What it Really Means to be Software Defined
This post first appeared in the Container Journal.
The term “software-defined storage” is widely misunderstood by the vendor community. While analysts, both industry and financial, know that software-defined is both the present and future of the storage industry, customers who are unable to make the distinction may find themselves with a hardware- or appliance-based solution that doesn’t quite meet their needs or help them fulfill their business objectives and organizational goals.
Kubernetes is changing everything in the space, which makes it important to understand what it means to be truly software-defined.
First, there is no relationship between a business model and being software-defined. They are totally unrelated. When a company claims to generate x percent of their revenue from software, that is an accounting designation designed for financial analysts. Nothing more. We have seen the same phenomena in terms of “cloud revenue;” just as organizations aren’t cloud-native just because they have something to do with the cloud, neither are they software-defined just because they generate revenue from software.
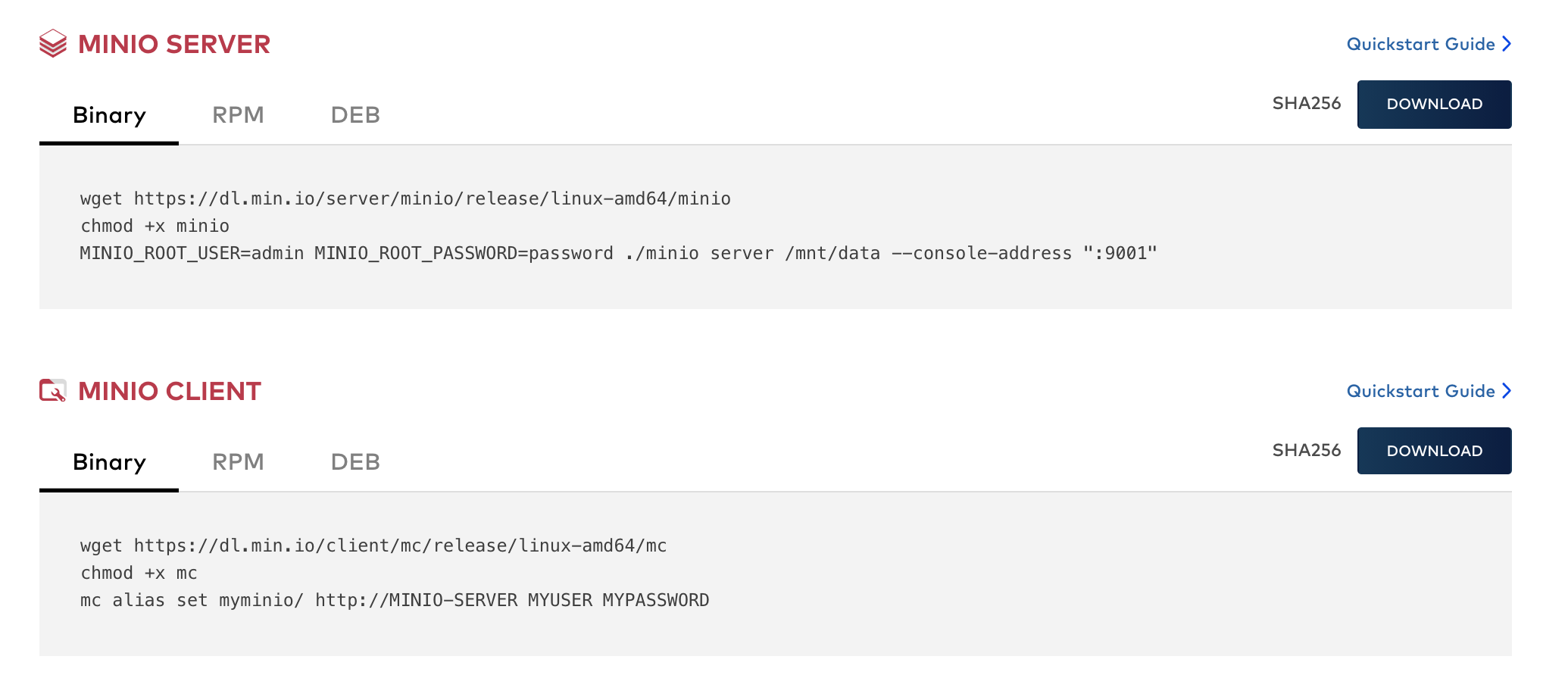
Being truly software-defined means you have a “download button” on your website. This means your customers and/or community can download and run your software on whatever hardware they want. The term “download” means you can actually pull down the software. In the Kubernetes world, that means YAML files and container pulls—not RPMs and DMGs.
Software-defined means there is no constraint on hardware. To be software-defined, your software should run on a wide range of devices, not just a handful. Not everyone will have a binary of <100MB and fit on a RaspberryPi or a 5GPOP, but the requirement to call yourself software-defined is that you run on commodity hardware—not on “certified” solutions that have to be carefully configured by a select group of resellers or integrators.
The “download” button doesn’t assume open source, either. You can have such a download button and have proprietary software. Thousands of companies do it—the storage industry can, too. Having said that, open source is the best way to earn your “software-defined” badge—because an active community will stretch and push you by putting your software in hardware configurations you cannot imagine.
Software-defined also requires simple installation. If you support a “download button,” you need to have the confidence that your software, when downloaded and used, will not create a support nightmare. That demands simplicity. Storage should be no different than downloading and setting up MongoDB or Cassandra. VMware recognized this fact and is why the Data Persistence platform is built around the concept of click-and-deploy object storage. In fact, this is the entire premise of the Kubernetes community: download and run—hardware choices simply reflect the requirements and constraints of the use case.
True software-defined storage is software that can run on any platform across any enterprise, whether in the cloud, in a data center or in an edge-based server. Interestingly enough, when you think about it, Amazon S3, Google Cloud and/or Microsoft Azure only run on their own infrastructure. They are storage software-as-a-service—not software-defined storage. That is why Outpost, Stack and Anthos are run on their own hardware or on tightly managed “certified solutions”—not commodity boxes. That is also why they don’t run on each other’s cloud or on-premises on existing hardware.
Modern software-defined storage also requires API-first design, with an optional graphical user interface (GUI) and with automation as a ‘first-class citizen.’ If a GUI is the only interface available (or the only well-documented and functional interface available) then you are probably not software-defined.
Finally, software-defined storage has to be “containerized” for today’s infrastructure needs over a number of different dimensions. For example, software-defined storage should work seamlessly across heterogeneous hardware types. This accounts for hardware obsolescence, but it also takes economics into account. Software-defined storage should not care about these dependencies. The same goes for operating systems; containerized software-defined storage runs on any Kubernetes flavor—K3s at the edge or Tanzu at the data center or Azure AKS in the cloud, for example.
Buyers want true software-defined storage that they can run anywhere, at any time, for any workload on any hardware. The ability to mix and match hardware based on lead times alone has massive value. Traditional hardware- or appliance-based storage vendors, on the other hand, are incentivized to push proprietary systems and solutions and lock in customers on their hardware and software stack.
Related: Software Defined Hardware: Supermicro's Rise Explained
I would encourage you to think carefully about these requirements, both now and in the future. My expectation is that, outside of a few archival use cases, almost all requirements will demand the flexibility that software-defined storage offers. This, in turn, should trigger a careful examination of any potential storage solution using the above criteria. Only then will you be able to determine if the term software-defined is being appropriately applied.






