The Architect’s Guide to the GenAI Tech Stack - Ten Tools

This post first appeared on The New Stack on June 3rd, 2024.
I previously wrote about the modern data lake reference architecture, addressing the challenges in every enterprise — more data, aging Hadoop tooling (specifically HDFS) and greater demands for RESTful APIs (S3) and performance — but I want to fill in some gaps.
The modern data lake, sometimes referred to as a data lakehouse, is one-half data lake and one-half Open Table Format Specification (OTF)-based data warehouse. Both are built on modern object storage.
Concurrently, we have thought deeply about how organizations can build AI data infrastructure that can support all your AI/ML needs — not just the raw storage of your training sets, validation sets and test sets. In other words, it should contain the compute needed to train large language models, MLOps tooling, distributed training and more. As a result of this line of thought, we put together another paper on how to use the modern data lake reference architecture to support your AI/ML needs. The graphic below illustrates the modern data lake reference architecture with the capabilities needed for generative AI highlighted.
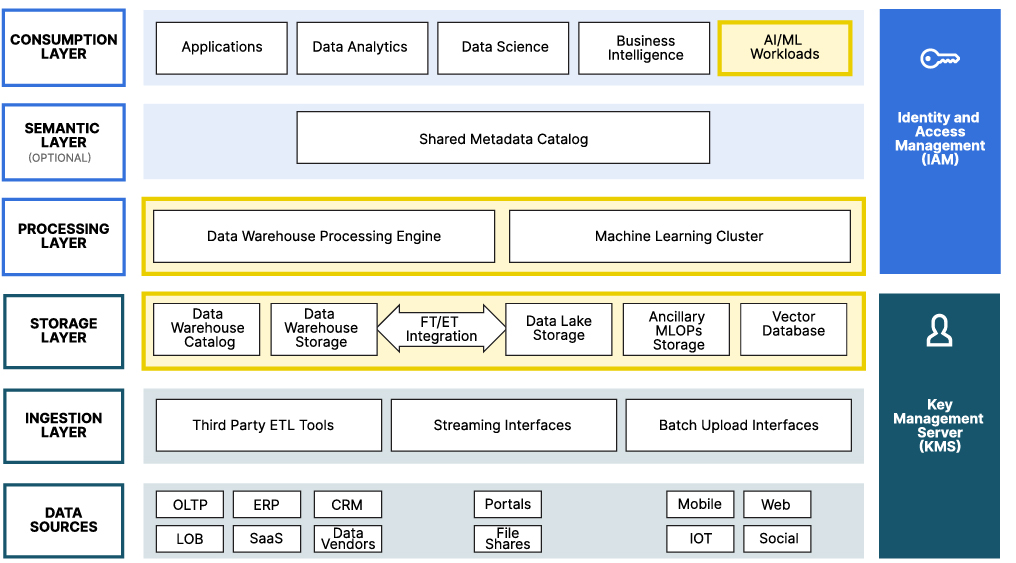
Source: AI/ML within a modern data lake
Both those papers do not mention specific vendors or tools. I now want to discuss vendors and tools needed to build the modern data lake. In this top-10 list, each entry is a capability needed to support generative AI.
1. Data Lake
Enterprise data lakes are built on object storage. Not your old-school, appliance-based object storage that served cheap and deep archival use cases, but modern, performant, software-defined and Kubernetes native object stores, the cornerstones of the modern GenAI stack They’re available as a service (AWS, GCP, Azure) or on-premises or hybrid/both, such as MinIO. These data lakes have to support streaming workloads, must have highly efficient encryption and erasure coding, need to store metadata atomically with the object and support technologies like Lambda compute. Given these modern alternatives are cloud native, they will integrate with the entire stack of other cloud native technologies — from firewalls to observability to user and access management — right out of the box.
2. OTF-Based Data Warehouse
Object storage is also the underlying storage solution for an OTP-Based data warehouse. Using object storage for a data warehouse may sound odd, but a data warehouse built this way represents the next generation of data warehouses. This is made possible by the OTF specifications authored by Netflix, Uber and Databricks, which make it seamless to employ object storage within a data warehouse.
The OTFs — Apache Iceberg, Apache Hudi and Delta Lake — were written because there were no products on the market that could handle the creators’ data needs. Essentially, what they all do (in different ways) is define a data warehouse that can be built on top of object storage. Object storage provides the combination of scalable capacity and high performance that other storage solutions cannot. Since these are modern specifications, they have advanced features that old-fashioned data warehouses do not have such as partition evolution, schema evolution and zero-copy branching.
Two MinIO partners that can run their OTF-based data warehouse on top of MinIO are Dremio and Starburst.
Dremio Sonar (data warehouse processing engine)
Dremio Arctic (data warehouse catalog)
Open Data Lakehouse | Starburst (catalog and processing engine)
3. Machine Learning Operations (MLOps)
MLOps is to machine learning what DevOps is to traditional software development. Both are a set of practices and principles aimed at improving collaboration between engineering teams (the Dev or ML) and IT operations (Ops) teams. The goal is to streamline the development life cycle using automation, from planning and development to deployment and operations. One of the primary benefits of these approaches is continuous improvement.
MLOps techniques and features are constantly evolving. You want a tool that is backed by a major player, ensuring that the tool is under constant development and improvement and will offer long-term support. Each of these tools uses MinIO under the hood to store artifacts used during a model's life cycle.
MLRun (Iguazio, acquired by McKinsey & Company)
4. Machine Learning Framework
Your machine learning framework is the library (usually for Python) that you use to create your models and write the code that trains them. These libraries are rich in features as they provide a collection of different loss functions, optimizers, data transformation tools and pre-built layers for neural networks. The most important feature these two libraries provide is a tensor. Tensors are multi-dimensional arrays that can be moved onto the GPU. They also have auto differentiation, which is used during model training.
The two most popular machine learning frameworks today are PyTorch (from Facebook) and Tensorflow (from Google).
5. Distributed Training
Distributed model training is the process of simultaneously training machine learning models across multiple computational devices or nodes. This approach speeds up the training process, particularly when large datasets are needed to train complex models.
In distributed model training, the dataset is divided into smaller subsets, and each subset is processed by different nodes in parallel. These nodes can be individual machines within a cluster, individual processes or individual pods within a Kubernetes cluster. They may have access to GPUs. Each node independently processes its subset of data and updates the model parameters accordingly. The five libraries below insulate developers from most of the complexity of distributed training. You can run them locally if you do not have a cluster, but you will need a cluster to see a notable reduction in training time.
Spark PyTorch Distributor (from Databricks)
Spark TensorFlow Distributor (from Databricks)
6. Model Hub
A model hub is not really part of the modern data lake reference architecture, but I am including it anyway because it is important for quickly getting started with generative AI. Hugging Face has become the place to go for large language models. Hugging Face hosts a model hub where engineers can download pre-trained models and share models they create themselves. Hugging Face is also the author of the Transformers and the Datasets libraries, which work with large language models (LLMs) and the data used to train and fine-tune them.
There are other model hubs. All the major cloud vendors have some way to upload and share models, but Hugging Face, with its collection of models and libraries, has become the leader in this space.
7. Application Framework
An application framework helps incorporate an LLM into an application. Using an LLM is dissimilar to using a standard API. Much work must be done to turn a user request into something the LLM can understand and process. For example, if you build a chat application and you want to use Retrieval Augmented Generation (RAG), then you will need to tokenize the request, turn the tokens into a vector, integrate with a vector database (described below), create a prompt, and then call your LLM. An application framework for generative AI will allow you to chain these actions together. The most widely used application framework today is LangChain. It has integrations with other technologies, for example, the Hugging Face Transformer library and Unstructured’s library for document processing. It is feature-rich and can be a little complicated to use, so listed below are some alternatives for those who do not have complex requirements and want something simpler than LangChain.
8. Document Processing
Most organizations do not have a single repository with clean and accurate documents. Rather, documents are spread across the organization in various team portals in many formats. The first step when getting ready for generative AI is to build a pipeline that takes only documents that have been approved for use with generative AI and places them in your vector database. This could potentially be the hardest task of a generative AI solution for large global organizations.
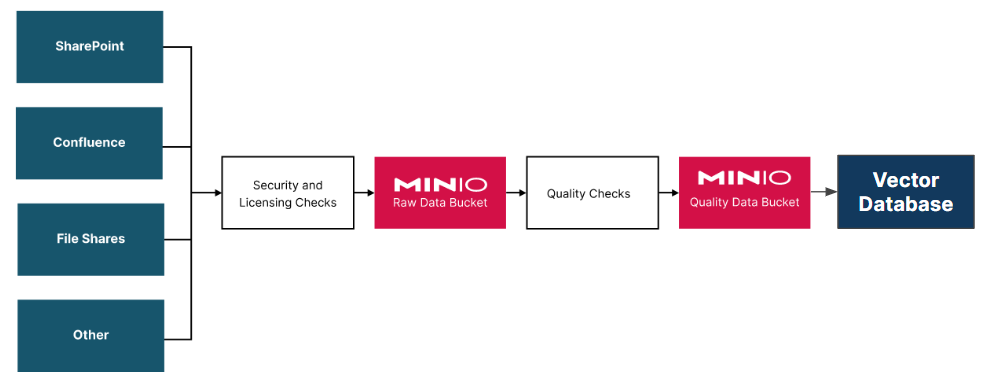
A document pipeline should convert the documents to text, chunk the document and run the chunked text through an embedding model so its vector representation can be saved into a vector database. Fortunately, a few open source libraries can do this for many of the common document formats. A few libraries are listed below. These libraries could be used with LangChain to build a full document processing pipeline.
9. Vector Databases
Vector databases facilitate semantic search. Understanding how this is done requires a lot of mathematical background and is complicated. However, semantic search is conceptually easy to understand. Let’s say you want to find all documents that discuss anything related to “artificial intelligence.” To do this on a conventional database, you would need to search for every possible abbreviation, synonym and related term of “artificial intelligence.” Your query would
look something like this:
Not only is this manual similarity search arduous and prone to error, but the search itself is very slow. A vector database can take a request like below and run the query faster and with greater accuracy. The ability to run semantic queries quickly and accurately is important if you wish to use Retrieval Augmented Generation.
Four popular vector databases are listed below.
Related: What is a Vector Database?
10. Data Exploration and Visualization
It is always a good idea to have tools that allow you to wrangle your data and visualize it in different ways. The Python libraries listed below provide data manipulation and visualization capabilities. These may seem like tools you only need for traditional AI, but they also come in handy with generative AI. For example, if you are doing sentiment analysis or emotion detection, then you should check your training, validation and test sets to make sure you have a proper distribution across all your classes.
Related: What Is Generative AI? A Guide for IT Leaders
Conclusion
There you have it: 10 capabilities that can be found in the modern data lake reference architecture, along with concrete vendor products and libraries for each capability. Below is a table summarizing these tools.
- Data Lake - MinIO, AWS, GCP, Azure
- OTF-based data warehouse - Dremio, Dremio Sonar, Dremio Arctic, Starburst, Open Data Lakehouse | Starburst
- Machine learning framework - PyTorch, TensorFlow
- Machine learning operations - MLRun (McKinsey & Company), MLflow (Databricks), Kubeflow (Google)
- Distributed training - DeepSpeed (from Microsoft), Horovod (from Uber), Ray (from Anyscale), Spark PyTorch Distributor (from Databricks), Spark Tensoflow Distributor (from Databricks)
- Model hub - Hugging Face
- Application framework - LangChain, AgentGPT, Auto-GPT, BabyAGI, Flowise, GradientJ, LlamaIndex, Langdock, TensorFlow (Keras API)
- Document processing - Unstructured, Open-Parse
- Vector database - Milvus, Pgvector, Pinecone, Weaviate
- Data exploration and visualization - Pandas, Matplotlib, Seaborn, Streamlit






