Running Peta-Scale Spark Jobs on Object Storage Using S3 Select
When one looks at the amazing roster of talks for the Spark + AI Summit, what you don’t see is a lot of discussion on how to leverage object storage. On some level you would expect to — ultimately if you want to run your Spark job on peta-scale data sets and have it be available to your applications in the public or private cloud — this would be the logical storage architecture.
While logical, there has been a catch, at least historically, and that is object storage wasn’t performant enough to actually make running Spark jobs feasible. With the advent of a modern, cloud native approaches that changes and the implications for the Apache Spark™ community are pretty significant.
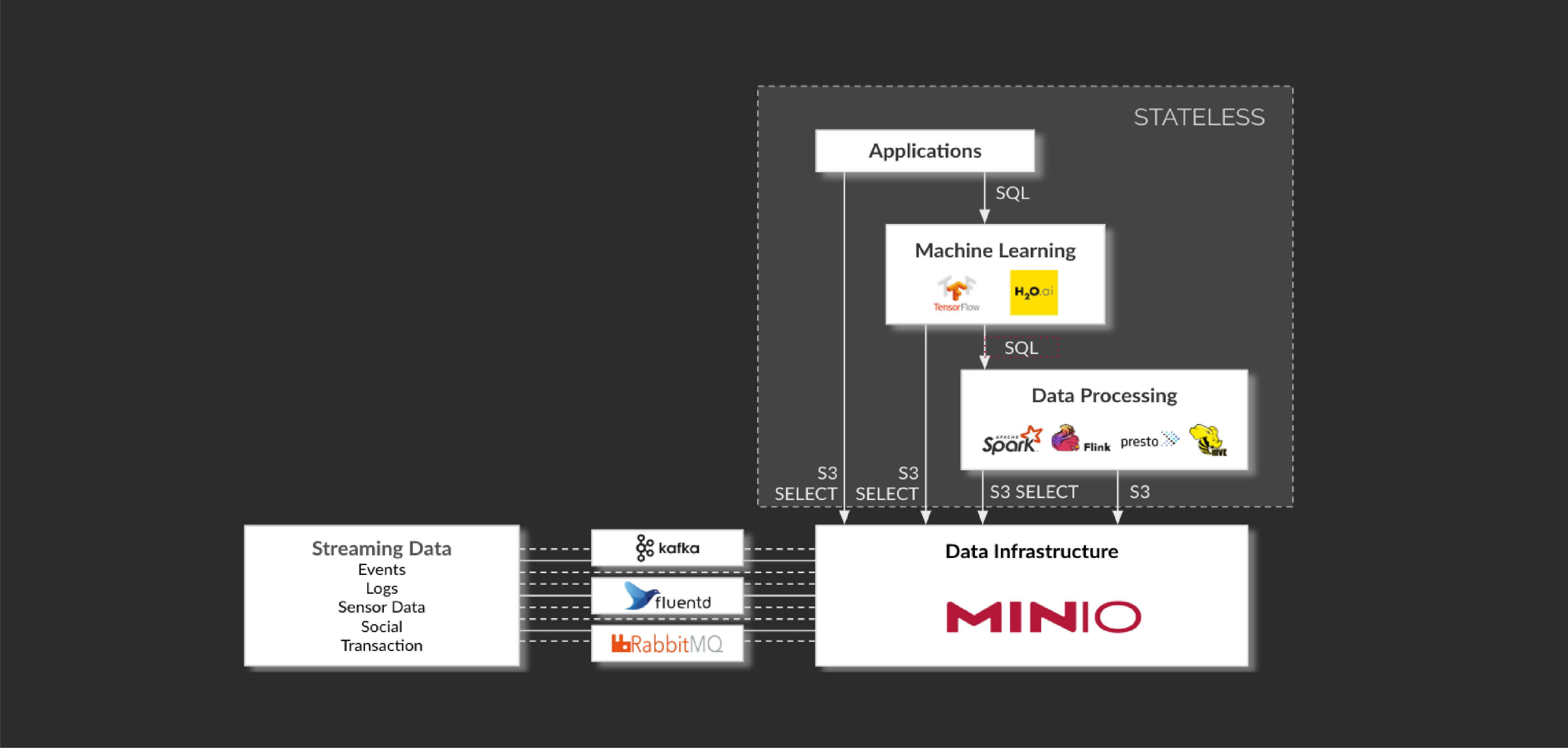
At the heart of this change is the extension of the S3 API to include SQL query capabilities, S3 Select. With S3 Select, users can execute queries directly on their objects, returning just the relevant subset, instead of having to download the whole object — significantly more efficient than the regular method of retrieving the entire object store.
MinIO has pioneered S3 compatible object storage. MinIO’s implementation of the S3 Select API matches the native features while offering better resource utilization when it comes to executing Spark jobs. These advancements deliver orders of magnitude performance improvements across a range of frequently used queries.
Using Apache Spark with S3 Select
With the MinIO S3 Select API, applications can offload query jobs to the MinIO server itself, resulting in significant speedups for the analytic workflow.
By pushing down possible queries to MinIO, and then loading only the relevant subset of the object to memory for further analysis, Spark SQL runs faster, consumes less network resources, uses less compute/memory resources and allows more Spark jobs to be run concurrently.
The implementation of Apache Spark with S3 Select works as a Spark data source, implemented via DataFrame interface. At a very high level, Spark and S3 Select convert incoming filters into SQL S3 Select statements. It then sends these queries to MinIO. As MinIO responds with data subset based on Select query, Apache Spark makes it available as a DataFrame for further operations. As with any DataFrame, this data can now be consumed by any other Apache Spark library e.g. Spark MLlib, Spark Streaming and others.
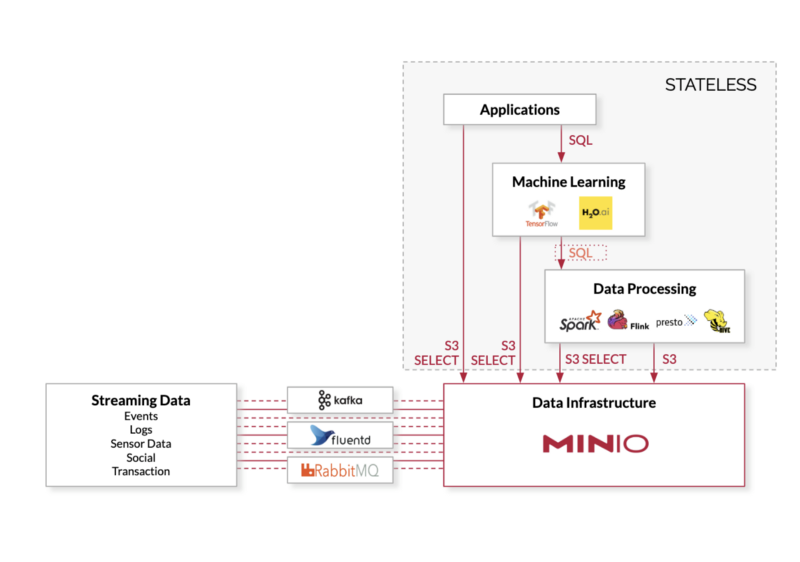
Presently, MinIO’s implementation of S3 Select and Apache Spark supports JSON, CSV and Parquet file formats for query pushdowns. Apache Spark and S3 Select can be integrated via spark-shell, pyspark, spark-submit etc. One can also add it as Maven dependency, sbt-spark-package or a jar import.
MinIO has, like all of its software, open sourced this code. It can be found herefor further inspection.
High-Speed Query Processing
To provide a sense of the performance, MinIO ran the TestDFSIO benchmark on 8 nodes and compared that with similar performance from AWS S3 itself. The average overall read IO was 17.5 GB/Sec for MinIO vs 10.3 GB/Sec for AWS S3. While MinIO was 70% faster (and likely even faster on a true apples to apples comparison) the biggest takeaway for the reader should be that both systems have completely redefined the performance standards associated with object storage.
Needless to say, this performance gap versus AWS S3 will increase as you scale the number of nodes available to MinIO.
This performance extends to writes as well, with both Minio and AWS S3 posting average overall write IO’s of 2.92 GB/Sec and 2.94 GB/Sec respectively. Again, the differences between MinIO and AWS S3 are less material than the overall performance.
What this means for the Apache Spark community is that object storage is now in play for Spark jobs that require high performance and scalability.
AWS S3 provides that in the public cloud. MinIO provides that in the private cloud.
One advantage of going the private cloud route with Minio is that the private cloud offers more opportunity to tune the hardware to the specific use case. This means NVMe drives, Optane memory and 100 GbE network. This will offer at least an order of magnitude performance improvements over the public cloud numbers listed above.
Learning More
As noted, MinIO’s code is open source and available here. We had the only talk on the subject at Spark + AI Summit and have made the slides available here. If you want to learn more, you can reach out to us on hello@min.io. or you can always interact with us on our Slack Channel.






