The Foundation of Your AI Infrastructure: A Modern Datalake

Amid the fervor to adopt AI is a critical and often overlooked truth - the success of any AI initiative is intrinsically tied to the quality, reliability and performance of the underlying data infrastructure. If you don't have the proper foundation, you are limited in what you can build and therefore what you can achieve.
Your data infrastructure is the bedrock upon which your entire AI infrastructure is built. It's where data is collected, stored, processed, and transformed. Training models using supervised, unsupervised, and reinforcement learning require storage solutions that can handle structured data - like a Data Warehouse. On the other hand, if you are training Large Language Models (LLMs), you must manage unstructured data - documents in their raw and processed form.
A Modern Datalake, or Lakehouse, is the foundation for both these different flavors of AI. A Modern Datalake is one-half Data Warehouse and one-half Data Lake and uses object storage for everything. More recently, we have seen the rise of open table formats. Open Table Formats (OTFs) like Apache Iceberg, Apache Hudi, and Delta Lake make it seamless for object storage to be used within a data warehouse.
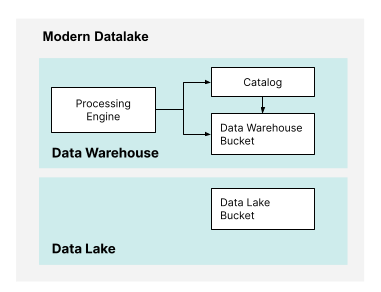
The rest of this article will examine how to leverage the characteristics of the Modern Datalake that differentiate it from conventional solutions like proprietary Data Warehouses and appliances. To build a foundation for AI infrastructure you need the following:
- Disaggregation of Compute and Storage
- Scale Out (Not Up)
- Software Defined
- Cloud Native
- Commodity Hardware
If we agree on the above, a series of best practices emerge that focus on two areas of performance. If incorporated, the modern Datalake will be both fast and scalable. These best practices include:
- Optimizing Drive Price and Performance
- Incorporate a High-Speed Network
Disaggregating Compute and Storage
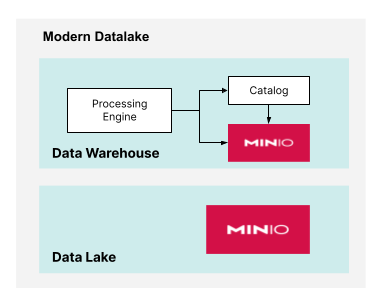
Disaggregating compute and storage within your data infrastructure means that separate resources are used for compute and storage. This contrasts conventional storage solutions, where everything comes packaged in a single server or, worse yet, an appliance. However, Modern Datalakes take disaggregation to another level. If the Data Lake and the Data Warehouse had completely different storage requirements, we could use two separate instances of an object store, as shown below.
Additionally, If the Data Warehouse needs to support workloads that require conflicting configurations, then you could use more than one processing engine. This is shown below.
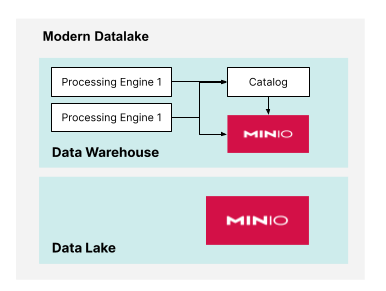
A composable infrastructure allows you to scale your compute and storage resources independently. This means you can allocate more resources to the part of your infrastructure that needs it most rather than upgrading both compute and storage together. It results in cost-effective scaling as you only invest in the required resources.
Scale-Out Not Up
AI workloads are data intensive, are often distributed across multiple CPUs or GPUs, use copious compute power for training, and necessitate real-time inference. Scaling out, not up, helps optimize performance and accommodate high-speed networks.
Scaling out and scaling up are two different approaches to increasing the capacity and performance of your data infrastructure. However, scaling out is proving to be the more viable approach as advances are made in clustering platforms like Kubernetes and more and more solutions strive to be cloud native. Scaling out in a disaggregated infrastructure provides:
High Availability and Fault Tolerance - If one node is busy, another node can take on a new request, reducing wait times and increasing throughput. If one node fails, the workload can be shifted to other nodes, reducing downtime and ensuring continuity.
Performance and Flexibility - Scaling out can provide better performance by distributing workloads across multiple nodes or servers to handle larger volumes of data and more concurrent requests. Scaling out is also more flexible because you can add or remove nodes as needed, making it easier to adjust to fluctuating workloads or to accommodate seasonal variations.
Operationally and Resource Efficient - Maintenance and upgrades are simplified when you scale out. Instead of taking a critical system offline for upgrades, you can perform maintenance on individual storage or compute nodes without disrupting the entire infrastructure.
Cloud Native + Software Defined
The last component of leveraging the Modern Datalake to build a strong foundation for AI is taking a cloud-native, software-defined approach.
Containers like Docker and container orchestration tools, like Kubernetes, make cloud-native architectures possible. All the components of a Modern Datalake run in containers that run in Kubernetes. Therefore, a Modern Datalake is cloud native.
"Software-defined" refers to an approach in which software controls and manages the configuration, functionality, and behavior of hardware components, often in the context of computer systems and networking. This is the building block of the infrastructure as code movement where the emphasis is on smart software and dumb fast hardware. Software-defined storage abstracts and manages the storage resources through software, making allocating and managing storage capacity across different devices and storage media easier.
Built for Speed: NVMe and 100GbE
To take full advantage of your commodity hardware and software-defined architecture - you need two more key pieces. The first is NVMe drives. Modern, performance oriented workloads, the random nature of read/write, the rise of small objects and falling SSD pricing all favor a NVMe centric architecture. Do that math, the upfront may be higher, the TCO will be lower.
The second component is 100GbE networking. In a software-defined world, the network turns out to be the bottleneck in many setups even at 100GbE. Here are some of those scenarios:Data Intensive - AI workloads often process massive datasets, such as images, videos, natural language text, and sensor data. High-speed networks can quickly transfer these large datasets between storage and processing units, reducing data transfer bottlenecks.
Distributed Computing - Many AI tasks involve distributed computing across multiple CPUs or GPUs. High-speed networks enable efficient communication and data exchange between these devices, ensuring the computing clusters work in parallel effectively.
Model Training - Training deep learning models, especially LLMs like transformers or convolutional neural networks, requires a lot of data and computational power. A high-speed network allows faster data loading and synchronization between distributed GPUs, which can significantly speed up training times.
Real-time Inference - Low-latency and high-throughput networks are essential for responsive applications that incorporate AI. A high-speed network ensures minimal delay between a user request and a response from a model.
Foundational Concepts
By adhering to these principles: the disaggregation of compute and storage, scale-out, not up, dumb, fast hardware and smart cloud native software the enterprise can construct a Modern Datalake that has the right foundation for meeting these requirements and pushing your AI initiatives forward.
You cannot construct a building on a poor foundation, just ask the ancient Egyptians. The AI game is about performance at scale, and this requires the right foundation. To skimp on the foundation is to accumulate technical debt that will topple your Jenga tower after a few minutes. Build smart, put the foundation in place.






