Distributed Training with Ray Train and MinIO

Most machine learning projects start off as a single-threaded proof of concept where each task is completed before the next task can begin. The single-threaded ML pipeline depicted below is an example.

However, at some point, you will outgrow the pipeline shown above. This may be caused by datasets that no longer fit into the memory of a single process. You will also outgrow this pipeline when your model becomes complex and experiments take hours or even days to complete. To solve these problems, you can distribute the work across multiple processes and add parallelisms. To fully distribute the pipeline above requires two modifications:
1. Distribute data processing
2. Distribute model training.
Data Processing (or data preprocessing as it is often called in the machine learning world) in a single-threaded pipeline is usually done by loading the entire dataset into memory and transforming it before handing the data to the model for training. However, that should change once you wish to take advantage of distributed training techniques. Data preprocessing can be done incrementally from within the training loop. In my last post on Ray Data, I showed how to distribute data preprocessing using Ray datasets that can be mapped to a preprocessing task or actor. Specifically, I showed how to create a Ray dataset and map it to a processing task. We then tested this dataset by iterating through it and watching the preprocessing task get executed for each iteration. Additionally, I showed how to use MinIO as the source of a dataset too large to be loaded entirely into memory. This required querying MinIO for a list of objects for training and coding object retrieval into our preprocessing task. If you have not read this post, give it a quick read now.
In this post I will show how to implement the second modification needed to fully distribute an ML training pipeline. I will show how to distribute model training and use mapped datasets within a training loop. When running training functions that take a long time to complete, it is a good idea to checkpoint your model after each epoch. Checkpointing is also how you retrieve your final fully trained model. This post will show you how to checkpoint your model to MinIO.
A fully functioning sample containing all the code presented in this post can be found here.
Visualizing the Distributed ML Pipeline
When implementing a distributed pipeline, it helps to visualize what will be built. The diagram below is a visualization of the complete distributed pipeline, including distributed preprocessing, which was covered in my previous post. Refer to this diagram as I go through the coding tasks necessary to distribute model training.
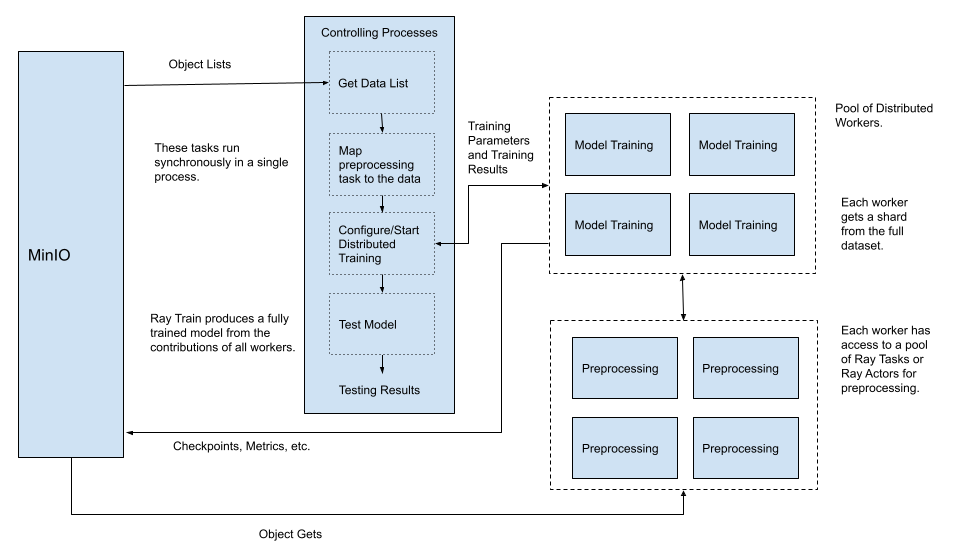
The diagram above may look odd as the tasks (or actors) used for preprocessing are called from the workers responsible for distributed training. However, remember my brief description above - preprocessing tasks are mapped to datasets and the tasks are invoked as we iterate over the dataset from within our training loop.
Before we start coding, let’s get a better understanding of Ray Workers.
Ray Workers
A Ray Worker is a process that executes a Python function containing your training logic. This function typically contains setup code for your loss function and optimizer, followed by an epoch loop that trains your model. Ray Train distributes model training by creating multiple workers across a cluster. In a production environment, your cluster could be a Kubernetes cluster. On a development machine; Ray Train will create a process for each worker. The number of workers determines the degree of parallelism and is configurable.
The first coding task is to create a training function capable of running in a Ray Worker.
Create a Distributed Training Function
A training function using Ray Train (and Ray Data) is shown below. I have highlighted the use of Ray functions that facilitate distributed training. Surprisingly, this requires minimal code changes as compared to a function implemented to run in a single thread.
The first use of the ray framework in this function is to prepare the model for distributed training by modifying it with the ray.train.torch.prepare_model() function. This function creates a new model capable of synchronizing gradients and parameters with models created the same way in other workers.
Next, the function above gets a shard of data using the train.get_dataset_shard() function. The more workers you use the smaller this shard will be - and the faster your training will run. Finally, the iter_torch_batches() method of the dataset shard is used to return batches of Pytorch tensors. If your workers are failing unexpectedly, then try using a smaller batch_size. Out of memory errors are common when running distributed training on a single machine. They can also be caused by using too many workers.
To summarize, each worker executes this training function when launching a distributed training job. Each worker will create a model replica that can synchronize with other workers' models, and each worker will get their own shard of data.
Starting the Distributed Workers
We will use the function below to create a local cluster and configure it with the desired number of workers. Notice that when I initialize Ray I have to tell it to install the MinIO SDK. Ray will automatically install itself and PyTorch. If you are using any other libraries then add them to the pip list. After Ray Train has been initialized, this function retrieves the Ray datasets that I introduced in my previous article.
Setting up distributed training is done with the TorchTrainer class - its constructor is passed the training function we wrote earlier, training parameters, the training dataset, a scaling configuration object, and a run configuration object.
The scaling configuration object (created from the ScaleConfig class) tells Ray Train how many workers we want and if we wish to use GPUs. The run_config parameter determines where Ray Train will send your metrics and checkpoints. I will show how to use run_config to send data to MinIO in a later section.
Once all this information is set up within a TorchTrainer object, you can call its fit() method and Ray Train will create the workers and run your training function within the workers. This method will block until all the workers complete. The returned value will be a dictionary containing metrics from training and a checkpoint.
Let’s discuss metrics and checkpoints in more detail.
Reporting Metrics and Checkpoints
At the bottom of the training function, you will see the code snippet below. Calling train.report() with your metrics and checkpoint is how Ray Train sends this information back to your controlling code from the workers.
This code only creates a checkpoint from the worker with a “world rank” of zero. “World rank” is merely a way to identify the workers. Remember that each worker’s model is synchronized with the other workers as training progresses. Therefore, having each worker serialize the model and return it is a waste of cycles. Models can also get quite large, so unnecessary checkpointing would wast storage.
The data from train.report() will be in the return value of train.fit(). When you print this data out (example below), you will only see information from one of the workers - furthermore, the data will only be the values sent during the last epoch. This makes sense for checkpoints - most of the time, you will only need the final state of the model. However, this is unfortunate with respect to metrics. I like to see my loss values from each epoch to determine if more epochs would improve accuracy or if I have overshot the optimal loss value.
The checkpoint shown in the sample output above is a reference to a model that has been serialized to a temporary directory. Let’s see how we can send checkpoints to MinIO.
Sending Checkpoints to MinIO
A Ray Train run produces a history of reported metrics, checkpoints, and other artifacts. Some of these artifacts are Ray Train logs that could help you track down a problem. By default, this information is saved to a temporary directory. However, you can configure it to be saved to MinIO. This is done via the run_config parameter of the TorchTrainer object shown previously. The function below will generate a run config that will send the information created during a run to MinIO. The storage_path parameter of the train.RunConfig() function is a MinIO bucket.
The snippet below shows how to use this function when creating a TorchTrainer object.
Loading Models from Checkpoints
The final thing we will do is load a trained model from a checkpoint. You will need to do this if you are serving a model in a production environment. Alternatively, you can test the model with test data that the model did not see during training. In the code sample for this post, I test the model against a test set.
Summary
In this post, I completed what I had started in my previous post, where I showed how to use Ray Data to distribute any preprocessing that needs to occur before training your models. I showed how to distribute the training of your models. I also showed how to configure Ray Train to send metrics and checkpoints to MinIO. Finally, I showed how to load a checkpoint so you can test and deploy a model.
The sample code can be used as a template for your distributed training projects by replacing the data access function and the model. Feel free to reach out to us on our general Slack channel or on hello@min.io if you want to discuss further.






