The Disruptive Nature of Data Lakehouses

Introduction
In 1997, Clayton Christensen, in his book The Innovator’s Dilemma, identified a pattern of innovation that tracked the capabilities, cost, and adoption by market segment between an incumbent and a new entrant. He labeled this pattern “Disruptive Innovation.” Not every successful product is disruptive - even if it causes well-established businesses to lose market share or even fail altogether. The label “Disruptive Innovation” has a very precise definition. It is the relationship over time between customer demand by market segment (low end, mainstream, and high end), an incumbent’s capabilities, and an entrant’s capabilities. A visualization of this relationship between product capabilities and customer demand is shown below.
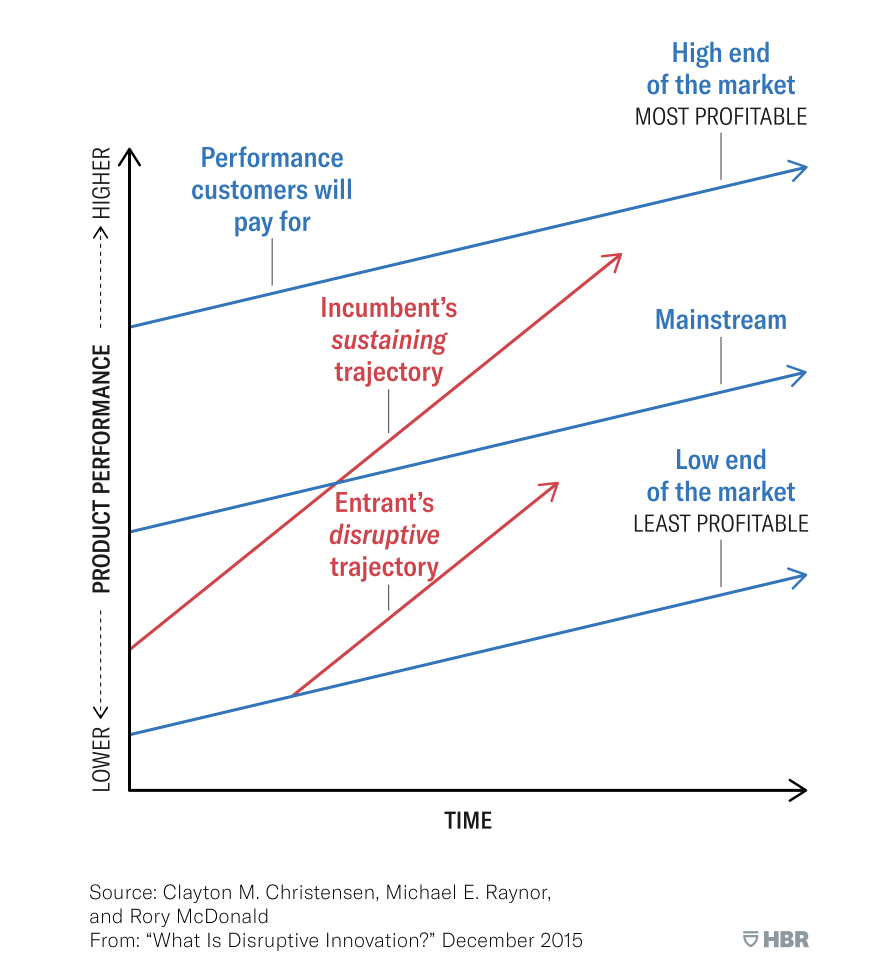
Source: What Is Disruptive Innovation?
A brief summary of disruption theory is below:
- Disruptive Innovation is a process that occurs over time.
- Conditions are perfect for disruption when the low end of the market is ignored.
- Disruption starts when an entrant takes advantage of the underserved low end of the market to gain a foothold.
- The entrant must continue to innovate in order to move to higher markets.
- If the entrant reaches the high end of the market and is able to preserve a capabilities to cost benefit an incumbent could be in trouble.
The promise of identifying a new technology as falling into this pattern is that you can identify the challengers and the incumbents. In short, you can predict adoption - how the new technology will grow. You can also identify who is going to be displaced as incumbent products lose market share. Additionally, as a consumer or practitioner in the software industry, understanding change is really the holy grail of this industry - an industry where change is the only constant. Whether you are an investor looking for the next hot stock, a decision maker trying to keep your company current, or a technologist trying to keep your skills up to date - being able to see around a corner is invaluable.
Fast forward to today - September 2023 and there is a sneaky collection of startups building what is known as “Data Lakehouses.” A Data Lakehouse is not a single product from a single company. Rather, it is a design pattern. This design pattern utilizes open specifications from companies like Uber, Netflix, and Databricks. It also uses open source technologies from companies and organizations like MinIO, Apache Spark, and Project Nessie, which enables Git-like semantics at the data catalog level.
The purpose of this paper is to explore the definition of Disruptive Innovation, look at exactly what a Data Lakehouse is and how it is being adopted in the industry. Once both of these ideas are understood, we can come to a conclusion as to whether Data Lakehouses are disruptive and will follow the pattern that so many other disruptive technologies have followed.
Let’s look at what is happening with Data Warehouses and Data Lakehouses.
Related: Data Lakehouse Solutions by MinIO
Comparing Capabilities
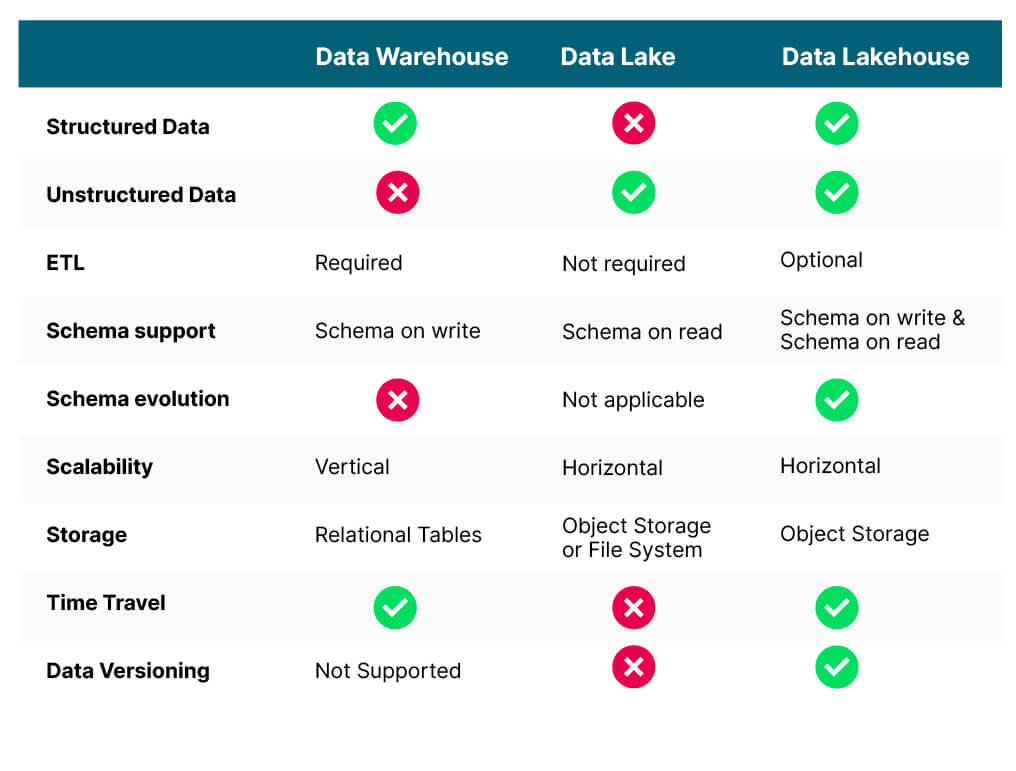
Let’s define and compare all the options available to an organization when deciding where to house data that will be used for Business Intelligence, Data Analytics, and Machine Learning. At a high level, these storage options are Data Lakes, Data Warehouses, and Data Lakehouses.
Data Warehouse
Data warehouses are designed to store and manage large volumes of structured data from various sources. They organize data into tables and are typically scaled vertically by adding more resources to a single server or node. (Some modern Data Warehouses also support horizontal scaling to some extent.) The tables require predefined schemas, which can limit flexibility when dealing with evolving or unstructured data. Data Warehouses support time travel, which is a feature that allows a table to be viewed as it existed in the past. However, Data Warehouses do not support data versioning, which allows a table to be branched like a code repository. Running a Data Warehouse can be expensive, especially for large-scale operations, due to the need for high-performance hardware and software licenses.
Data Lake
Data lakes are designed to store large volumes of unstructured data that remain in its raw, native format. Since data is stored in its original format, a predefined schema is not required. Consequently, they are more flexible and can handle a wider variety of data types. Since they do not support the concept of a table - time travel and data versioning are not supported. Data lakes are cost-effective as they leverage lower-cost storage solutions and scale horizontally to accommodate growing data volumes.
Data Lakehouse
Data Lakehouses are designed to handle both structured and unstructured data by providing two storage techniques depending on how the data will be used. They support schema evolution for structured data, allowing data engineers and analysts to make changes to the schema as needed without requiring extensive ETL processes. This flexibility is crucial in the era of rapidly changing data. They also support time travel and data versioning. Data Lakehouses are built on open-source and cloud-native technologies, providing greater flexibility in tool selection and integration. Finally, they are more cost-effective as they leverage object storage and distributed computing, allowing both storage and the processing engine to scale horizontally to accommodate growing data volumes and improve query performance. While Data Lakehouses provide good performance for ad-hoc and exploratory queries, they may not match the performance of Data Warehouses for complex, structured data analytics tasks.
Putting it all together
Related: Data Lakehouse Examples in Action
The promise of Data Lakehouses is that they will have the best features and capabilities of a Data Warehouse and a Data Lake combined into one solution. This may seem too good to be true, but the recent advances in Open Table Formats (OTF) make it possible to use object storage for both structured data and unstructured data. Apache Iceberg, Hudi, and Delta Lake are the three popular OTFs today. They are specifications that, once implemented, provide a processing engine with the metadata needed to efficiently query data in an object store - this is the Data Warehouse component of the Data Lakehouse. Since an object store is being utilized, the same object store can be used for unstructured data - this is the Data Lake side of the Data Lakehouse. The diagram below shows the components of a Data Lakehouse.
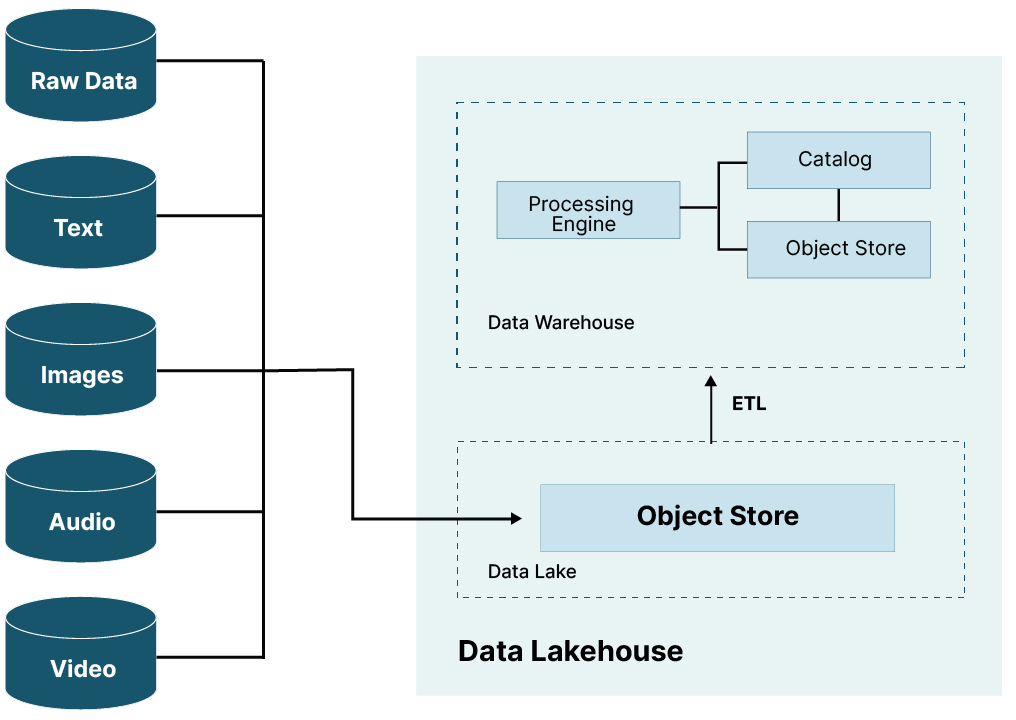
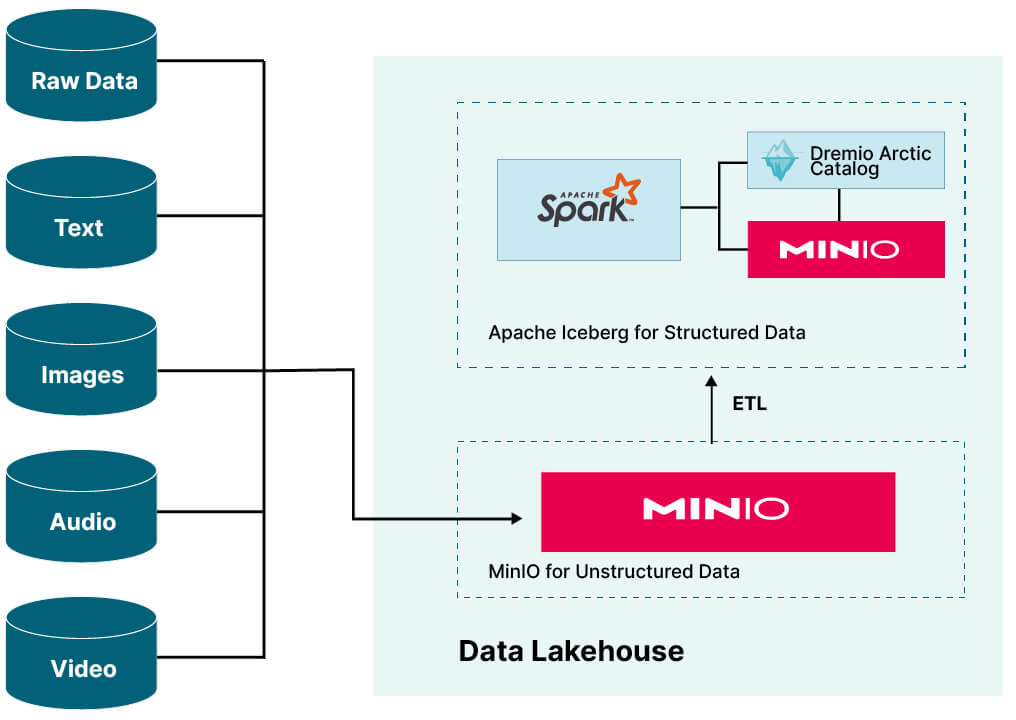
Data Lakehouses are not a single product from a single company. Referring to the diagram above, we can see that it is a collection of products from various vendors. You need an object store, a processing engine, and a catalog. Furthermore, there is no single vendor that has exclusivity on either of these three components. The design is disaggregated and disaggregation provides options allowing you to use what you may already have. An example of a concrete Data Lakehouse implementation is shown below. If you are already using MinIO for an object store, then use it for your Data Lakehouse. Already standardized on Spark for compute then it can be your processing engine. Finally, if you are interested in data versioning, then consider Dremio Arctic for a catalog.
Are Lakehouses Disruptive?
We can now return to our original tenets of disruption theory and see if the adoption of Data Lakehouses will proceed in a fashion that disrupts Data Warehouses.
I do not believe there is a low end of the market that has been doing without the capabilities described in the previous section. However, there is a general consensus in the industry that proprietary Data Warehouses are expensive. Also, many organizations are looking to cut their Cloud Computing costs - this effort will start with data. At the same time, a lot of organizations have bloated on-premise databases that are essentially Data Warehouses and are in need of re-platforming. Finally, the AI boom has created an increased need for unstructured data. These three forces - cost cutting, re-platforming, and the increased demand for unstructured data to support large language models have given Data Lakehouses the foothold they need to begin the disruptive process.
Both Data Warehouse vendors and Data Lakehouse vendors continue to improve their capabilities. Data Warehouse vendors and their products are considered more mature and large organizations today are more comfortable using them. However, the single server scale up design of Data Warehouses is troubling. This is not a modern solution - organizations will have to pay for a server that can handle their peak workloads and burn cash during periods of low usage. This represents an attack vector for Data Lakehouses. All the components of a Data Lakehouse can run on low cost servers in a cluster that scales out. Furthermore, the compute portion of the Data Lakehouse can scale elastically, saving money during low usage.
Also, products that exist only in the Cloud are limiting. They could fall victim to cost cutting or they may not be considered at all if the data cannot reside in the Cloud. Data Lakehouses have an advantage here as well. Their modern design is cloud native and can run anywhere a cluster of microservices can run.
Summary
Everything is in place for Data Lakehouses to disrupt Data Warehouses - especially expensive Data Warehouses that exist only in the Cloud. Cost cutting, replatforming, and the needs of large language models have given Data Lakehouses a foothold. Their modern design, compared to the outdated design of Data Warehouses, will give them the competitive advantage they need to succeed once they reach the high end of the market. Additionally, they have support from startups and the open source community.






