Generative AI for the Enterprise

Introduction
Generative AI represents the latest technique an enterprise can employ to unlock the data trapped within its boundaries. The easiest way to conceptualize what is possible with Generative AI is to imagine a customized Large Language Model - similar to the one powering ChatGPT - running inside your firewall. Now, this custom LLM is not the same as the one OpenAI is hosting on the public internet. Instead, it has acquired an “advanced education” on your business. This is done by giving it access to a corpus of documents inaccessible to the outside world. However, this new tool is not a conventional search engine that will provide a list of links that will take you hours to review and further filter. Rather, it is a solution that can generate the content you need. Over time, you will find yourself giving it commands as well as asking it questions. Below are a few examples to provide you with a feel for what is possible:
- “Find our recent findings in the European stock market.”
- “Create an abstract for my talk on Generative AI.”
- “Find everything we have published this quarter.”
The examples above are research scenarios, but a well-constructed Large Language Model (LLM) can also be used for customer support (chatbot), summarization, research, translation, and document creation, just to name a few.
These simple examples highlight the power of Generative AI - it is a tool for getting your job done more efficiently as opposed to generating a reading list.
Such a tool cannot be willed into existence, and things can go very wrong if concerns like security and data quality are not considered. Additionally, the models that power generative AI cannot run within a conventional data center. They need a modern environment with modern tools for managing unstructured data (data lake), creating AI/ML pipelines for your LLMs (MLOPs tooling), and new tooling that allows LLMs to get the education they need concerning your custom corpus. (I am talking about vector databases for implementing Retrieval Augmented Generation - I’ll explain further later in this post).
In this post, I want to cover at a conceptual level what should be considered for an Enterprise to implement Generative AI successfully.
Let’s start with a conversation about data.
Data Sources (Raw Data)
An important distinction is that the data needed for generative AI is not the same as the data used for conventional AI. The data will be unstructured - specifically, the data you need will be documents locked up in tools like SharePoint, Confluence and network file shares. A good Generative AI solution can also handle non-textual content such as audio and video files. You will need a data pipeline that collects all this data and puts it under one roof.
This may be the most challenging task of a Generative AI initiative. We all know how quickly Confluence sites and Sharepoint sites crop up within an organization. There is no guarantee that the documents within them are complete, true and accurate. Other concerns are security, personally identifiable information, and licensing terms if the documents came from an outside source.
Once you have identified the documents that contain true intelligence, you need a place to put them. Unfortunately, they can not stay in their original location. SharePoint, Confluence, and network file shares are tools that were not designed to serve documents quickly for training and inference. This is where MinIO comes into play. You will want to store your documents in a storage solution that has all the capabilities you are used to: Scales with your needs, Performance at Scale, Reliable, Fault Tolerant, and a Cloud Native Interface. The bottom line is that you need to build a data pipeline that aggregates raw data from multiple sources and then transforms it for consumption by an LLM. The diagram below shows the variety of sources that may exist within an organization and the high-level checks that should occur.

Let’s take a closer look at the data pipeline by digging into the security and quality checks needed to transform raw data into quality data.
Data Preprocessing (Quality Data)
Organizations should start by taking an inventory of all document sources. For each document source, all documents found should be cataloged. Documents should be reviewed concerning licensing and security. Some documents may need to be excluded from your solution. An important part of this process is to identify restricted data that needs to be modified before being included in your generative AI solution.
Once you have reviewed your documents for security and licensing, quality checks are next. For example, truthfulness, diversity (if they are about people) and redundancy. Accurate models cannot be created without high-quality data. This is true with conventional AI (supervised learning, unsupervised learning, and reinforcement learning) - and it is especially true with generative AI. Lower-quality documents, redundant documents and documents that contain inaccurate data will dilute the responses from an LLM or even create hallucinations.
A visualization of a more detailed pipeline looks like this:
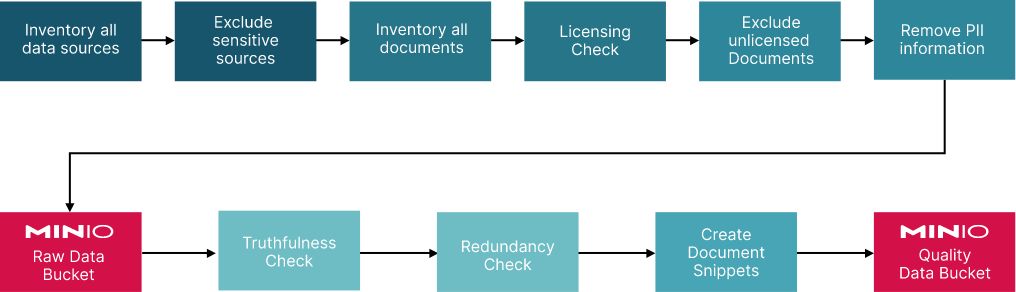
A few thoughts on the importance of a storage solution: Your quality documents need to be in a storage solution that can serve your data quickly for training, fine-tuning and inference. The more experiments your engineers can run, the better your models will eventually perform. You will also want to keep track of experiments, save processed data, and version your models. This can be done manually by directly saving this information to MinIO or using the MLOP tool of your choice. Many MLOP tools use object storage under the hood. For example, MLFlow from DataBricks and KubeFlow from Google both use MinIO. Additionally, the instance of MinIO depicted in the above diagrams should come from an implementation of a modern data lake. A modern data lake is the center of a system architecture that can support AI.
Let’s move on and discuss how LLMs can use the object store containing your quality documents.
How LLMs Use Quality Data
In this section, we will look at two ways of using open-source LLMs and your quality documents to generate domain-specific content. These two techniques are fine-tuning and retrieval augmented generation (RAG).
Fine-Tune an Open Source Model
When we fine-tune a model, we train it a little more with custom information. This could be a good way to get a domain-specific LLM. While this option does require compute to perform the fine-tuning against your custom corpus, it is not as intensive as training a model from scratch and can be completed in a modest time frame.
If your domain includes terms not found in everyday usage, fine-tuning will improve the quality of the LLM’s responses. For example, projects that will use documents from medical research, environmental research, and anything related to the natural sciences will benefit from fine-tuning. Fine-tuning takes the highly specific vernacular found in your documents and bakes them into the parametric parameters of the model.
Disadvantages
- Fine-tuning will require compute resources.
- Explainability is not possible.
- You will periodically need to re-fine-tune with new data as your corpus evolves.
- Hallucinations are a concern.
Advantages
- The LLM has knowledge from your custom corpus via fine-tuning.
- Better time to value as compared to RAG.
While fine-tuning is a good way to teach an LLM about the language of your business, it dilutes the data since most LLMs contain billions of parameters and your data will be spread across all these parameters.
Let’s look at a technique that combines your custom data and parametric data at inference time.
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) is a technique that starts with the question being asked - marries it with additional data, and then passes the question and data to an LLM and a vector database for content creation. With RAG, no training is needed because we educate the LLM by sending it relevant text snippets from our corpus of quality documents.
It works like this using a question-answering task: A user asks a question in your application’s user interface. Your application will take the question - specifically the words in it - and, using a vector database, search your corpus of quality documents for text snippets that are contextually relevant. These snippets, along with the original question, get sent to the LLM. This entire package - question plus snippets (context) is known as a prompt. The LLM will use this information to generate your answer. This may seem like a silly thing to do - if you already know the answer (the snippets), why bother with the LLM? Well - remember - this is happening in real-time and the goal is generated text - something you can copy and paste into your research. You need the LLM to create the text that incorporates the information from your custom corpus.
This is more complicated than fine-tuning. You may have heard about vector databases - they are a key component when looking for the best context for a question. Setting up vector databases can be tricky. If you need a simple interim solution, you could use a text search tool like Elastic Search. However, vector databases are better because they can learn the semantic meaning of words and pull in a context that uses different words with the same or similar meaning.
Disadvantages
- Requires a vector database.
- Longer time to value as compared to fine-tuning. (Due to the vector database and the pre-processing needed before sending a request to the LLM.)
Advantages
- The LLM has direct knowledge from your custom corpus.
- Explainability is possible.
- No fine-tuning is needed.
- Hallucinations are significantly reduced and can be controlled by examining the results from the vector database queries.
Summary
The successful implementation of generative AI is within reach of any enterprise willing to plan appropriately.
Like all things AI - generative AI starts with data. The data needed by the Large Language Models that power generative AI is the custom corpus that defines the unique knowledge within your firewalls. Don’t limit yourself to text-based documents. Training videos, recorded meetings, and recorded events in both audio and video format can be used. Building a data pipeline will not be easy, care must be taken to preserve security and licensing while at the same time ensuring quality.
Open-source models take the complexity out of designing models and since most are pretrained, they also remove the high cost of initial training. Organizations should experiment with fine-tuning to see if it improves the quality of the generated content.
Finally, retrieval augmented generation (RAG) is a powerful technique that can be used to combine the knowledge in your organization's custom corpus of documents with the parametric knowledge of an LLM. Unlike fine-tuning, the information from your corpus is not trained into the parametric parameters of the model. Rather, relevant snippets are located at inference time and passed to the model as context.
Next Steps
Generative AI is a new technology and new technologies require infrastructure updates. For organizations serious about generative AI, the next step is to create a system architecture that includes an AI/ML Pipeline, a Data Pipeline, a Modern Data Lake and a Vector database (if RAG is going to be utilized). In this post, I covered these technologies at a high level.
Stay tuned to this blog for a more detailed explanation of Generative AI System Architecture. If you have any questions, ping us on hello@min.io or join the Slack community.