GPU Trends and What It Means to Your AI Infrastructure

Almost a year ago (actually 11 months ago), I wrote about the “Starving GPU Problem” and how the horsepower of Nvidia’s Graphic Processing Units (GPUs) could be so powerful that your network and your storage solution may not be able to keep up - preventing your expensive GPUs from being fully utilized. Well, in those short 11 months, a lot has changed. Nvidia announced a new chip architecture named after David Blackwell, a statistician and mathematician. At the same time, Intel and AMD have made progress with their competitive offerings, which they call accelerators.
At a high level, the problem that adopting GPUs could introduce is a lack of infrastructure balance for compute-intensive workloads. Consider a CPU-based AI infrastructure where everything is running fine. There are no bottlenecks, and all components are at 80% utilization, so you did not over-purchase and have bandwidth for bursts. If compute is upgraded to GPUs, what does that do to your network and storage solution? If one cannot keep up, then your investment in GPUs is wasted.

In this post, I want to discuss what introducing GPUs means to your infrastructure and some things you can do to maximize your investment in GPUs. Let’s start by looking at what is happening with GPUs and Accelerators.
The Current State of GPUs and Accelerators
First, some housekeeping - What is the difference between an Accelerator and a GPU? The short answer is nothing. Intel and AMD have adopted the convention of using the term “GPU” to refer to chips that run on a desktop system to speed up graphics for gamers and video editors. They use the term Accelerator for chips designed for the data center to power machine learning, inference, and other mathematically intensive computations. Nvidia, on the other hand, is sticking with the term “GPU” for all its offerings. In this post, I will use the term “GPU” when referring to these chips in a general sense since it is the most popular term. When referring to Intel and AMD’s specific offerings, I will honor their standards and use the term accelerator.
Let’s look at what Nvidia, Intel, and AMD have been up to for the past 5 years. The table below is organized chronologically and shows the GPUs that have entered the market since June 2019. It also shows a couple of chips from Nvidia that were supposed to be released in late 2024 but have slipped to early 2025. In my previous post on Nvidia’s GPUs, I defined the FLOPs performance metric, what memory means to machine learning pipelines, and the relationship between memory bandwidth and memory. So, if you need a refresher, check that post out before reading on. In this post, I want to make a few additional observations.
Note: Performance metrics shown above are for the Floating Point 16 (FP16) datatype without sparcity.
First, there is a performance trend. The best way to see this trend is to chart the numbers above by designer. The bottom line is that GPUs are getting faster, and the pattern is not showing any signs of slowing.
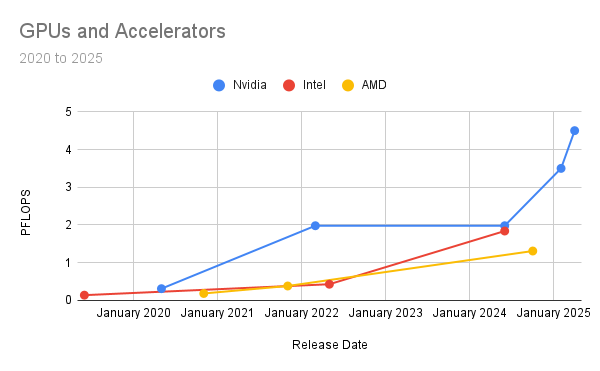
Another observation that can be made from the GPU table above involves a cost-to-performance comparison. For example, the cost of Intel’s Gaudi 3 accelerator is half the price of Nvidia’s H200 GPU, but the performance is roughly the same. So, if you do not need the fastest chip in the industry (which is Nvidia’s B200) and your needs are in the 2 PFLOPs category, you are better off purchasing Gaudi 3. This is a classic strategy for a challenger (Intel) to compete with an incumbent with a performance advantage. The basic idea is to compete on cost and not performance by building something good enough while at the same time providing cost savings for your customers. On the other hand, if you have multiple teams training and fine-tuning models - and your production environment has several LLMs under heavy inference loads, then you may need the best and fastest chip on the market. The most significant benefit of competition, like what we see now with GPUs, is that consumers have options.
GPU Considerations
If you are upgrading GPUs, the chart above can give you a rough idea of the additional stress a faster GPU will put on your infrastructure. For example, if you replace a cluster of aging A100s with B200s (both from Nvidia), the B200s will be 14 times faster (4.5/.312), potentially putting 14 times the load on your infrastructure. The B200 also has 152 GB more memory than the A100, resulting in larger batch sizes or more data per network request.
Adopting GPUs for the first time is trickier because there is no good way to compare the performance of a GPU to a CPU. Consequently, there is no good way to determine the extra load a GPU will put on your network and storage solution. The problem with a theoretical comparison is that GPU performance metrics measure floating-point operations per second. On the other hand, CPU performance is measured in clock cycles per second. This is because CPUs handle multiple instruction sets (each instruction set runs on a different circuit), and the logical operations they manage get broken down into multiple tasks, and a different instruction set may complete each task. The clock acts like a metronome, allowing a logical operation's specific tasks to be precisely coordinated. So, comparing CPUs to GPUs is like comparing RPMs to horsepower when trying to figure out how two automobiles will perform.
You could guess the ratio of different instruction sets your CPU processes to develop an average FLOPS metric for your CPUs, but this would be prone to error. You could also work backward from your training sets and theoretically determine how many floating point operations it takes to run a training set through one epoch. However, this is also based on guesses that could vary greatly. Ultimately, the easiest and most accurate way to predict the impact of GPUs on your infrastructure is to experiment with real workloads. Be sure to experiment with multiple training workloads and multiple inference workloads. These experiments could be done in a low-cost POC environment or with a cloud vendor offering the GPU you wish to purchase.
Network Considerations
Since GPUs can process data at very high speeds, they can often outpace the speed at which data can be loaded during both training and inference. A slow or under-provisioned network can lead to GPUs idling while they wait for data to arrive.
Furthermore, many organizations employ distributed training techniques, whereby multiple GPUs within a cluster are used to train a single model using parallel training techniques. During distributed training, the networking infrastructure is not only responsible for keeping each individual GPU well fed with training data but also for exchanging gradients between GPUs during backpropagation. The performance of this operation depends heavily on the network's bandwidth and latency.
Networks are hard to upgrade because they are the glue holding everything together. It is not a node in a cluster that is redundantly deployed and can be easily removed or upgraded. Also, networking equipment is expensive, upgrades require careful planning, and there could be significant downtime while an upgrade is occurring. For all these reasons, consider futureproofing your training pipeline by investing in a fast network. A 400Gb or 800Gb network may sound excessive, but skipping a few upgrades could save money, and when faster GPUs are introduced, you can take advantage of them without problems.
Storage Considerations
If you adopt GPUs and have a high-speed network, the final consideration for your AI infrastructure is your storage solution. You may be all set if you are using MinIO’s AIStor with NVMe drives. MinIO has created a comprehensive blueprint for data infrastructure to support exascale AI and other large scale data lake workloads. It is called the MinIO DataPod. Why? Because exascale data is the reality that is common today in today's enterprise. If you do not have NVMe drives or want to squeeze even more performance out of your AI infrastructure, MinIO’s AIStor has three features that can help.
S3 over RDMA: Remote Direct Memory Access (RDMA) allows data to be moved directly between the memory of two systems, bypassing the CPU, operating system, and TCP/IP stack. This direct memory access reduces the overhead and delays associated with CPU and OS data handling, making RDMA particularly valuable for low-latency, high-throughput networking. MinIO recently introduced S3 over RDMA as a part of AIStor.
AIStor Cache: AIStor Cache lets enterprises use surplus server DRAM for caching. It is a caching service that uses a distributed, shared memory pool to cache frequently accessed objects. Once enabled and configured, AIStor Cache is transparent to the application layer and seamless to operate. Consider using AIStor Cache with S3 over RDMA.
Mirroring: If you have a large global data lake based on AIStor and it is not using the fastest disk drives available, you can install a new, smaller tenant of AIStor with NVMe drives and use it for all your AI workloads. AIStor’s mirroring feature will keep buckets containing your training sets synchronized between the tenants. Your global tenant of AIStor continues to be the gold copy of all your data. The new tenant is configured for performance and contains a copy of the data needed for AI. This approach has the advantage of not requiring customers to replace an existing instance of AIStor. This solution also works well with datasets that are too large for AIStor Caching. The high-speed tenant can also be scaled out as the data for AI workloads grows. Consider using a mirrored solution with S3 over RDMA for even faster performance.

Summary
The move from a CPU-based AI infrastructure to a GPU-based infrastructure can put an especially large strain on your network and storage solution. Even upgrading existing GPUs can be problematic due to the performance gains that Nvidia, Intel, and AMD have achieved. However, by investing in a future-proof network and using a storage solution like MinIO’s AIStor, which has caching, mirroring, and S3 over RDMA, organizations can be sure to get the most out of their GPU investments.






