Model Training and MLOps using MLRun and MinIO

In my previous post on MLRun, we set up a development machine with all the tools needed to experiment with MLRun. Specifically, we used a docker-compose file to create containers for the MLRun UI, the MLRun API Service, Nuclio, MinIO, and a Jupyter service. Once our containers started, we ran a simple smoke test to ensure everything was working correctly. We did this by creating a simple serverless function that logged its inputs and connected to MinIO to get a list of buckets.
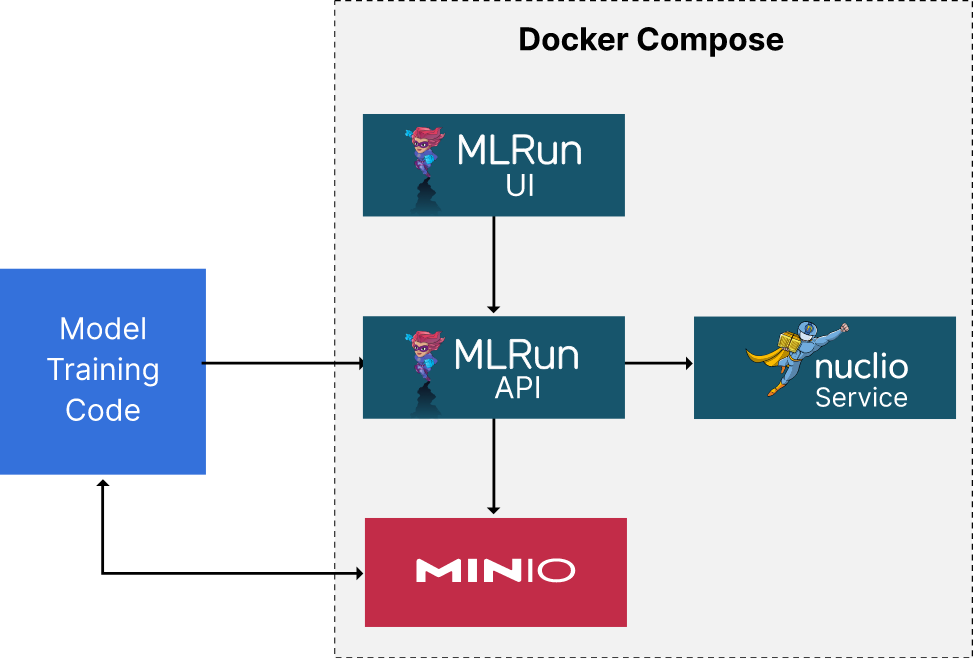
Below is a visualization of what we will build and what is in our docker-compose file. I extended the docker-compose file that you will find in the MLRun documentation so that it includes both an API service and MinIO. I will pick up where my last post left off in this post. We will create another serverless function that trains a model. Remember that MLRun aims to eliminate the need for boilerplate code, so we should also see a reduction in the code needed to train the model itself. If you think about the code you write to train a model - especially in PyTorch - it is basically the same regardless of the data used to train the model and the model itself. In other words, it's boilerplate code. In theory, it could be replaced with some added configuration. Additionally, deploying the code itself should be simple. We already saw some of this in my last post. However, deploying a function that drives model training is a little more complicated - so we will need more MLRun features to pull this off. The code accompanying this post (described in the next section) contains utilities that allow models to be trained with datasets that cannot fit into memory. I will not go into these techniques here - that is a subject for another post.
About the Code Download
All the code shown in this post (and more) is here. For brevity, many of the utility functions in my code download are not shown in the code listings of this post. However, many are general-purpose utilities for integrating PyTorch with MinIO. In this section, I will enumerate the important utilities I hope you find useful for all your ML projects using MinIO to store your datasets.
MinIO Utilities (data_utilities.py):
- get_bucket_list - Returns a list of buckets in MinIO.
- get_image_from_minio - returns an image from MinIO. Uses PIL to convert the object back into its original format.
- get_object_from_minio - Returns an object - as is - from MinIO.
- get_object_list - Gets a list of objects from a bucket.
- image_to_byte_stream - transform a PIL Image to a byte stream so that it can be sent to MinIO.
- load_mnist_to_minio - This function loads the MNIST dataset into a MinIO bucket. Each image is sent as an individual object. This method is useful for performance testing in a cluster as it creates many small images.
- put_image_to_minio - Puts an image byte stream to MinIO as an object.
PyTorch Utilities (torch_utilities.py):
- create_minio_data_loaders - Creates a PyTorch data loader with a list of MNIST objects in a MinIO bucket. Useful for simulating model training tests with datasets that cannot fit into memory.
- create_memory_loaders - Creates a PyTorch data loader where the MNIST images are loaded into memory.
- MNISTModel - the model used in this post.
- ConvNet - This is another model the reader can experiment with - It creates a Convolutional Neural Network (CNN) for the MNIST dataset.
Migrating Existing Code to MLRun
Let’s look at how we can migrate existing code to run as a serverless function within MLRun. This may be an approach you take to adopting MLRun if you have a lot of training code for several models but do not have time to change the code to take advantage of all of MLRun’s features. This is a viable approach to iteratively migrating to MLRun - get all your ML code managed by MLRun - then add code to take advantage of additional features.
Consider the code below, it trains a model on the MNIST dataset. (Imports and logging code have been omitted for brevity. The code download has all imports and logging.) It is a script that you can run from any terminal app. The “train_model” function retrieves the data, creates the model, and then turns control over to the “epoch_loop” function for training.
If we want to run this function as a serverless function within MLRun, we need only decorate the “train_model()” function with the “mlrun.handler()” decorator, as shown below.
Next, we need to set up the MLRun environment, create a project, register the training function with MLRun, and run the function. We will drive this from a Jupyter Notebook running within our docker-compose deployment. The cells needed to do this are shown below. (You can find this code in the mnist_training_setup.ipynb notebook in the code download.) The hyperparameters used in this simple demo are hard-coded; however, if you are building a model destined for production, you should use a hyperparameter search to find the optimal values.
That is all that needs to be done to run existing code within MLRun. However, if you look closely at the epoch_loop() function, you will notice that it is boilerplate code. Pretty much every PyTorch project has a similar function regardless of the model or the data being used to train the model. Let’s look at how we can use MLRun to remove this function.
Optimizing Training Code
We can remove the call to the epoch_loop function shown above by using MLRun’s mlrun_torch.train() function. The import for this function and a revised train_model() function are shown below. An “accuracy()” function is also passed to mlrun_torch.train().
There are a few things to keep in mind as you migrate your code to use this function.
- First, if you declare your loss function and your optimizer in your “epoch_loop()” function, then you will need to move these declarations as they must be passed to “mlrun_torch.train()”.
- Second, if you perform any transformations within your epoch loop, you will need to move them into your data processing logic or, better yet, a data pipeline. This is especially true if you are performing image augmentation and feature engineering.
- Finally, to have your model tested against a dataset it has not seen during training, you only need to provide an accuracy() function, as shown above.
While this function reduces the code you have to write, its biggest benefits are metric tracking and artifact management. Let’s take a quick tour of the MLRun UI to see what was saved from our first fully managed run, where we trained a model.
Reviewing Runs
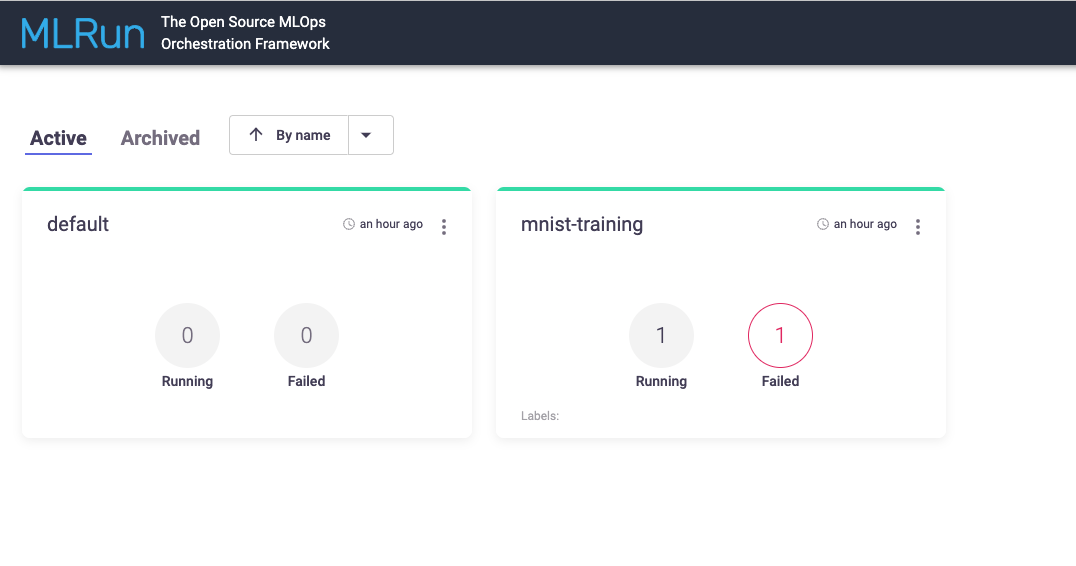
The homepage of the MLRun UI shows a list of all projects. For each project, you can see the number of failed and running jobs.
Drilling into your project you will see more details about your project.

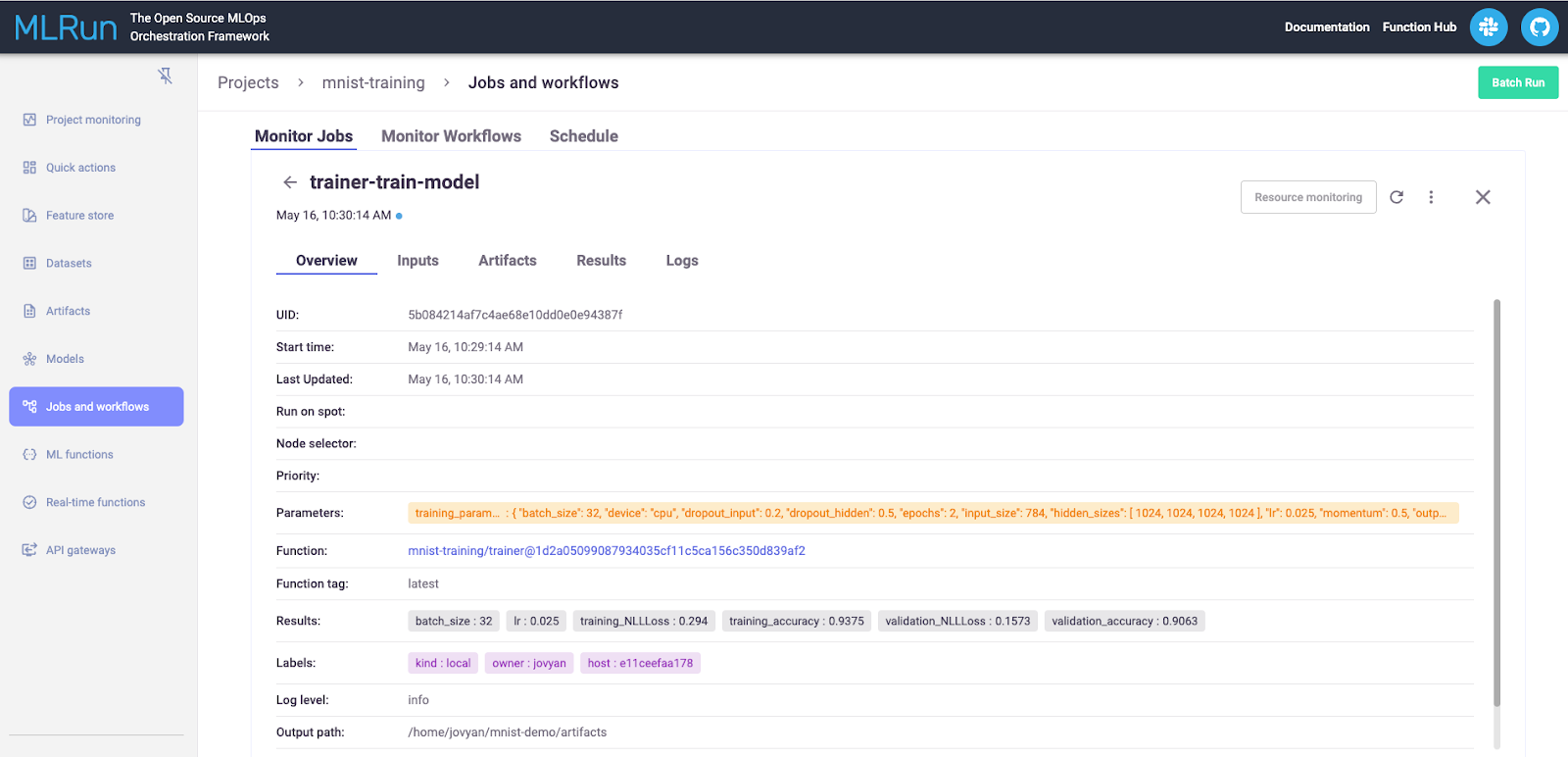
Clicking on a specific job will take you to the most recent run. Where you can review parameters, inputs, artifacts, results, and any output your code logged.
Summary and Next Steps
In this post, I picked up where my last post on setting up MLRun left off. I showed how to use MLRun to host existing model code with minimal changes. However, the best way to take advantage of MLRun's tracking features is to let MLRun manage your model's training.
While moving existing code to MLRun is possible, this technique does not fully take advantage of MLRun’s capabilities for automated tracking. A better approach is to use MLRun’s “mlrun_torch.train()” function. This allows MLRun to fully manage training - artifacts, input parameters, and metrics will be logged.
If you have come this far with MLRun, consider playing with distributed training and Large Language Models next.
If you have any questions, be sure to reach out to us on Slack! The “mlrun” channel of the MLOps Live Slack Workspace is also a great place to get help if you get stuck.






