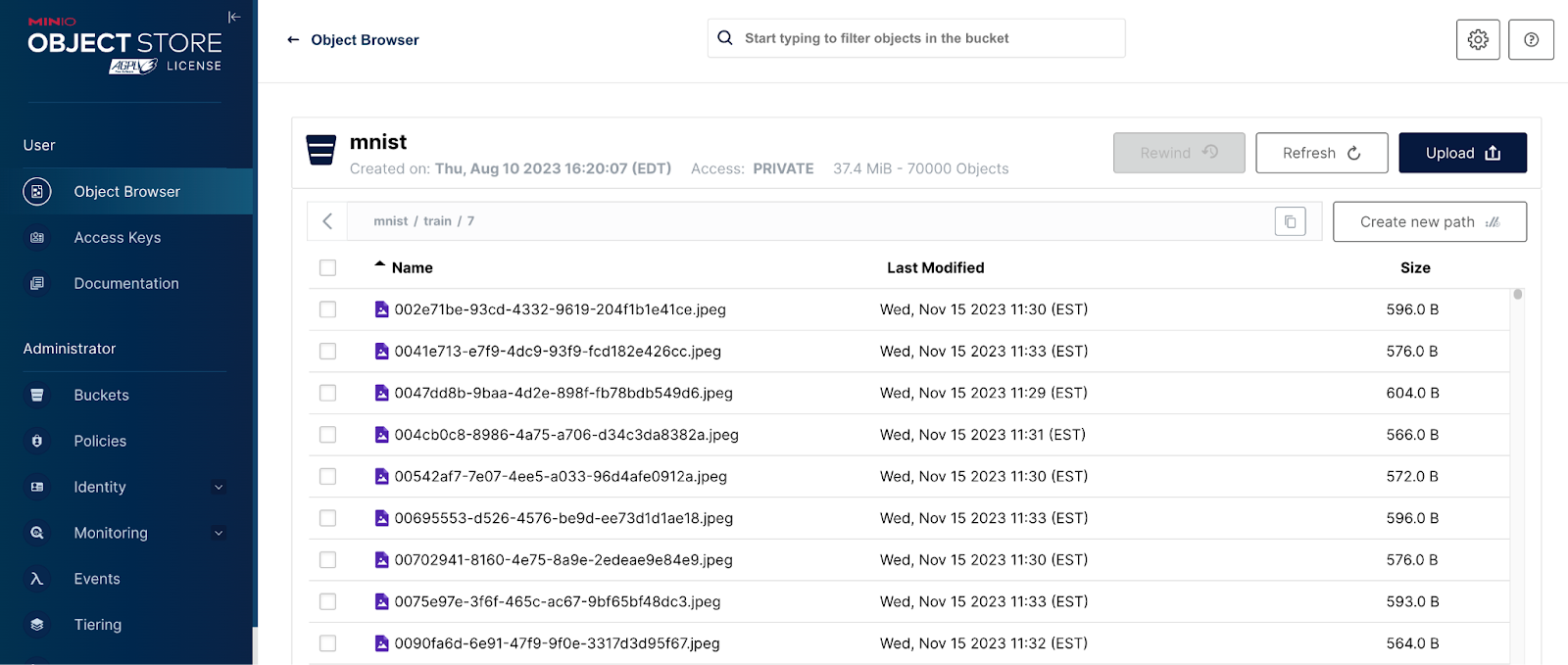
Drilling into one of these paths gets us to the objects themselves. See the screenshot below. The path to the object contains its label and my script generates a unique GUID to name each object. Since the upload script generates unique names every time it is run, you can run it multiple times - every run will add 60,000 new training objects and 10,000 new test objects. This is a perfect way to create a massive dataset for running benchmarks against your AI infrastructure.
Now that we understand our data and how it is stored, let’s start by creating a function that retrieves a list of objects from the MinIO bucket shown above.
Getting a List of Objects
Retrieving a list of objects from MinIO is done via a straightforward use of the MinIO SDK. Since our ultimate goal is to train a model we need more than just a simple list of objects. We need the list broken out by training set and test set. Also, for each set, we need the features and labels. The Pythonic way of doing this is to use the following variables: X_train, y_train, X_test, y_test. To do this, I wrote three functions described below. The code for these functions is also below. In my code download, these functions can be found in the data_utilities.py module.
- get_train_test_data - Top-level function that coordinates calls to the other functions. It will also apply a smoke_test_size if passed.
- get_object_list - Returns a single list of all objects in a bucket.
- split_train_test - Creates the X_train, y_train, X_test, y_test variables based on the objects path.
The snippet below shows how to call the get_train_test_data function. Notice that I use environment variables to pass MinIO credentials to my helper functions.
The output is shown below.
The size of our data is as expected. The original dataset has 60,000 training samples and 10,000 test samples. So, no samples have gotten lost between upload and list retrieval. I also like to keep track of how long tasks take. On my Macbook Pro with a local instance of MinIO running inside of Docker, this task took 21 seconds. Statistics like this will help locate bottlenecks once the entire pipeline is built.
Let’s inspect a single sample from our training set to understand exactly what we have. The code below will look at the first object pointer in our training set and its corresponding label.
The output:
This sample points to an image of the number zero. The image itself is not in memory yet, only a pointer to it in MinIO. We will use the pointers in X_train to retrieve the images during distributed data processing.
Setting up Distributed Data
So far, all our code has used plain old Python objects for holding data. To enable our data for distributed data processing, we need to load this data into a Ray dataset object. This is done using the snippet below.
The output of this snippet will be:
This is an internal Ray Data class that you will never instantiate directly. Also, notice the parallelism parameter in the from_items function. This setting determines how many parallel processes will be used for all transformations on the Ray data object. In the snippet above, I set the parallelism to 5. However, you should not set this parameter for a production application. It is best to allow Ray Data to determine the optimal value. Ray will determine the optimal value based on the number of CPUs on your device and the size of the data.
Let’s inspect a few rows of data to see how it is shaped.
You will get output that looks like this:
We now have everything in a Ray materialized dataset capable of parallel (distributed) processing. The next step is to write a processing function and map it to our materialized dataset.
Creating a Processing Function
We need to do a few things to prepare our dataset for training. First, we must retrieve the object from MinIO using the object pointer. Second, the image must be converted to numbers that reside in a Pytorch tensor. Finally, the values in each tensor (one tensor per image) must be normalized because models prefer small numbers. The function below will do all these things for our MNIST dataset by batch.
A few comments regarding the code above: it expects a batch of training samples to be sent, and one connection to MinIO is opened per batch. Also, Ray Data will run this function as a Ray Task, and multiple instances will run simultaneously. The number of instances is dictated by the value of the parallelism parameter in the ray.data.from_items function when the MaterializedDataSet was first created. (For us it is 5.) Finally, I am using a custom Python logger in this function. A custom logger that sends your messages to a file of your choice is invaluable when troubleshooting tasks that run in parallel. Below is how I set up the logger. It will send my messages to both stdout and a file of my choice. The messages sent to stdout will be mixed in with Ray’s messages, but sending log messages to a file isolates messages produced by my code. I also added the process id to the loggers formatter so that the process id will automatically get added to each message.
We now need to map our processing function to our data set. This is done with one line of code.
The map_batches function merely associates our function to the dataset. Ray Data performs lazy transformation, meaning our function will get called when we loop through our dataset by batch. Let’s do that next as a test of everything we have put together.
In this section, I showed how to create a function running as a Ray Task. Creating a Ray Actor that does the same thing is also possible. Additionally, if you wish to iterate over rows instead of batches, that is also an option. The Ray User Guides have code snippets showing these options. I also implemented a Ray Actor in the code sample for this post.
Testing Distributed Data Processing
Since we are not ready to use our dataset for training (I will do that in my next post), we will write some test code to invoke our processing function. This is done below using the iter_torch_batches method of our training data.
After this code runs you will see the following output.
Also, below is an excerpt from the beginning of my log file after running the loop above. The first column is the process id followed by a timestamp. As you can see, five processes are started and run in parallel.
The optimal value for parallelism will vary by system and cluster - so enjoy experimenting.
Summary and Next Steps
In this post, we took the first step in building a fully distributed end-to-end machine learning pipeline. Specifically, we set up (and tested) a Ray Dataset that can load and preprocess data in a distributed fashion.
The next step is to complete the pipeline by implementing Ray Train workers that use our Ray Dataset for distributed data processing and model training within Ray workers. I will do this in my next post. So, stay tuned in to the MinIO blog.






